1. 자료구조의 정의와 중요성
"자료구조"는 데이터를 저장하고, 효율적으로 관리 및 활용할 수 있도록 구조화하는 방법을 뜻합니다.
-> 데이터를 잘 조직화하면 데이터 처리의 속도와 효율성이 크게 향상됩니다. 이는 프로그램의 성능을 좌우할 수 있기 때문에, 자료구조는 코딩과 소프트웨어 개발에서 매우 중요한 역할을 합니다.
각각의 자료구조에는 장단점이 있으므로 어떤 자료구조가 최선일지는 해결하고자 하는 문제의 종류와 어떤 부분을 우선적으로 최적화할지에 따라 달라질 수 있습니다.
프로그래밍이란 결국 알고리즘을 작성하고, 그에 맞는 자료구조를 선택하는 것이며,
파스칼을 개발한 스위스의 컴퓨터 과학자 니클라우스 비르트는 ‘알고리즘 + 자료구조 = 프로그램’이라는 유명한 말을 남기기도 했습니다.
2. 자료구조와 알고리즘의 관계
자료구조와 알고리즘은 서로 밀접한 관계를 가집니다.
(1) 자료구조는 데이터를 저장하고 조직하는 방법이고,
(2) 알고리즘은 그 데이터를 다루고 처리하는 방법입니다.
=> 즉, 자료구조가 데이터를 저장하는 틀이라면, 알고리즘은 이 틀 안에서 데이터를 효율적으로 처리하기 위한 절차입니다.
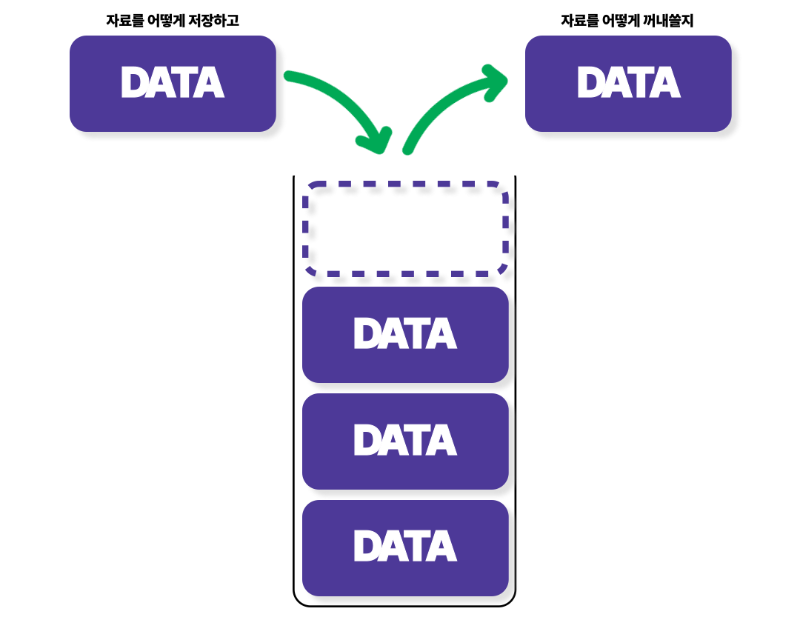
예를 들어, 정렬 알고리즘은 데이터를 정렬하는 방법이고, 이때 자료구조는 배열이나 연결 리스트와 같은 형태로 데이터를 저장하는 방법이 됩니다. 자료구조를 잘 이해하고 있어야 적절한 알고리즘을 선택할 수 있으며, 반대로 문제에 맞는 알고리즘을 구현하기 위해서는 자료구조에 대한 이해가 필수입니다.
알고리즘은 컴퓨터가 무슨 일을 해야 할지 지시하고, 자료구조는 컴퓨터에게 알고리즘에서 사용하는 자료를 어떻게 저장할지 지시합니다.
3. 자료구조의 종류와 특징
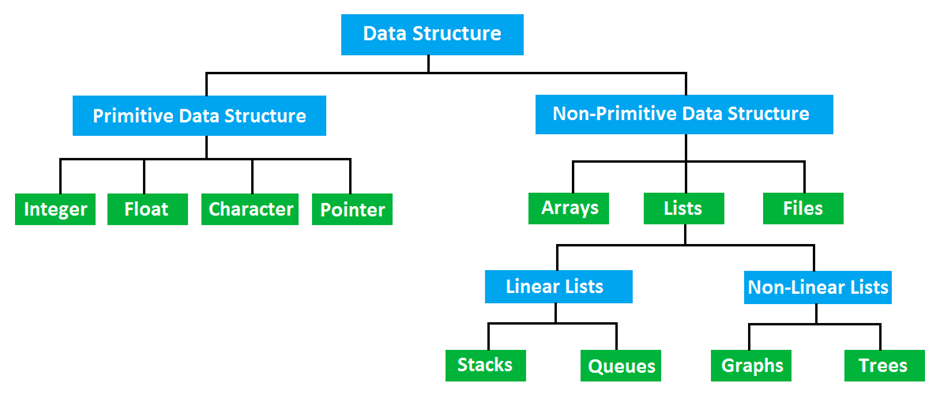
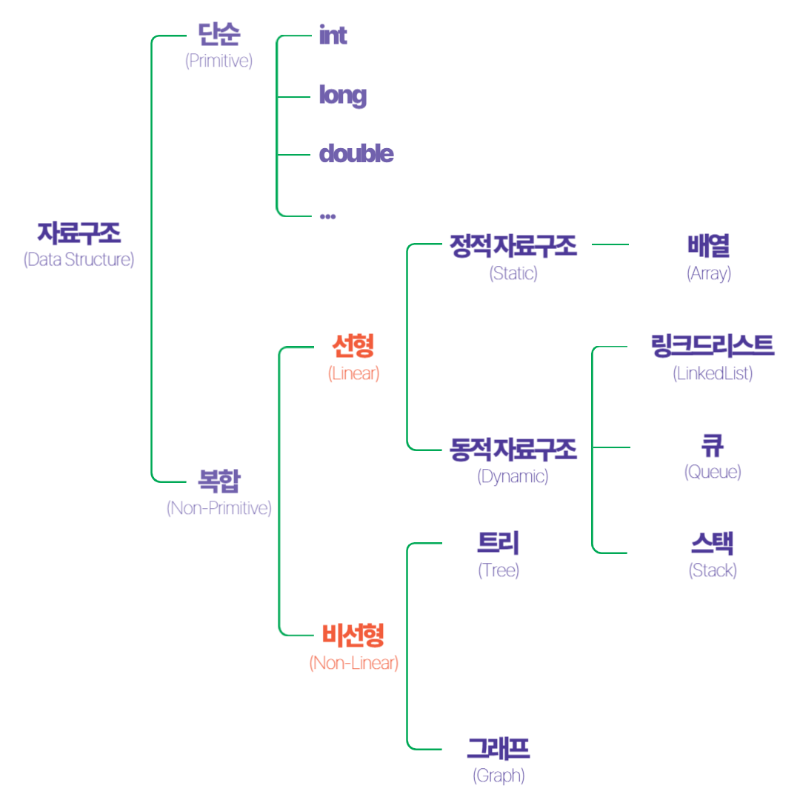
자료구조는 크게 선형 구조와 비선형 구조로 나눌 수 있습니다.
1. 선형 구조 (Linear Data Structures)
o 데이터가 일렬로 배치된 구조로, 각 데이터가 차례로 연결되어 있습니다.
o 종류:
배열 (Array): 고정된 크기의 메모리에 연속적으로 저장되는 데이터 구조입니다.
연결 리스트 (Linked List): 데이터를 저장하는 노드가 링크로 연결된 형태로, 필요에 따라 동적으로 크기를 조정할 수 있습니다.
스택 (Stack): LIFO (Last In First Out) 구조로, 가장 마지막에 들어간 데이터가 가장 먼저 나오는 구조입니다.
큐 (Queue): FIFO (First In First Out) 구조로, 가장 먼저 들어간 데이터가 가장 먼저 나오는 구조입니다.
2. 비선형 구조 (Non-linear Data Structures)
o 데이터가 일렬이 아닌 계층 구조나 복잡한 형태로 배치된 구조입니다.
o 종류:
트리 (Tree): 계층적인 구조로, 부모와 자식 관계로 이루어져 있습니다. 예로 이진 트리나 이진 탐색 트리 등이 있습니다.
그래프 (Graph): 정점과 간선으로 이루어진 복잡한 관계를 표현하는 자료구조로, 네트워크와 같은 복잡한 데이터 간의 관계를 표현할 때 유용합니다.
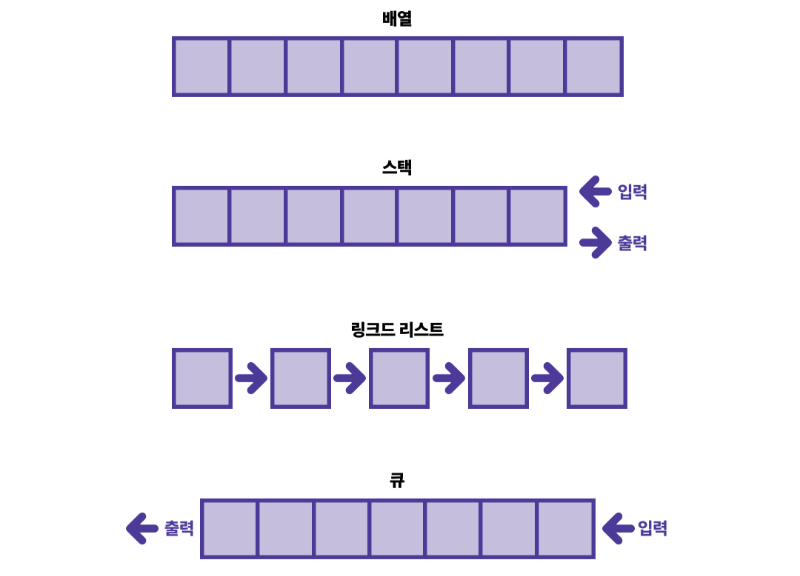
3-1. 배열(Array)
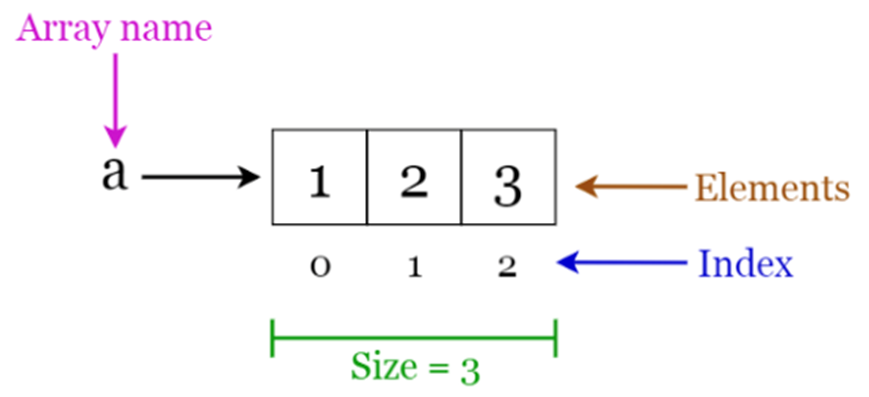
배열은 고정된 크기의 메모리 공간에 연속적으로 데이터를 저장하는 자료구조
배열의 크기는 한 번 설정하면 바꿀 수 없으므로, 데이터를 미리 예측하고 배열의 크기를 설정하는 것이 중요합니다.
o 고정된 크기: 배열의 크기는 생성 시에 정해지며, 실행 중에는 변경할 수 없습니다.
o 빠른 접근 속도: 각 요소는 메모리에서 연속된 위치에 저장되므로 인덱스를 사용해 빠르게 임의 접근할 수 있습니다. 예를 들어, array[3]처럼 인덱스 번호로 특정 위치에 바로 접근할 수 있습니다.
• 장점:
o 인덱스가 있어, 임의 접근이 빠릅니다.
o 데이터가 연속적으로 저장되어 있어, 메모리 접근이 효율적입니다.
• 단점:
o 크기가 고정되어 있어서, 데이터의 추가/삭제가 불편합니다.
o 데이터가 추가되어 크기를 변경해야 할 경우, 새로운 배열을 만들어야 하므로 비효율적일 수 있습니다.
2. 연결 리스트 (Linked List)

연결 리스트는 각각의 데이터(노드)가 다른 노드를 가리키는 포인터를 가지고 있어, 동적으로 메모리를 할당할 수 있는 자료구조
배열과는 달리 고정된 크기가 아니라, 필요에 따라 메모리를 할당하여 사용할 수 있습니다.
Linked List(연결 리스트)의 구성 요소
-
노드(Node) : 연결 리스트의 기본 단위입니다. 각 노드는 두 가지 정보를 담고 있습니다.
-
데이터(Data): 실제로 저장하고자 하는 값입니다.
-
포인터(Next): 다음 노드의 주소를 가리키는 참조입니다.
-
헤드(Head): 연결 리스트의 첫 번째 노드를 가리키는 포인터입니다. 헤드 노드는 리스트의 시작점을 나타냅니다.
-
테일(Tail): 리스트의 마지막 노드를 가리키는 포인터입니다. 테일 노드는 리스트의 끝을 나타내며, 단일 연결 리스트의 경우 이노드의 포인터는 Null이 됩니다.
o 동적 크기 조절: 실행 중에도 메모리 크기를 자유롭게 조절할 수 있습니다.
o 비연속적 저장: 배열과 달리, 데이터가 연속된 메모리 공간에 있지 않고 각각의 노드가 메모리의 다른 위치에 저장될 수 있습니다
• 장점:
o 데이터의 삽입/삭제가 유연합니다. (중간에 데이터 삽입/삭제 시에도 효율적)
o 메모리 낭비가 적다: 필요할 때만 메모리를 할당하므로 메모리 효율이 높습니다.
• 단점:
o 인덱스를 사용한 임의 접근이 불가하여, 원하는 데이터를 찾으려면 첫 번째 노드부터 순차적으로 탐색해야 하므로 접근 속도가 느립니다.
o 추가적으로 포인터를 저장해야 하므로 메모리 사용량이 더 많습니다.
연결 리스트의 종류
1. 단일 연결 리스트 (Singly Linked List)
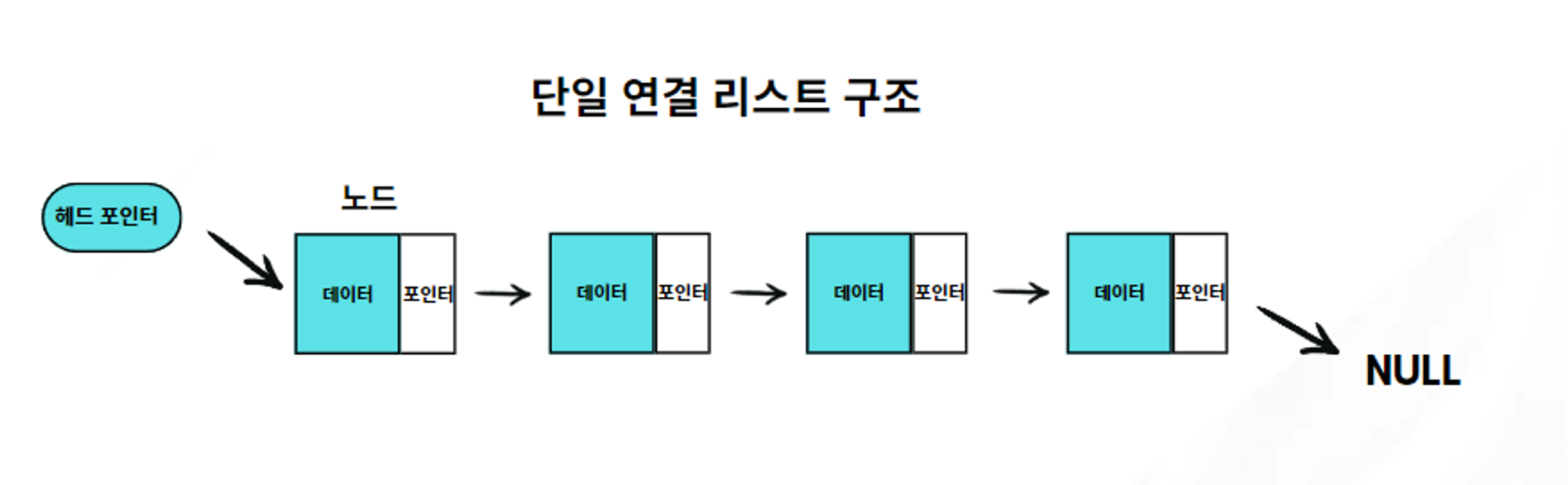
o 각 노드가 다음 노드에 대한 포인터만 가지고 있는 형태입니다.
o 데이터가 한 방향으로만 연결되어 있어, 다음 노드로 이동할 수 있지만 이전 노드로는 이동할 수 없습니다.
o 장점: 구조가 간단하며 메모리 사용량이 적습니다.
o 단점: 이전 노드로 접근할 수 없어, 특정 노드를 삭제할 때 비효율적일 수 있습니다.
2. 이중 연결 리스트 (Doubly Linked List)
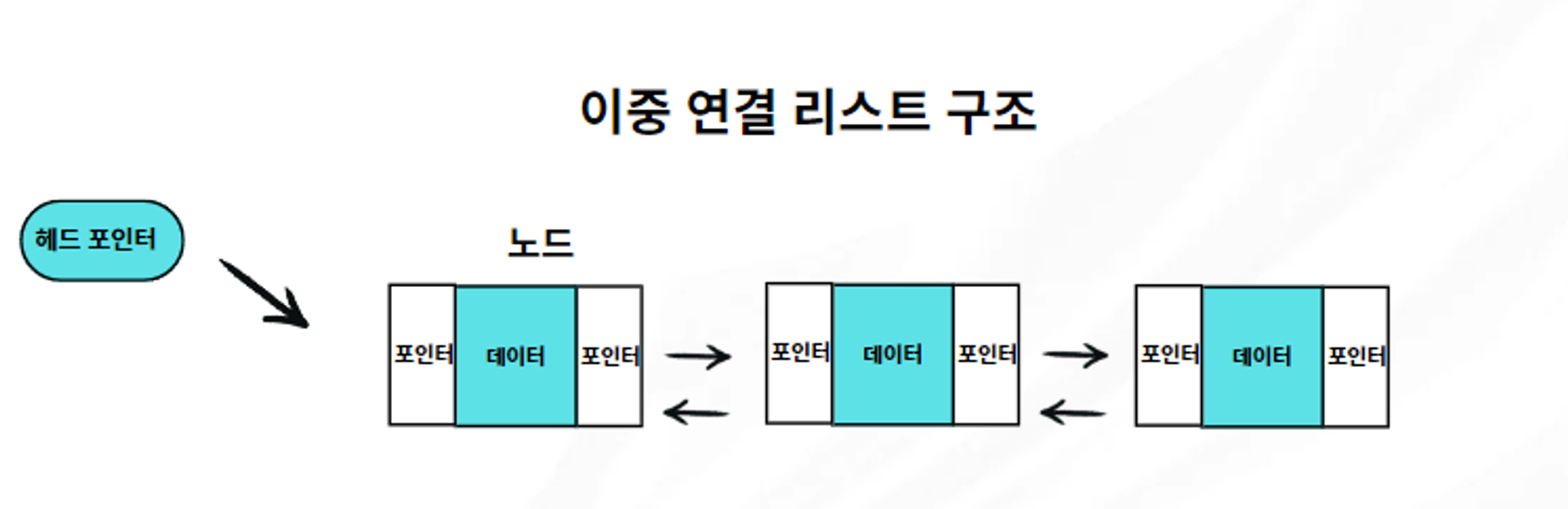
o 각 노드가 이전 노드와 다음 노드에 대한 포인터를 모두 가지고 있습니다.
o 양방향으로 이동이 가능하여, 단일 연결 리스트보다 데이터 접근이 유연합니다.
o 장점: 양방향 이동이 가능해 삽입/삭제가 더 편리합니다.
o 단점: 각 노드가 두 개의 포인터를 저장해야 하므로 메모리 사용량이 증가합니다.
3. 원형 연결 리스트 (Circular Linked List)
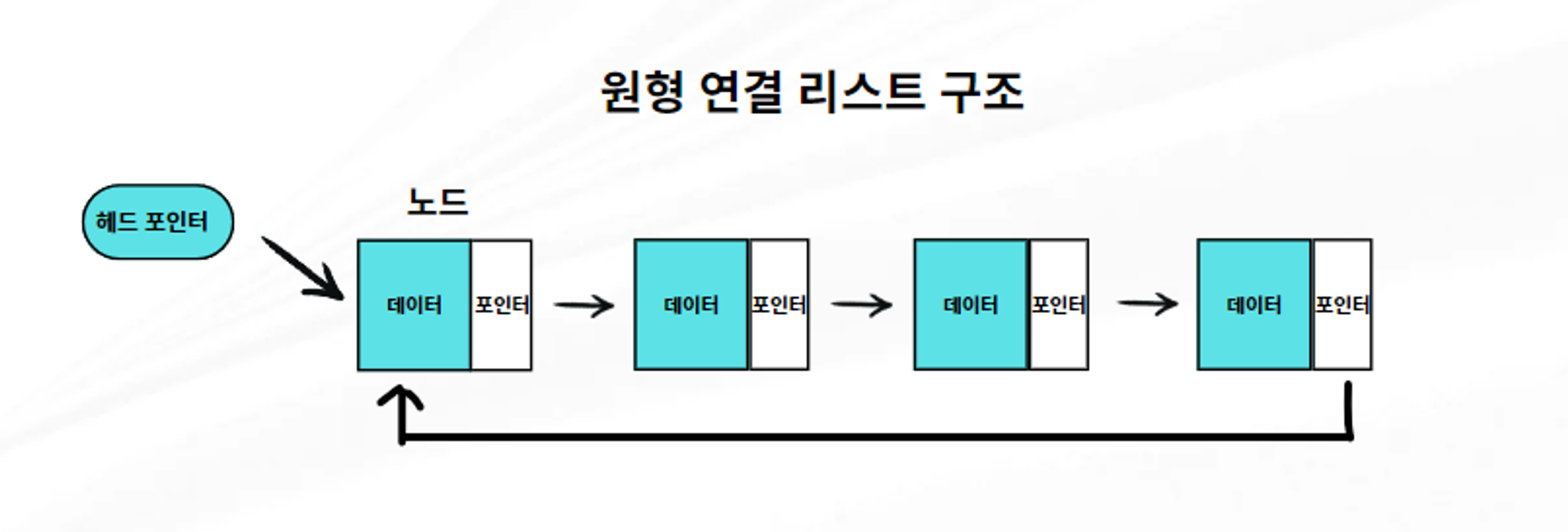
o 마지막 노드가 다시 첫 번째 노드를 가리키는 구조로, 연결 리스트의 끝과 시작이 연결된 형태입니다.
o 장점: 리스트의 처음과 끝이 연결되어 있어 반복적인 순환이 가능합니다.
o 단점: 노드를 순회할 때, 어디서 시작했는지 확인하지 않으면 무한 루프에 빠질 수 있습니다.
배열과 연결리스트의 차이
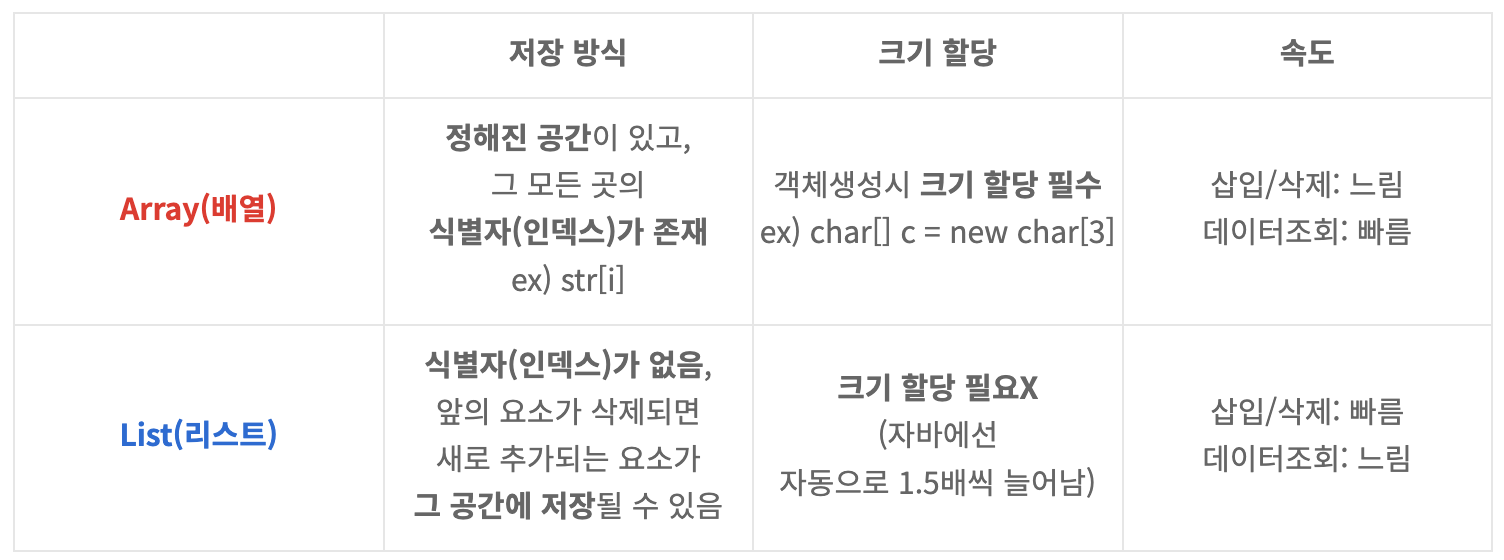
o 배열 (Array):
메모리에 연속된 공간에 데이터를 저장하는 자료구조입니다.
고정된 크기를 가지며, 데이터에 빠르게 접근할 수 있습니다. 하지만 크기를 변경할 수 없다는 단점이 있습니다.
o 연결 리스트 (Linked List):
각 데이터 요소가 개별 노드로 존재하며, 노드 간에는 포인터로 연결되어 있습니다.
동적으로 크기를 조절할 수 있어서 메모리를 효율적으로 사용할 수 있습니다. 하지만 특정 위치의 데이터에 접근하려면 연결을 따라가야 해서 속도가 느릴 수 있습니다.
[용어정리]
🔎노드 (Node)란?
o 노드는 자료구조에서 데이터를 저장하는 기본 단위로, 트리나 그래프와 같은 구조에서 데이터와 연결 정보를 담고 있습니다.
o 예를 들어, 트리 구조에서 한 개의 데이터와 이를 연결하는 링크가 있는 개별 요소를 노드라고 합니다.
o 그래프에서는 정점(Vertex)이라는 용어로도 불리며, 간선(Edge)으로 다른 노드와 연결됩니다.
🔎임의 접근이란?
임의 접근 (Random Access)은 배열에서 특정 위치에 바로 접근할 수 있는 능력을 의미합니다.
예를 들어, 배열 array가 있을 때 array[3]이라고 하면 네 번째 위치에 있는 데이터에 바로 접근할 수 있습니다.
이렇게 인덱스를 이용해 원하는 위치의 데이터를 즉시 읽거나 수정할 수 있는 기능이 임의 접근입니다.
반면에, 연결 리스트는 순차 접근 (Sequential Access)만 가능합니다.
즉, 특정 위치에 있는 데이터를 찾으려면 첫 번째 노드부터 순차적으로 연결을 따라가야 합니다.
따라서 원하는 위치에 빠르게 접근하는 배열과 달리, 연결 리스트에서는 접근 시간이 더 오래 걸릴 수 있습니다.
🔎배열의 "고정된 크기"의 의미
배열의 크기가 고정되어 있다는 말은 배열을 생성할 때 메모리에 예약된 크기를 변경할 수 없다는 뜻입니다.
일반적으로 배열은 메모리에 연속된 공간에 데이터가 저장되기 때문에 생성 시 미리 크기를 정하고 메모리를 확보합니다.
만약 배열을 생성하면서 array[10]으로 크기를 10으로 설정했다면, 10개의 공간을 초과할 수 없으며, 데이터를 더 추가하려면 새로운 배열을 만들어야 합니다.
예를 들어, 배열의 크기를 10으로 설정했다면, 11번째 데이터를 추가할 수 없습니다.
이때, 추가 공간이 필요하면 기존 배열을 복사해서 더 큰 배열을 만들고 데이터를 옮기는 작업이 필요합니다.
반대로, 배열의 요소를 삭제한다고 해서 배열의 크기가 줄어드는 것이 아니라, 그 자리는 빈 상태로 남아 있습니다.
🔎왜 배열의 크기를 변경하기 어려운가?
배열은 생성할 때 할당된 메모리 크기를 바꿀 수 없는데, 이는 배열이 연속된 공간을 사용하기 때문입니다. 크기를 바꾸기 위해 더 많은 공간이 필요해진다면, 연속된 추가 공간을 확보해야 합니다. 하지만 컴퓨터의 메모리에는 이미 다른 데이터가 저장되어 있을 수 있어, 기존 배열의 바로 옆에 필요한 크기의 연속 공간이 있을 거라고 보장하기 어렵습니다.
🔎연속된 메모리 공간이란?
컴퓨터에서 배열을 사용할 때는 하나의 덩어리로 메모리에 데이터를 저장합니다. 예를 들어, 배열의 크기를 5로 설정했다면, 메모리에서 5개의 연속된 공간을 한 번에 확보해야 합니다. 이렇게 연속된 공간을 확보하면, 첫 번째 위치만 알면 배열의 다른 위치도 바로 접근할 수 있게 됩니다. 이는 배열의 접근 속도가 빠른 주 이유입니다.
🔎배열의 빠른 접근 원리
-
첫 번째 위치 (기준 주소): 배열은 메모리에서 연속된 공간을 차지하므로, 배열의 첫 번째 위치(주소)만 알면 됩니다.
-
고정된 크기의 데이터: 배열의 요소들은 크기가 동일합니다. 예를 들어, 정수형 배열이라면 각 요소가 4바이트 크기입니다.
-
수학적 계산으로 접근: 배열의 i번째 요소에 접근하고 싶다면, 첫 번째 위치 주소에서 i × 요소 크기만큼 떨어진 위치로 바로 이동하면 됩니다.
예를 들어:
o 배열의 첫 번째 요소 주소가 1000이고, 각 요소가 4바이트라면,
o 배열의 세 번째 요소에 접근하려면, 1000 + (3-1) × 4 = 1008 위치로 가서 데이터를 읽으면 됩니다.
Referance
https://bnzn2426.tistory.com/115
https://baeharam.netlify.app/posts/data%20structure/hash-table
https://en.wikipedia.org/wiki/Hash_table#Separate_chaining
https://www.hanbit.co.kr/channel/category/category_view.html?cms_code=CMS2832062046
https://velog.io/@jha0402/Data-structure-개발자라면-꼭-알아야-할-7가지-자료구조
https://towardsdatascience.com/8-common-data-structures-every-programmer-must-know-171acf6a1a42
https://baeharam.netlify.app/posts/data structure/hash-table
https://velog.io/@sunset_1839/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-Linked-List-%EC%97%B0%EA%B2%B0-%EB%A6%AC%EC%8A%A4%ED%8A%B8
https://velog.io/@withbeluga/JAVA-Array%EB%B0%B0%EC%97%B4%EC%99%80-List%EB%A6%AC%EC%8A%A4%ED%8A%B8%EC%9D%98-%EC%B0%A8%EC%9D%B4-ArrayList
