
저번 글에서 Thread에 대해 이야기 하면서 여러 Issue들을 다루었다.
race condition, critical section, indeterminate, mutual exclusion이 있었다.
4가지 개념이 무엇인지 생각하면서 보면 더 이해하기 쉬울 것 같다.
1. Concurrency가 문제
1. Sharing Resources
-
Local variable의 경우 스택에 저장된다. 각 스레드는 자신의 스택 공간을 가지기 때문에 스레드간에 공유되지 않는다.
-
Global variables은 static data 세그먼트에 저장되며, 어느 스레드도 접근이 가능하다. (앞의 글에서 thread간에 address space를 공유한다고 하였다.)
-
동적인 객체 또한 스레드간에 공유된다. heap에 저장되므로 마찬가지 이유로 스레드간에 공유 될 수 있다.
이제 local variable은 신경쓰지 않고, 공유되는 자원만 생각하자.
2. Synchronization Problem
공유 되는 자원에 대한 Concurrency가 non-deterministic한 결과를 이끈다.
즉, 두 개 이상의 동시에 공유된 자원에 접근하는 스레드들은 race condition을 만든다.
따라서 공유 자원 접근에 대해 동기화(Synchronization) 메카니즘이 필요하다. (스케줄링은 프로그래머의 제어에 있지 않기 때문에 동기화 메카니즘이 필요)
동기화는 concurrency를 제한하여 수행된다.
3. Critical Section
critical section은 공유 자원에 대한 접근을 하는 코드의 부분을 말한다.

critical section에 대해서는 mutual exclusion이 필요하다. mutual exclusion은 다음 조건을 만족한다.
1. critical section을 원자적으로 수행한다. (모두 수행하거나 아예 하지 않거나)
2. 한번에 오직 하나의 스레드가 critical section에서 실행한다.
3. 모든 다른 스레드들은 진입을 기다려야 한다.
4. 한 스레드가 critical section을 나갈때, 다른 스레드가 들어갈 수 있다.
2. Locks
1. Lock에 대한 기본적인 아이디어
어떤 critical section은 마치 하나의 원자적인 instruction처럼 수행되는 것을 보장해야 한다.
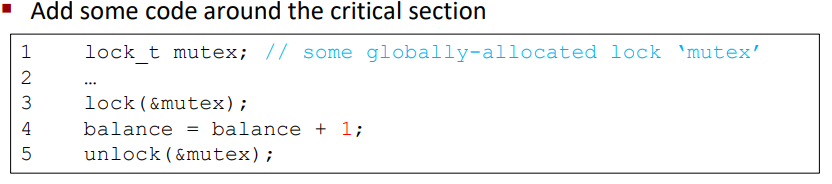 Lock 변수는 lock의 상태를 가진다.
Lock 변수는 lock의 상태를 가진다.
available(or unlocked or free) => lock을 쥔 스레드가 없다
acquired(or locked or hold) => 정확히 하나의 스레드가 lock을 가지고 있고, critical section에 진입해있을 것이다.
2. lock()의 의미
lock()
1. lock을 얻으려고 시도 한다.
2. 만약 다른 스레드가 lock을 가지고 있지 않으면, 해당 스레드는 lock을 얻는다.
3. critical section에 진입한다.
4. 해당 스레드가 lock을 가지고 있는 한 다른 스레드들은 이 critical section에 진입하는 것이 제한된다.
unlock()
1. 일단 lock의 주인이 unlock()을 호출하면, lock은 다시 이용가능해진다.
2. lock()에서 기다리고 있는 스레드를 깨운다.
lock의 사용을 정리하면
1. Lock은 초기에 free 상태이다
2. critical section에 진입하기전 lock()을 호출하고, 빠져나올 때 unlock()을 호출한다.
3. lock()을 호출한 caller가 lock을 쥘 때까지 return 하지 않는다.
4. unlock()까지, 스레드는 spin(spinlock)하거나 block(mutex)할 수 있다. (뒤에서 다룸)
5. 최소 한번에 한 스레드는 lock을 잡을 수 있다.

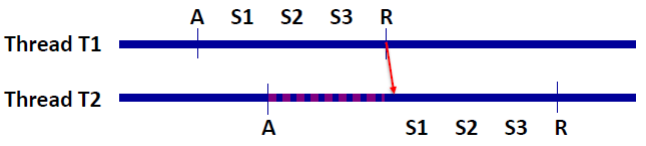
위 그림은 T1이 lock을 걸고 critical section을 수행하는 중에 T2가 lock을 시도하는 상황이다. T2는 T1이 unlock()을 호출 할 때까지 반복적으로 lock 변수를 확인한다.
3. Locks의 요구조건
Correctness
- Mutual exclusion: 한 번에 오직 하나의 스레드만 critical section에 진입한다.
- Progress(deadlock-free): 만약 여러 스레드가 critical section에 진입하기를 원하면, 반드시 하나는 critical section에 진입해야 한다. 즉, deadlock에 걸려 모두 진입하지 못하면 안된다.
- Bounded waiting(starvation-free): 반드시 기다리는 스레드는 결국에는 진입을 해야한다. 즉, starvation이 생기면 안된다.
Fairness
- 각 스레드는 lock을 얻는데 공평한 기회가 있어야 한다.
Performance
- contentions의 유무와 관계없이 lock에 대한 time overhead가 적어야 한다.
3. Locks의 구현 방법
Locks의 구현 방법에는 크게 3가지로 나눌 수 있다.
1. Controlling interrupts
첫 번째 방법으로 critical section에 진입하면 interrupt를 disable 시키는 방법이다.
- mutual exclusion을 제공하는 초기에 사용된 방법 중 하나
- single-processor systems에서만 사용이 가능하다 (다른 core의 thread는 접근이 가능함)
- interrupt를 disable 시키는 것은 context switch를 유발할 수 있는 외부 이벤트를 막는다.
- critical section 내부에서는 interrupted 되지 않는다.
- lock에 관련한 상태를 저장하는 코드가 없다.

특징
- 간단하다.
- single-processor system에서는 유용하다.
문제점
- application에 많은 신뢰가 필요하다. 무슨말이냐면, Greedy program은 lock을 걸어놓고 계속 사용할 수 있다.
- multiprocessors에서는 작동하지 않는다.
현재는 사용되지 않음.
2. Software-only algorithms
 위 코드는 thread 2개에 대한 spinlock을 구현한 것이다. 위 코드는 flag[self] = 1 이후에 context switch가 일어날 경우 Dead Lock이 발생한다.
위 코드는 thread 2개에 대한 spinlock을 구현한 것이다. 위 코드는 flag[self] = 1 이후에 context switch가 일어날 경우 Dead Lock이 발생한다.
이에 대한 해결책으로 Peterson's Algorithm이 있다.

추가적으로 turn 변수를 사용하여, 두 프로세스간에 critical section(mutual exclusion) 문제를 해결한다.
software-only algorithms은 다음과 같은 문제가 있다.

첫 번째로 아래 그림과 같이 mutual exclusion이 보장되지 않는다.

두 번째로는 lock함수 내부 코드를 보면 flag = 1이면 spin-wait을 한다. 이 때 CPU는 아무것도 안하고 소모되게 되므로 비효율적이다. 즉, 다른 스레드가 critical section을 빠져나오길 기다리면서 시간을 낭비하게 된다.
따라서 우리는 Hardware에 의해 지원되는 atomic instruction이 필요하다. (mutual exclusion 문제 해결)
3. Hardware atomic instructions
1. Test And Set(Atomic Exchange)
Test And Set은 Hardware에서 MOVE나 ADD Instruction처럼 원자적인 instruction과 같이 지원한다.

- ptr이 가리키는 old value를 return한다.
- 동시에 ptr이 가리키는 값을 new value로 업데이트 한다.
위 두 연산이 원자적으로 수행된다. 즉, test와 set이 동시에 수행된다.

여전히 spin lock을 사용한다. 위 구현이 single processor에서 옳바르게 동작하기 위해서는 preemptive scheduler가 필요하다. (Loop에서 CPU를 뺏어야 함)
2. Compare-And-Swap
- ptr에 값이 expected와 동일한지 test한다.
- 동일하면, ptr이 가리키는 값을 new의 값으로 update한다.
동일하지 않으면, 현재 ptr이 가리키는 값을 return 한다.
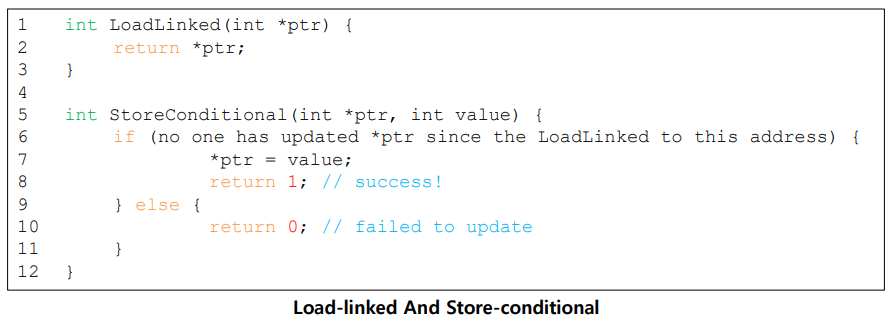
3. Load-Linked and Store-Conditional

성공시 1을 반환하고 ptr을 value로 값을 update한다.
실패시 ptr은 update 되지않고, 0을 반환한다.
4. Fetch-And-Add
특정 주소에 저장된 old value를 리턴하는 동안 해당 값을 계속 증가시킨다.

Ticket Lock
Ticket Lock은 fetch-and-add로 구성된다.
- 첫 번째로 티켓을 얻고 자신의 차례까지 기다린다.
- 모든 스레드에 대해 턴이 보장된다. => fairness
처음 lock()을 수행하면 FetchAndAdd를 ticket에 대해 수행하여 번호표를 부여받아 myturn에 저장한다. 이후 unlock()을 보면 FetchAndAdd를 turn에 대해 수행하는 것을 볼 수 있다. turn의 값을 1증가시켜 다음 thread의 turn이 되도록 한다.
4. Spin Locks에 대한 평가
-
Correctrness: yes
spin lock은 오직 하나의 스레드가 critical section에 진입하도록 한다. (mutual exclusion) -
Fairness: no
spin lock은 fairness를 보장하지 않는다. 즉, spinning 하는 thread는 영원히 spin할 수 있다. -
Performance:
-
single CPU에서, performance overhead가 매우 좋지 않다. => timer interrupt까지 대기해야 한다. 예를 들어, T0가 context switch 직전에 lock을 걸고 끝난다면 다음 critical section을 수행하는 스레드 T1은 time slice만큼 loop를 돌며 기다리게 된다.
-
만약 CPUs의 수가 threads의 수와 대략적으로 비슷하다면, spin locks은 꽤 합리적으로 동작한다고 한다.
-
여기까지 Hardware-based spin locks을 살펴보았다.
Hardware-based spin locks은 간단하고 잘 작동하지만, 몇 케이스에서 이러한 solution은 꽤나 비효율적이다. => thread가 spinning하는 시간동안, 전체 time slice를 아무것도 하지 않고 값을 checking하는데 소비한다.
다음 포스팅에서는 OS의 도움을 받아 Spinning을 피하는 방법에 대해 알아보겠습니다.
