
학습내용
-
Hello World 예제 프로그램 살펴보기
-
Name Gender 예제 프로그램 포팅
-
Yahoo Finance DAG 작성
1. Hello World 예제 프로그램 살펴보기
-
Python Operator
from airflow.operators.python import PythonOperator load_nps = PythonOperator( dag = dag, task_id = "task_id", python_callable = python_func, params = { "table": "delighted_nps", "schema": "raw_data" } ) # 태스크 실행 시 호출할 Python 함수 def python_func(**cxt): table = cxt["params"]["table"] schema = cxt["params"]["schema"] ex_date = cxt["execution_date"]
-
2개의 태스크로 구성된 데이터 파이프라인(DAG)
-
print_hello: PythonOperator로 구성되었으며, 먼저 실행
-
print_goodbye: PythonOperator로 구성되었으며, 두 번째로 실행
-
-
Airflow Decorators 사용하면 간단하게 프로그래밍 가능
from airflow.decorators import task @task def print_hello(): print("hello!") return "hello!" @task def print_goodbye(): print("goodbye!") return "goodbye!" with DAG( dag_id = "HelloWorld", startdate = datetime(2022, 5, 5), catchup = False, tags = ["example"], schedule = "0 2 * * *" ) as dag: # DAG에 순서대로 태스크 할당 print_hello() >> print_goodbye()
-
중요한 DAG 파라미터
-
max_active_runs: DAG 인스턴스의 최대 개수 지정
-
max_active_tasks: 병행 처리할 태스크의 최대 개수 지정
-
catchup: startdate부터 현재까지의 데이터를 채울지 여부 결정
-
default: True
-
Full Refresh인 경우에는 의미 X
-
-
태스크 파라미터와의 차이점을 잘 이해해야 함
-
2. Name Gender 예제 프로그램 포팅
-
Connections vs Variables
-
Connections
- DB 혹은 DW와 연결할 때 사용할 호스트 이름, 포트 번호 등의 민감한 정보를 저장해놓은 것
- DB 혹은 DW와 연결할 때 사용할 호스트 이름, 포트 번호 등의 민감한 정보를 저장해놓은 것
-
Variables
-
API key 혹은 설정 정보를 저장하기 위해 사용
-
이름에 "access" 혹은 "secret" 키워드 사용해 암호화 가능
-

-
-
Xcom
-
태스크(Operator)들 간 데이터를 주고받는 방식
- 보통 한 Operator의 반환값을 다른 Operator에서 읽어가는 형태
- 보통 한 Operator의 반환값을 다른 Operator에서 읽어가는 형태
-
이 값들은 Airflow 메타데이터 DB에 저장되기 때문에 큰 데이터는 사용 불가
- 보통 큰 데이터는 S3에 적재 후 위치 전달
- 보통 큰 데이터는 S3에 적재 후 위치 전달
-
task decorator로 대체 가능
-
-
DAG의 태스크 분리
-
태스크를 너무 많이 만들 경우, 전체 DAG 실행이 오래 걸리며, 스케줄러에 부하 발생
-
태스크를 너무 적게 만들 경우, 모듈화가 되지 않으며 재실행 시간이 오래 걸림
-
정답은 없지만, 실행이 오래 걸리는 DAG는 실패 시 재실행이 쉽도록 다수의 태스크로 적절히 나누는 것이 좋음
-
-
Airflow Variable 관리
-
장점: 코드를 Push할 필요 없음
-
단점: 관리나 테스트가 불가능해 사고로 이어질 가능성이 있음
-
중요한 기능의 경우, Variable보다 코드로 구현하는 것을 권장
-
3. Yahoo Finance DAG 작성
-
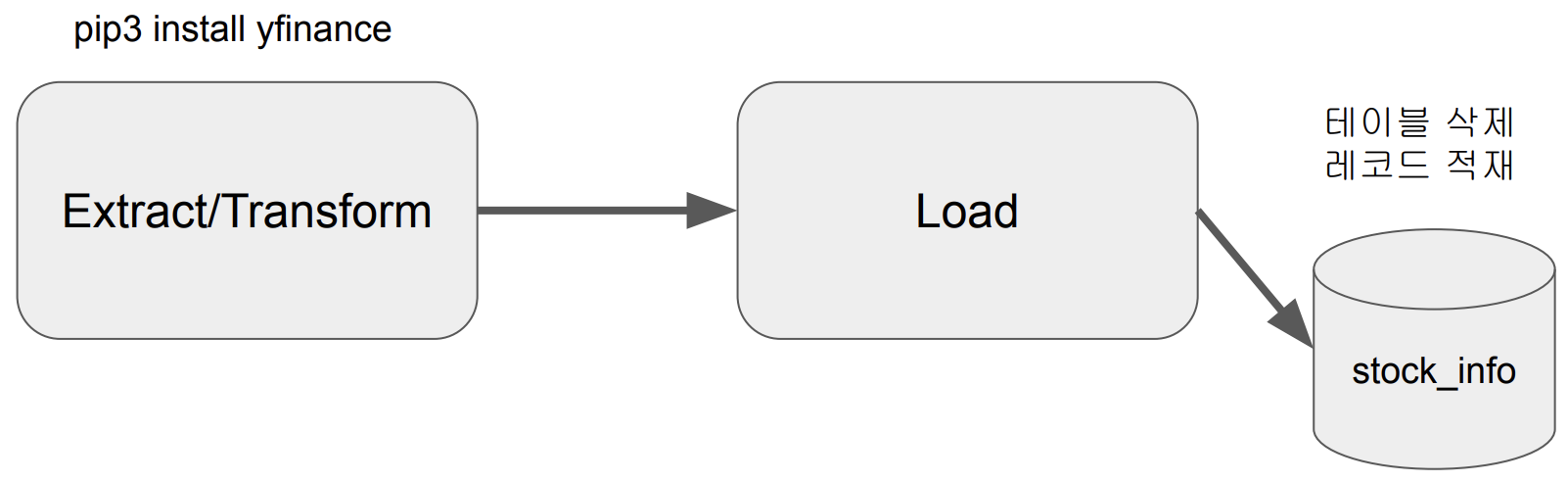
Yahoo Finance API를 호출해 지난 30일 간의 애플 주식 정보 수집
-
1에서 받은 레코드를 Redshift 테이블로 적재
-
Extract / Transform
import yfinance as yf @task def get_historical_prices(symbol): ticker = yf.Ticker(symbol) data = ticker.history() records = [] for index, row in data.iterrows(): date = index.strftime("%Y-%m-%d %H:%M:%S") records.append([date, row["Open"], , row["High"], row["Low"], row["Close"], row["Volume"]]) return records
-
Load(Full Refresh Version)
-
매번 테이블을 새로 생성
-
트랜잭션 형태로 구성
@task def load(schema, table, records): logging.info("load_started") cur = get_DB_connection() try: cur.execute("BEGIN;") cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};") cur.execute(f""" CREATE TABLE {schema}.{table} ( date date, "open" float, high float, low float, close float, vloume bigint );""") # FULL REFRESH for r in records: sql = f"INSERT INTO {schema}.{table} VALUES ('{r[0]}', {r[1]}, {r[2]}, {r[3]}, {r[4]}, {r[5]});" print(sql) cur.execute(sql) cur.execute("COMMIT;") except (Exception, psycopg2.DatabaseError) as error: print(error) cur.execute("ROLLBACK;") logging.info("load done")with DAG( dag_id = "UpdateSymbol", start_date = datetime(2023, 5, 30), catchup = False, tags = ["API"], schedule = "0 10 * * *" ) as dag: results = get_historical_prices("AAPL") load("schema_name", "stock_info", results)
-
-
Load(Incremental Update Version)
-
테이블을 삭제하는 것 대신, 레코드 적재 후 중복 제거
-
매일 하루치의 주식 정보 레코드가 적재
-
임시 테이블 사용
-
-
트랜잭션 형태로 구성
def _create_table(cur, schema, table, drop_first): if drop_first: cur.execute(f"DROP TABLE IF EXISTS {schema}.{table}") cur.execute(f"""CREATE TABLE IF NOT EXISTS {schema}.{table} ( date date, "open" float, high float, low float, close float, vloume bigint );""") @task def load(schema, table, records): cur = get_DB_connection() try: cur.execute("BEGIN;") # 원본 테이블 생성 _create_table(cur, schema, table, False) # 임시 테이블에 원본 테이블 복사 cur.execute(f"CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};") for r in records: sql = f"INSERT INTO t VALUES ('{r[0]}', {r[1]}, {r[2]}, {r[3]}, {r[4]}, {r[5]});" cur.execute(sql) # 비어있는 원본 테이블 생성 _create_table(cur, schema, table, True) # 임시 테이블 내용을 원본 테이블로 복사 cur.execute(f"INSERT INTO {schema}.{table} SELECT DISTINCT * FROM t;") cur.execute("COMMIT;") except (Exception, psycopg2.DatabaseError) as error: print(error) cur.execute("ROLLBACK;") -
메모
- airflow.cfg(airflow 환경 설정 파일)
-
DAGs 폴더는 어디에 지정되는가?
- 기본적으로는 airflow가 설치된 디렉토리 밑의 dags 폴더가 생성되며, dags_folder 키를 사용해 변경 가능
- 기본적으로는 airflow가 설치된 디렉토리 밑의 dags 폴더가 생성되며, dags_folder 키를 사용해 변경 가능
-
DAGs 폴더에 새로운 DAG를 만들면 Airflow 시스템에서 이를 언제 인식하는가? 또, 이 주기를 결정하는 키의 이름은 무엇인가?
- dag_dir_list_interval 키를 사용하며, default는 300초 즉, 5분
- dag_dir_list_interval 키를 사용하며, default는 300초 즉, 5분
-
이 파일에서 Airflow를 API 형태로 외부에서 조작하고 싶다면, 어떤 섹션을 변경해야 하는가?
- api 섹션의 auth_backend를 airflow.api.auth.backend.basic_auth로 변경
- api 섹션의 auth_backend를 airflow.api.auth.backend.basic_auth로 변경
-
Variable에서 변수값을 암호화하려면 변수명에 어떤 단어가 들어가야하는가?
- password, secret, passwd, authorization, api_key, apikey, access_token
- password, secret, passwd, authorization, api_key, apikey, access_token
-
이 환경 설정 파일이 수정되었다면 이를 실제로 반영하기 위해 해야하는 일은 무엇인가?
-
sudo systemctl restart airflow-webserver
-
sudo systemctl restart airflow-scheduler
-
-
메타데이터 DB의 내용을 암호화하는데 사용하는 키는 무엇인가?
- fernet_key
-
