
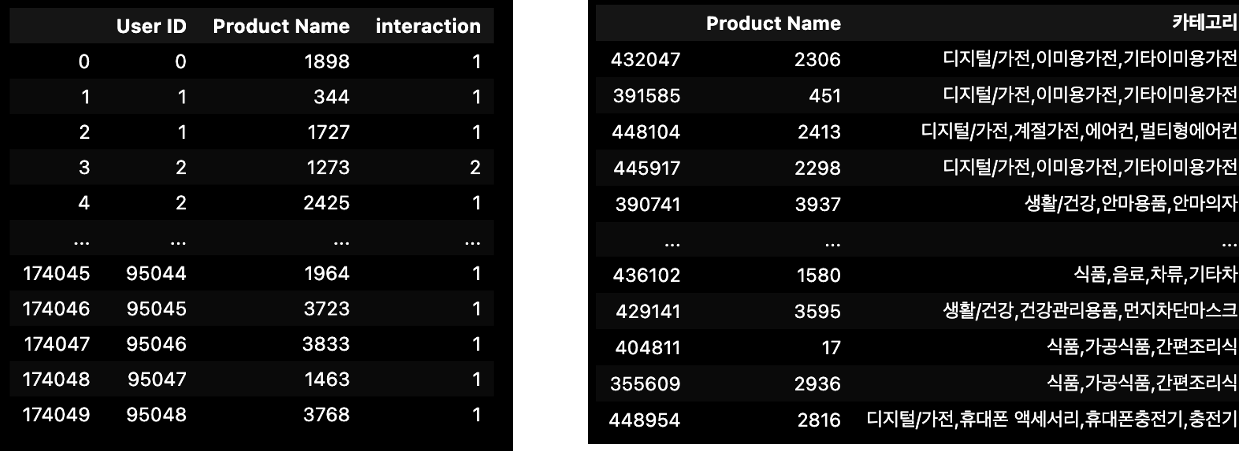
데이터 프레임
(우) Ratings
(좌) Items
인기 기반 구현
사용자 개인의 과거 행동이나 선호도를 고려하지 않고, 모든 사용자들에게 가장 인기 있는 아이템을 추천
- 단순성, 효율성
- 콜드 스타트 해결
- 개인화 부족
- 다양성 부족
# Popular Based / 인기 기반 구현
def weighted_rating(v,m,R,C):
'''
Calculate the weighted rating
Args:
v -> average rating for each item (float)
m -> minimum votes required to be classified as popular (float)
R -> average rating for the item (pd.Series)
C -> average rating for the whole dataset (pd.Series)
Returns:
pd.Series
'''
return ( (v / (v + m)) * R) + ( (m / (v + m)) * C )
def assign_popular_based_score(rating_df, item_df, user_col, item_col, rating_col):
'''
Assigned popular based score based on the IMDB weighted average.
Args:
rating -> pd.DataFrame contains ['item_id', 'rating'] for each user.
Returns
popular_items -> pd.DataFrame contains item and IMDB weighted score.
'''
# pre processing
vote_count = (
rating_df
.groupby(item_col,as_index=False)
.agg( {user_col:'count', rating_col:'mean'} )
)
vote_count.columns = [item_col, 'vote_count', 'avg_rating']
# calcuate input parameters
C = np.mean(vote_count['avg_rating'])
m = np.percentile(vote_count['vote_count'], 70)
vote_count = vote_count[vote_count['vote_count'] >= m]
R = vote_count['avg_rating']
v = vote_count['vote_count']
vote_count['weighted_rating'] = weighted_rating(v,m,R,C)
# post processing
vote_count = vote_count.merge(item_df, on = [item_col], how = 'left')
popular_items = vote_count.loc[:,[item_col, '카테고리', 'vote_count', 'avg_rating', 'weighted_rating']]
return popular_items
# init constant
USER_COL = 'User ID'
ITEM_COL = 'Product Name'
RATING_COL = 'interaction'
# calcualte popularity based
pop_items = assign_popular_based_score(ratings, items, USER_COL, ITEM_COL, RATING_COL)
pop_items = pop_items.sort_values('weighted_rating', ascending = False)
pop_items.head()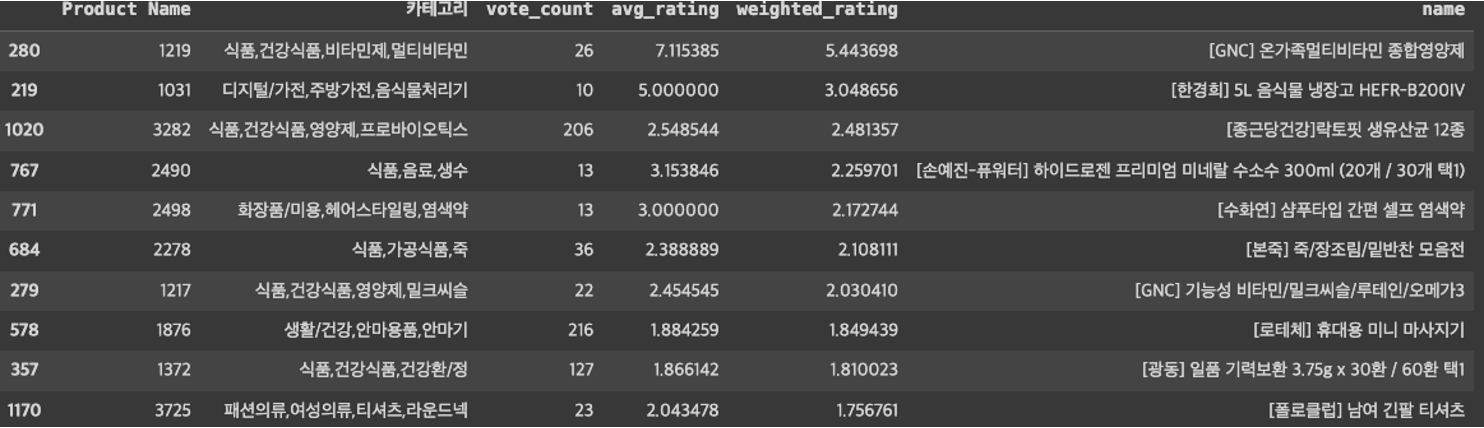
콘텐츠 기반 필터링
사용자가 과거에 선호했거나 상호작용했던 아이템의 내용(콘텐츠)을 분석하여, 유사한 아이템을 추천
아이템의 카테고리를 사용하여, 아아템간의 유사성을 계산하여 특정 아이템과 가장 유사한 아이템을 찾아냄
from sklearn.metrics.pairwise import cosine_similarity
import gc
def top_k_items(item_id, top_k, corr_mat, map_name):
# sort correlation value ascendingly and select top_k item_id
top_items = corr_mat[item_id,:].argsort()[-top_k:][::-1]
top_items = [map_name[e] for e in top_items]
return top_items
# preprocessing
rated_items = items.loc[items[ITEM_COL].isin(ratings[ITEM_COL])].copy()
# extract the genre
genre = rated_items['카테고리'].str.split(",", expand=True)
# get all possible genre
all_genre = set()
for c in genre.columns:
distinct_genre = genre[c].str.lower().str.strip().unique()
all_genre.update(distinct_genre)
all_genre.remove(None)
# create item-genre matrix
item_genre_mat = rated_items[[ITEM_COL, '카테고리']].copy()
item_genre_mat['카테고리'] = item_genre_mat['카테고리'].str.lower().str.strip()
# OHE the 카테고리 column
for genre in all_genre:
item_genre_mat[genre] = np.where(item_genre_mat['카테고리'].str.contains(genre), 1, 0)
item_genre_mat = item_genre_mat.drop(['카테고리'], axis=1)
item_genre_mat = item_genre_mat.set_index(ITEM_COL)
# compute similarity matix
corr_mat = cosine_similarity(item_genre_mat)
# get top-k similar items
ind2name = {ind:name for ind,name in enumerate(item_genre_mat.index)}
name2ind = {v:k for k,v in ind2name.items()}
similar_items = top_k_items(name2ind[1],
top_k = 10,
corr_mat = corr_mat,
map_name = ind2name)
# display result
print("The top-k similar movie to item_id 1")
display(items.loc[items[ITEM_COL].isin(similar_items)])
del corr_mat
gc.collect();
메모리 기반 추천 알고리즘
협업 필터링(collaborative filtering) 접근 방식의 일종으로, 사용자나 아이템 간의 유사성을 기반으로 추천. 사용자의 과거 상호작용(예: 평가, 구매, 조회) 데이터를 직접 사용하여 추천을 생성하며, 별도의 모델 학습 과정 없이 전체 데이터셋을 메모리에 저장하여 사용
아이템 기반으로 추천
from scipy.sparse import csr_matrix
# prompt: ratings에서 Userid 갯수가 몇 개야?
NUM_USERS = ratings['User ID'].nunique()
NUM_ITEMS = ratings['Product Name'].nunique()
# preprocess data
row = ratings[USER_COL]
col = ratings[ITEM_COL]
data = ratings[RATING_COL]
# init user-item matrix
mat = csr_matrix((data, (row, col)), shape=(NUM_USERS, NUM_ITEMS))
mat.eliminate_zeros()
# calculate sparsity
sparsity = float(len(mat.nonzero()[0]))
sparsity /= (mat.shape[0] * mat.shape[1])
sparsity *= 100
print(f'Sparsity: {sparsity:4.2f}%. This means that {sparsity:4.2f}% of the user-item ratings have a value.')
# compute similarity
item_corr_mat = cosine_similarity(mat.T)
# get top k item
print("\nThe top-k similar movie to item_id 1")
similar_items = top_k_items(name2ind[1],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])

Matrix Factorization (MF) based (TruncatedSVD )
협업필터링의 일종으로, Latent factor model 중에서 가장 성능이 좋은 방법 중 하나
from sklearn.decomposition import TruncatedSVD
epsilon = 1e-9
n_latent_factors = 10
# calculate item latent matrix
item_svd = TruncatedSVD(n_components = n_latent_factors)
item_features = item_svd.fit_transform(mat.transpose()) + epsilon
# calculate user latent matrix
user_svd = TruncatedSVD(n_components = n_latent_factors)
user_features = user_svd.fit_transform(mat) + epsilon
# compute similarity
item_corr_mat = cosine_similarity(item_features)
# get top k item
print("\nThe top-k similar movie to item_id 1")
similar_items = top_k_items(name2ind[1],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del user_features
gc.collect();
Matrix Factorization (MF) based ( Funk MF)
from surprise import SVD, accuracy
from surprise import Dataset, Reader
from surprise.model_selection import cross_validate
from surprise.model_selection.split import train_test_split
def pred2dict(predictions, top_k=None):
rec_dict = defaultdict(list)
for user_id, item_id, actual_rating, pred_rating, _ in predictions:
rec_dict[user_id].append((item_id, pred_rating))
return rec_dict
def get_top_k_recommendation(rec_dict, user_id, top_k, ind2name):
pred_ratings = rec_dict[user_id]
# sort descendingly by pred_rating
pred_ratings = sorted(pred_ratings, key=lambda x: x[1], reverse=True)
pred_ratings = pred_ratings[:top_k]
recs = [ind2name[e[0]] for e in pred_ratings]
return recs
# prepare train and test sets
reader = Reader(rating_scale=(1,10))
data = Dataset.load_from_df(ratings, reader)
train, test = train_test_split(data, test_size=.2, random_state=42)
# init and fit the funk mf model
algo = SVD(random_state = 42)
algo.fit(train)
pred = algo.test(test);
# evaluation the test set
accuracy.rmse(pred)
# extract the item features from algo
item_corr_mat = cosine_similarity(algo.qi)
print("\nThe top-k similar movie to item_id 1")
similar_items = top_k_items(name2ind[1],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del item_corr_mat
gc.collect();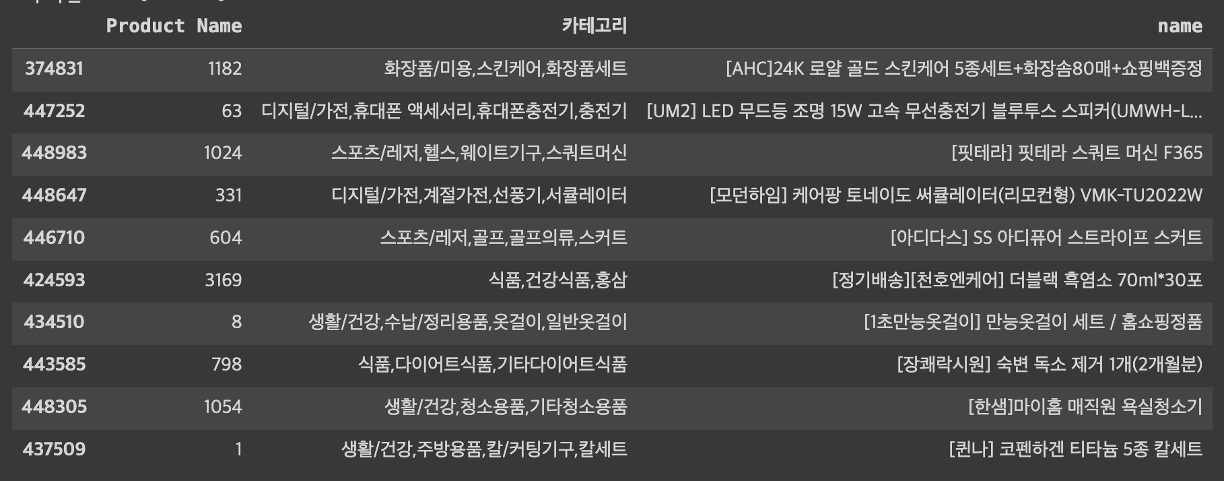
Generalized Matrix Factorization (Keras)
행렬분해 모델을 사용한 딥러닝을 활용한 추천서비스 설계
from IPython.display import clear_output
import tensorflow as tf
import tensorflow_recommenders as tfrs
import tensorflow.keras as keras
from sklearn.model_selection import train_test_split
from typing import Dict, Text, Tuple
def df_to_ds(df):
df['user_id'] = df['user_id'].astype(str) # user_id를 문자열로 변환
df['item_id'] = df['item_id'].astype(str) # item_id를 문자열로 변환
# convert pd.DataFrame to tf.data.Dataset
ds = tf.data.Dataset.from_tensor_slices(
(dict(df[['user_id','item_id']]), df['rating']))
# convert Tuple[Dict[Text, tf.Tensor], tf.Tensor] to Dict[Text, tf.Tensor]
ds = ds.map(lambda x, y: {
'user_id' : x['user_id'],
'item_id' : x['item_id'],
'rating' : y
})
return ds.batch(256)
class RankingModel(keras.Model):
def __init__(self, user_id, item_id, embedding_size):
super().__init__()
# user model
input = keras.Input(shape=(), dtype=tf.string)
x = keras.layers.StringLookup(
vocabulary = user_id, mask_token = None
)(input)
output = keras.layers.Embedding(
input_dim = len(user_id) + 1,
output_dim = embedding_size,
name = 'embedding'
)(x)
self.user_model = keras.Model(inputs = input,
outputs = output,
name = 'user_model')
# item model
input = keras.Input(shape=(), dtype=tf.string)
x = keras.layers.StringLookup(
vocabulary = item_id, mask_token = None
)(input)
output = keras.layers.Embedding(
input_dim = len(item_id) + 1,
output_dim = embedding_size,
name = 'embedding'
)(x)
self.item_model = keras.Model(inputs = input,
outputs = output,
name = 'item_model')
# rating model
user_input = keras.Input(shape=(embedding_size,), name='user_emb')
item_input = keras.Input(shape=(embedding_size,), name='item_emb')
x = keras.layers.Concatenate(axis=1)([user_input, item_input])
x = keras.layers.Dense(256, activation = 'relu')(x)
x = keras.layers.Dense(64, activation = 'relu')(x)
output = keras.layers.Dense(1)(x)
self.rating_model = keras.Model(
inputs = {
'user_id' : user_input,
'item_id' : item_input
},
outputs = output,
name = 'rating_model'
)
def call(self, inputs: Dict[Text, tf.Tensor]) -> tf.Tensor:
user_emb = self.user_model(inputs['user_id'])
item_emb = self.item_model(inputs['item_id'])
prediction = self.rating_model({
'user_id' : user_emb,
'item_id' : item_emb
})
return prediction
class GMFModel(tfrs.models.Model):
def __init__(self, user_id, item_id, embedding_size):
super().__init__()
self.ranking_model = RankingModel(user_id, item_id, embedding_size)
self.task = tfrs.tasks.Ranking(
loss = keras.losses.MeanSquaredError(),
metrics = [keras.metrics.RootMeanSquaredError()]
)
def call(self, features: Dict[Text, tf.Tensor]) -> tf.Tensor:
return self.ranking_model(
{
'user_id' : features['user_id'],
'item_id' : features['item_id']
})
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
return self.task(labels = features.pop('rating'),
predictions = self.ranking_model(features))
# preprocess
train, test = train_test_split(df, train_size = .8, random_state=42)
train, test = df_to_ds(train), df_to_ds(test)
user_id = np.arange(start = 0, stop = NUM_USERS).astype(str) # 문자열로 변환
item_id = np.arange(start = 0, stop = NUM_ITEMS).astype(str) # 문자열로 변환
# # init model
embedding_size = 64
model = GMFModel(user_id,
item_id,
embedding_size)
model.compile(
optimizer = keras.optimizers.Adagrad(learning_rate = .01)
)
# # fitting the model
model.fit(train, epochs=3, verbose=0)
# evaluate with the test data
result = model.evaluate(test, return_dict=True, verbose=0)
print("\nEvaluation on the test set:")
display(result)
# extract item embedding
item_emb = model.ranking_model.item_model.layers[-1].get_weights()[0]
item_corr_mat = cosine_similarity(item_emb)
print("\nThe top-k similar movie to item_id 1")
similar_items = top_k_items(name2ind[1],
top_k = 10,
corr_mat = item_corr_mat,
map_name = ind2name)
display(items.loc[items[ITEM_COL].isin(similar_items)])
del item_corr_mat
gc.collect();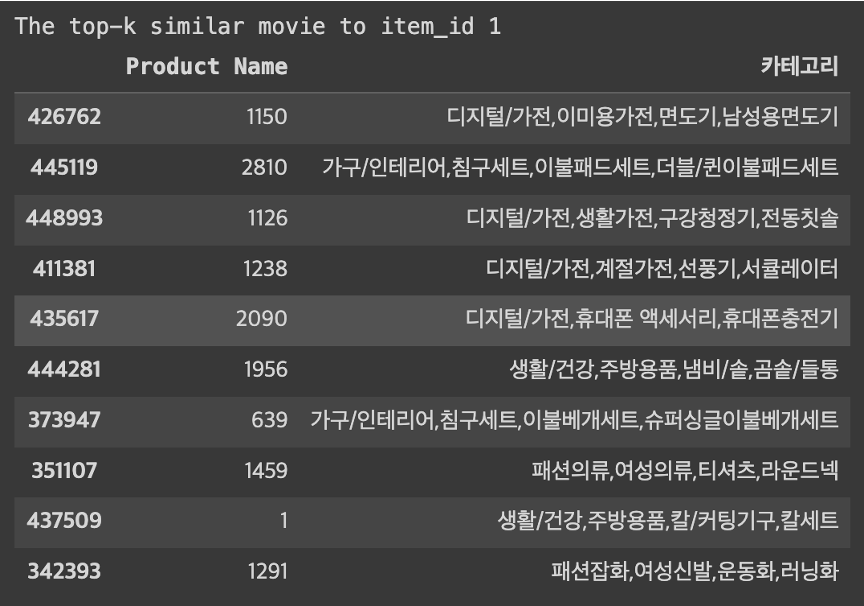

The ones who are crazy enough to think that they can change the world are the ones who do."(steven Jobs, 2015). 세상을 바꾸는 '미친' 아이디어를 찾아내 세상을 바꾸고자 하는 AI 연구자입니다.