-
What you should know from this chapter
Alternative (physical) algorithms for selection, projection, join, set, and aggregation & grouping (logical) operations in SQL?
Effect of buffering: how the size and replacement policy of buffer can affect the evaluation of the operations? -
Algorithms
Indexing : (selections, joins)
Iteration: Sometimes, faster to scan all tuples even if there is an index.
Partitioning: By using sorting or hashing -
Selection
1) No index, no sorted: full table scan
2) No index, sorted: binary search + scan
3) B+ tree index
4) Hash index & equality -
Using an Index for Selections
Cost depends on # of qualifying tuples, and clustering
Important refinement for unclustered indexes: RID Sorting (같은 페이지의 여러번 방문을 한 번만) -
General Selection: Two Approaches
$ SELECT *
$ FROM TEST
$ WHERE a = 1 and b = 1 and c = 1
First approach:
Find the most selective access path, retrieve tuples using it, and apply any remaining terms that don’t match the index
Second approach
RID Intersection: if we have 2 or more matching indexes that use Alternatives (2) or (3) for data entries -
Projection
$ SELECT DISTINCT R.sid, R.bid
$ FROM Reserves
Sorting Approach: Sort on <sid, bid> and remove duplicates. (Can optimize this by dropping unwanted information while sorting.)
Hashing Approach: Hash on <sid, bid> to create partitions. Load partitions into memory one at a time, build in-memory hash structure, and eliminate duplicates.
cf) If there is an index with both R.sid and R.bid in the search key, may be cheaper to sort data entries! -
Join
M pages in R, p_R tuples per page, N pages in S, p_S tuples per page. -
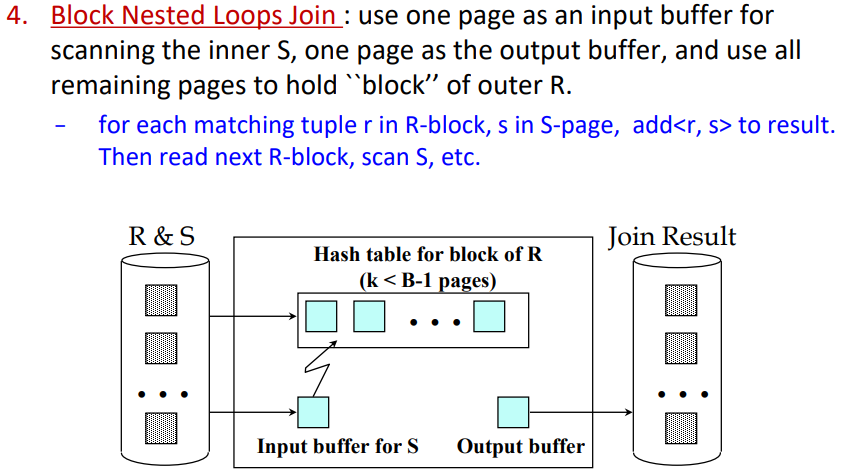
Nested Loops Join


-
Join: SORT-MERGE vs. HASH
In nested loop join, all the data blocks resides in buffer cache -
Sort-Merge Join
Cost: M log M + N log N + (M+N)
The cost of scanning, M+N, could be M*N (very unlikely!) -
Grace Hash-Join
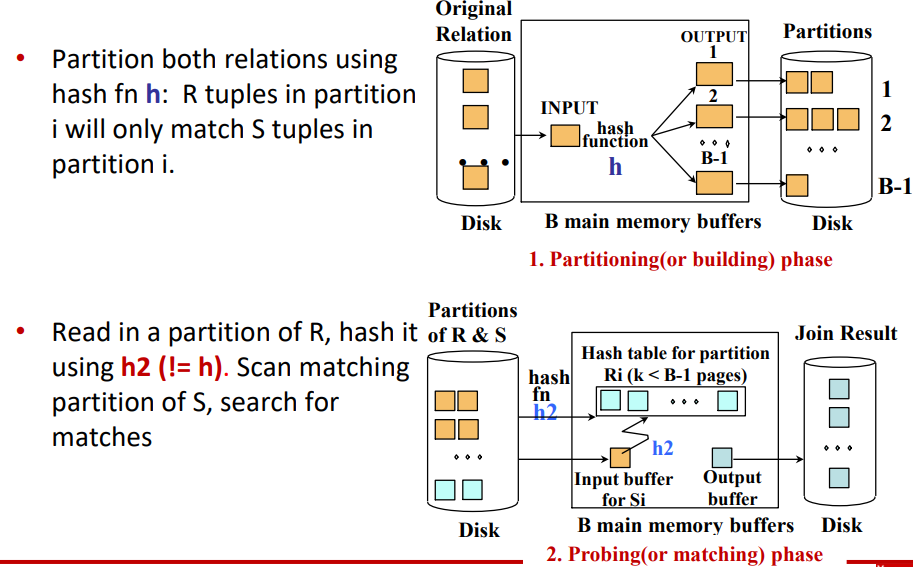
Cost of hash-join = 3(M+N) -
Inequality conditions (e.g., R.rname < S.sname)
For Index NL, need (clustered!) B+ tree index.
Hash Join, Sort Merge Join not applicable
Block NL quite likely to be the best join method here -
Impact of Buffering

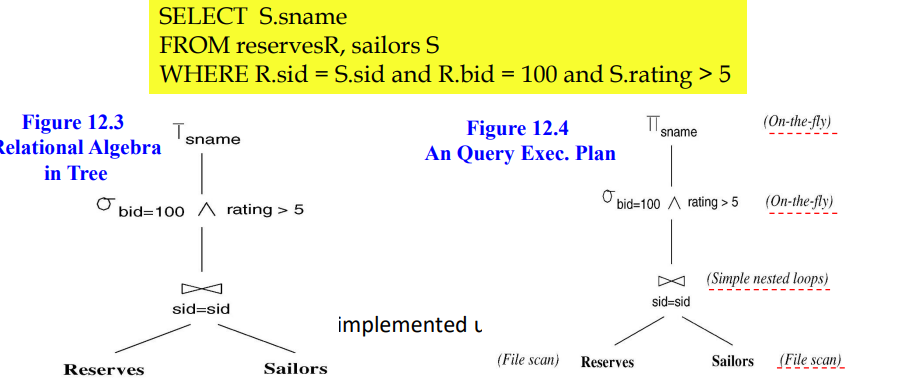
Query Evaluation
-
Parsing
hard : 새로운 쿼리, soft : 참고할 수 있는 쿼리 -
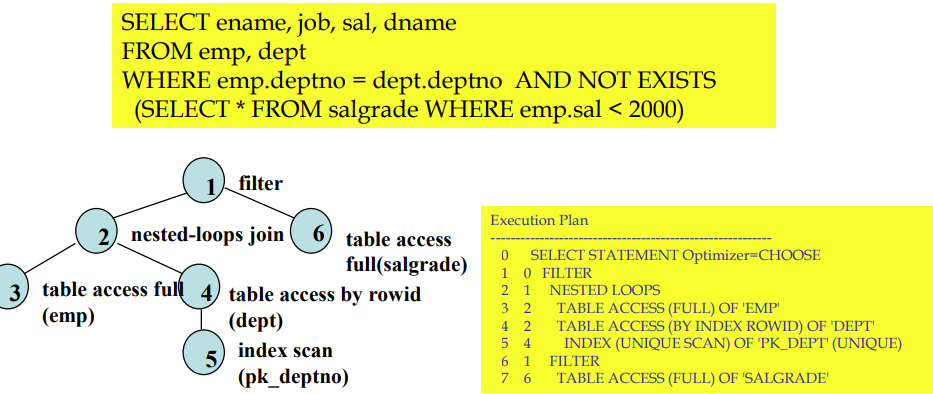
Query Execution Plan
-
Row source model in Oracle