CPU Scheduling
CPU scheduling
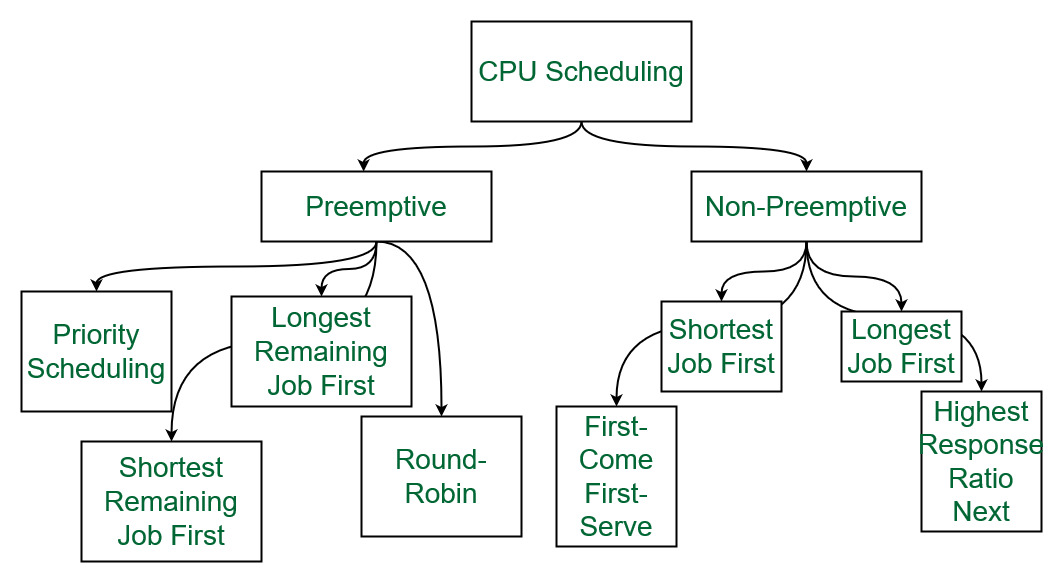
- 운영체제가 CPU의 자원을 어떤 프로세스에게 할당해 줄 것인지에 대한 것
Preemptive Scheduling
In Preemptive Scheduling, the tasks are mostly assigned with their priorities. Sometimes it is important to run a task with a higher priority before another lower priority task, even if the lower priority task is still running. The lower priority task holds for some time and resumes when the higher priority task finishes its execution.
Non-Preemptive Scheduling
In this type of scheduling method, the CPU has been allocated to a specific process. The process that keeps the CPU busy will release the CPU either by switching context or terminating. It is the only method that can be used for various hardware platforms. That’s because it doesn’t need special hardware (for example, a timer) like preemptive scheduling.
When scheduling is Preemptive or Non-Preemptive?
To determine if scheduling is preemptive or non-preemptive, consider these four parameters:
- A process switches from the running to the waiting state.
- Specific process switches from the running state to the ready state.
- Specific process switches from the waiting state to the ready state.
- Process finished its execution and terminated.
Only conditions 1 and 4 apply, the scheduling is called non- preemptive.
All other scheduling are preemptive.
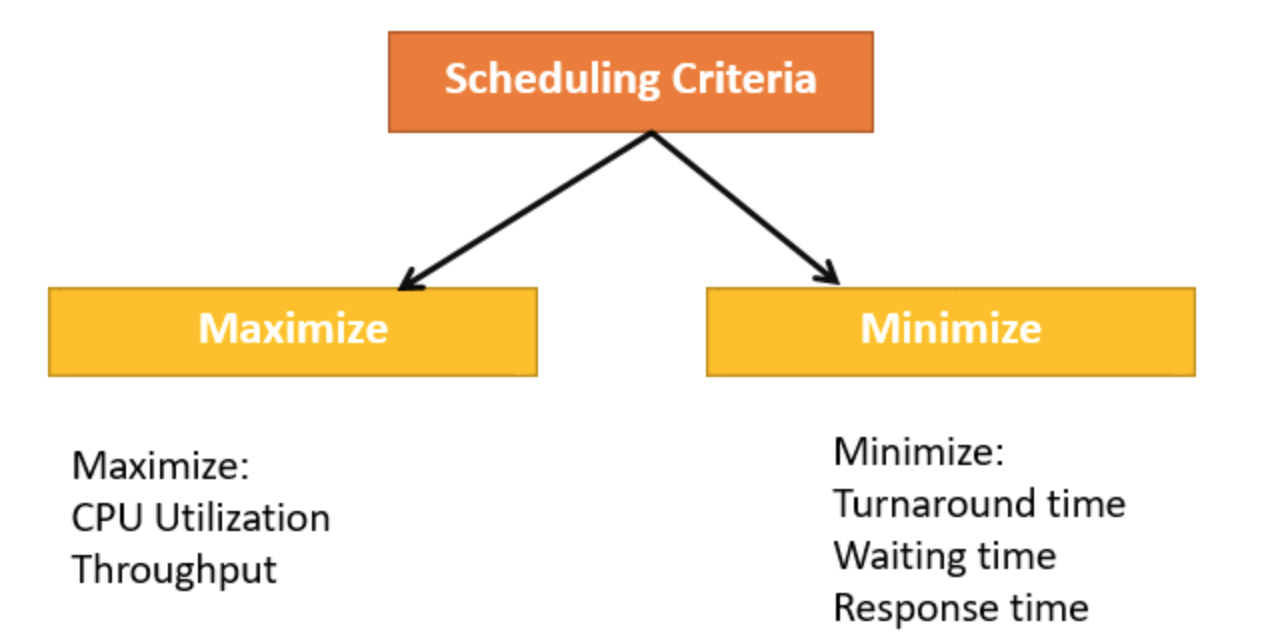
CPU Scheduling Criteria
-
CPU utilisation: The main objective of any CPU scheduling algorithm is to keep the CPU as busy as possible. Theoretically, CPU utilisation can range from 0 to 100 but in a real-time system, it varies from 40 to 90 percent depending on the load upon the system.
-
Throughput: A measure of the work done by the CPU is the number of processes being executed and completed per unit of time. This is called throughput. The throughput may vary depending upon the length or duration of the processes.
-
Turnaround time : For a particular process, an important criterion is how long it takes to execute that process. The time elapsed from the time of submission of a process to the time of completion is known as the turnaround time. Turn-around time is the sum of times spent waiting to get into memory, waiting in the ready queue, executing in CPU, and waiting for I/O. The formula to calculate Turn Around Time = Compilation Time – Arrival Time.
-
Waiting time: A scheduling algorithm does not affect the time required to complete the process once it starts execution. It only affects the waiting time of a process i.e. time spent by a process waiting in the ready queue. The formula for calculating Waiting Time = Turnaround Time – Burst Time.
-
Response time: In an interactive system, turn-around time is not the best criteria. A process may produce some output fairly early and continue computing new results while previous results are being output to the user. Thus another criteria is the time taken from submission of the process of request until the first response is produced. This measure is called response time. The formula to calculate Response Time = CPU Allocation Time(when the CPU was allocated for the first) – Arrival Time
What is a Dispatcher?
It is a module that provides control of the CPU to the process. The Dispatcher should be fast so that it can run on every context switch. Dispatch latency is the amount of time needed by the CPU scheduler to stop one process and start another.
Functions performed by Dispatcher:
- Context Switching
- Switching to user mode
- Moving to the correct location in the newly loaded program.
Scheduling Algorithms
Average waiting time
First Come First Serve Scheduling: It is the easy and simple CPU Scheduling Algorithm. In this algorithm, the process which requests the CPU first, gets the CPU first for execution. It can be implemented using FIFO (First-In, First-Out) Queue method.
Shortest Job First Scheduling:In this algorithm, the process with minimum Burst Time is selected for the executing next. It significantly reduces the average waiting time for the other waiting processes. It provides Non pre-emptive, Pre-emptive methods.
Priority Scheduling:This is the type of scheduling which is based on priorities, as name suggests. In this algorithm, process with highest priority is executed first. Same or equal priority processes are executed on RR or FCFS basis. Priority can be decided on various parameters like memory requirement, time requirement or any other criteria.
Round Robin Scheduling
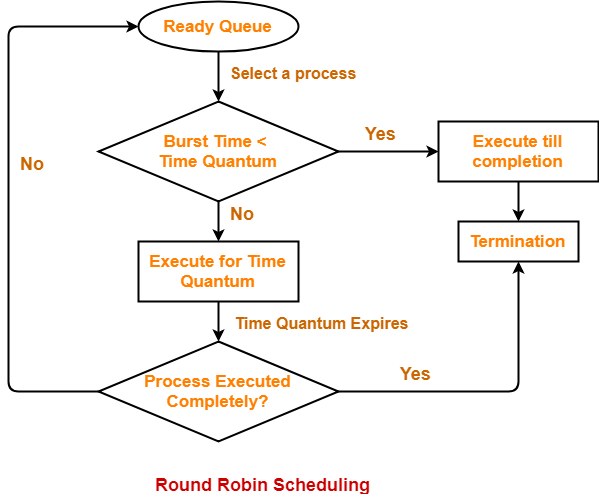
Round Robin Scheduling is also a simple scheduling algorithm. Like the Round-Robin principle, where each person gets equal share of something, here each process is given a fixed amount of time (called as quantum). This algorithm is mainly used in Multitasking.
Multiple Level Queue Scheduling
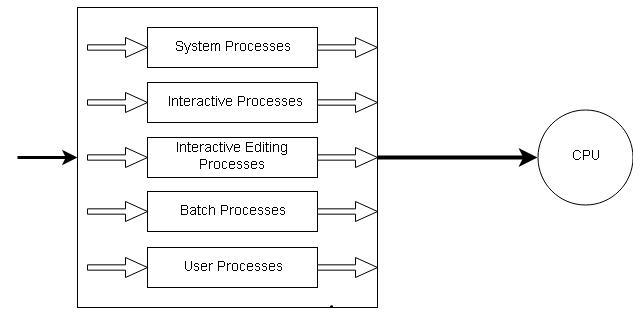
Each algorithm supports a different process, but in a general system, some processes require scheduling using a priority algorithm. While some processes want to stay in the system (interactive processes), others are background processes whose execution can be delayed.
The foreground (interactive) and background processes (batch process) are distinguished.
The foreground queue may be scheduled using a round-robin method, and the background queue can be scheduled using an FCFS strategy.
Advantages:You can use multilevel queue scheduling to apply different scheduling methods to distinct processes. It will have low overhead in terms of scheduling.
Disadvantages: There is a risk of starvation for lower priority processes. It is rigid in nature.
Multilevel Feedback Queue
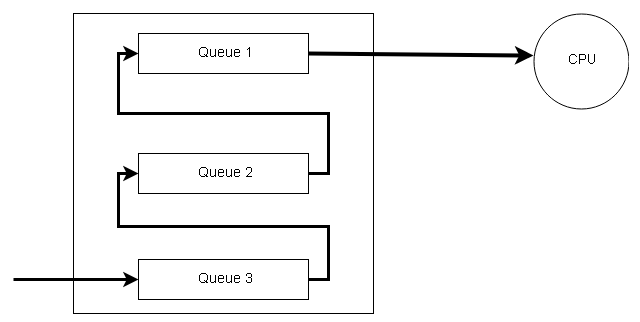
There is another version of the multilevel queue called the multilevel feedback queue which allows a process to move between queues. If the process uses too much of CPU time, it is moved to a lower-priority queue. If the process starts aging( waits too much in a lower-priority queue) is moved to a higher-priority queue. This prevents the process from starvation.
