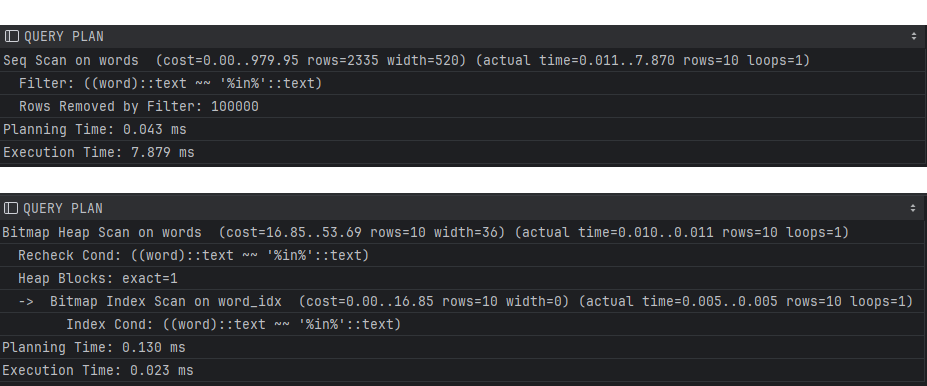
like %keyword% 검색을 쓰면 안되는 이유
in으로 시작하는 단어 찾기
예를 들어 누가 당신에게 in으로 시작하는 단어를 사전에서 찾으라고 한다면 당신은 다음과 같은 과정을 거칠 것이다.
i가 시작되는 위치를 찾는다.
-> in이 시작되는 위치를 찾는다.사전은 문자열이 정렬된 상태이므로, 특정 접두사(prefix)를 가진 단어를 찾는 것이 비교적 쉽다.
in으로 끝나는 단어찾기
in으로 시작하는 단어를 찾는 것과 달리, in으로 끝나는 단어를 찾으려면 다음과 같은 문제가 발생한다.
n으로 끝나는 위치를 찾는다
-> `in`으로 끝나는 위치를 찾는다같은 방법은 사용할 수 없다. 사전이 그렇게 정렬되어 있지 않기 때문이다.
결국 사전 전체를 탐색하여 찾을 수 밖에 없다.
이러한 원리는 SQL의 like연산에서도 적용되어서 'keyword%' 검색은 효율적이지만 like '%keyword' 검색은 비효율적인 것이다
실행계획 확인하기
CREATE TABLE words (
id SERIAL PRIMARY KEY,
word TEXT
);
CREATE INDEX word_idx ON words (word TEXT_PATTERN_OPS);인덱스를 추가해주겠다.
인덱스가 없으면 인덱스를 활용한 탐색이 안되기 때문이다.
인덱스를 사용하는 지 할 수 없는지 비교하는 것이 목적이기 때문이다.
참고로 그냥 BTree인덱스는 like 연산에 적합하지 않으므로 TEXT_PATTERN_OPS을 뒤에 붙여줘야한다. 붙여주지않는다면 like연산시 인덱스를 사용하지 않는다
INSERT INTO words (word) VALUES
('incredible'), ('insight'), ('invention'), ('innovation'),
('begin'), ('win'), ('chin'), ('twin'), ('ruin'), ('margin');
INSERT INTO words (word)
SELECT md5(random()::text) FROM generate_series(1, 100000);예제 데이터를 넣어보겠다.
in으로 시작하는 단어와 in으로 끝나는 단어들이다
그 아래 insert 문은 임의의 많은 데이터를 집어넣는 것이다.
참고로 md5는 해시함수라 8e96a7ac3339817b8ed4281bf4298930같은 데이터가 저장된다.
explain analyze
select *
from words
where words.word like 'keyword%';
explain analyze
select *
from words
where words.word like '%keyword';EXPLAIN ANALYZE는 postgresql에서 sql쿼리 성능을 분석하고 어떤 방식으로 실행되는지 확인하는 명령어이다
explai은 실행계획만 보여주고, explain analyze는 실제 실행 후 실행시간까지 보여준다
단 실행시간의 경우 cache 등의 요인에 의해서 영향을 받는다고 하니 너무 신뢰하지는 말자
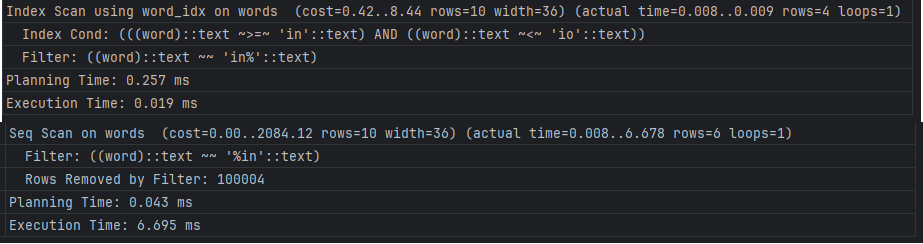
앞서 살펴본 것처럼 접두사 검색에는 인덱스를 사용하여 검색하는 반면, 접미사 검색에는 인덱스를 사용하지 못하고 전체탐색을 하는 것을 확인할 수 있다.
TEXT_PATTERN_OPS는 뭔가?
참고) postgresql 공식문서 - 오퍼레이터클래스
The operator class identifies the operators to be used by the index for that column
위에서 설명했듯이 btree인덱스를 like 검색에 사용하기 위해 TEXT_PATTERN_OPS라는 오퍼레이터 클래스를 사용했다. 이 글의 후반부에 나오는 pg_bigm, pg_trgm에서도 오퍼레이터 클래스를 사용하므로 미리 공부하는 것이 좋겠다.
https://overcome-the-limits.tistory.com/856
btree인덱스에서 왜 like검색을 사용할 수 없는지는 여기를 참고하시라
오퍼레이터 클래스는 인덱스를 효율적으로 구성하기 위해서 이 인덱스가 앞으로 이러이러한 연산을 사용할 것입니다라고 미리 선언하는 기능을 한다.
인덱스를 생성할 때 text_pattern_ops 오퍼레이터 클래스를 붙여주었기 때문에 데이터베이스 내부적으로 Like 'keyword%' 검색이 이루어질 때 인덱스 검색을 진행할 수 있도록 조치가 되었던 것이다.
Btree보다 더 문자열 검색에 효율적인 인덱스
GIN : Generalized Inverted Index
https://www.postgresql.org/docs/current/gin.html
GIN stands for Generalized Inverted Index. GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items
GIN은 복합적인 값을 포함하는 데이터를 인덱싱하는 경우를 위해서 설계되었다.
즉 복합데이터 내에 존재하는 특정 데이터를 쿼리하기 위해서 사용된다고 할 수 있다
gin에서 사용되는 오퍼레이터 클래스를 보면 어떤 느낌인지 확인할 수 있는데 내장 오퍼레이터 클래스로 array_ops, jsonb_ops, tsvector_ops를 제공한다.
GIN의 구조는 (key, posting list) 쌍으로 데이터를 저장한다.
posting list는 key를 가지고 있는 실제 복합데이터의 집합을 의미하는 듯 하다
posting list의 크기가 커지면 내부적으로 posting tree라고 불리는 btree를 형성한다
예를 들어 (apple, banana), (apple, caramel)이라는 데이터가 있다고 할 때 gin에서는 아래와 같이 저장되는 느낌이다. 보다싶이 하나의 row데이터가 다양한 key값에 매핑될 수 있다.
| Key | Posting List |
|---|---|
| apple | (apple, banana), (apple, caramel) |
| banana | (apple, banana) |
| caramel | (apple, caramel) |
문자열 검색에 도움이 되는 인덱스 중에는 Gist인덱스도 있는데 gist인덱스는 내가 이해를 못했으므로 소개하지 않겠다.
부분 문자열 검색에는 gin이 효율적이고 유사도 검색에는 gist가 효율적이라고 한다.
Full Text Search
PostgreSQL에서는 Full Text Search(FTS) 기능을 지원한다.
FTS는 텍스트 데이터를 보다 효율적으로 검색할 수 있도록 사전 처리하는 기능을 제공한다.
출처) postgresql docs - textsearch intro
1. Parsing documents into tokens : 문자열 토큰화
2. Converting tokens into lexemes : 토큰을 어휘소로 변환. 예를 들어 satisfies를 satisfy로 변환
3. Storing preprocessed documents optimized for searching : 사전처리된 데이터를 저장
FTS는 편리한 문자열 검색 기능을 제공하지만, 치명적인 한계점이 있다.
바로, 한국어를 지원하지 않는다는 점이다.
SELECT cfgname FROM pg_ts_config;위 SQL을 실행해 보면, 한국어뿐만 아니라 일본어와 중국어도 기본적으로 지원되지 않는 것을 확인할 수 있다.
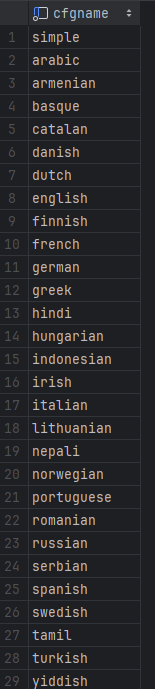
이러한 이유로, 한글을 사용하는 프로젝트에서는 PostgreSQL의 기본 FTS 기능을 활용하기 어렵다.
simple parser를 사용하면 되는 거 아니냐 생각할 수 있겠지만 simple parser는 token화할때 공백을 기준으로 진행하게 된다.
예를 들어 국민대학교라는 단어가 들어오면 의미상으로 국민 대학교으로 구분하길 바라지만, simple parser는 그냥 국민대학교로 구분한다. 공백이 없기 때문이다
https://github.com/i0seph/textsearch_ko
사실 postgresql textsearch용 한글 형태소 분석기 확장이 있으니 Full Text Search를 사용한 한글 검색을 구현하고 싶으신 분들은 이쪽을 참고하시길 바란다.
본 프로젝트에서는 특이하게도 한글 뿐만 아니라 중국어, 일본어 등의 다른 언어에 대해서도 검색기능을 제공해야하므로 FTS의 대안을 찾기 시작했다.
Ngram
이 게시글에서 사용할 pg_trgm과 pg_bigm은 N-gram을 사용한다
N-gram을 쉽게 설명하자면 텍스트를 N개의 글자 단위로 분할하는 것이다.
예를 들어 국민대학교를 2-gram한다면 국민 민대 대학 학교로 나눌 수 있다.
PG_TRGM vs PG_BIGM
pg_bigm과 pg_trgm의 차이는 공식문서에서 잘 설명해주고 있지만 몇개만 살펴보자면,
pg_trgm은 알파벳에 대해서만 지원하고 pg_bigm은 비알파벳 언어에 대해서 지원한다는 것이 가장 큰 차이점이다.
CREATE EXTENSION IF NOT EXISTS pg_trgm;
CREATE EXTENSION IF NOT EXISTS pg_bigm; postgresql에서 pg_trgm은 기본확장으로 들어있는데, pg_bigm은 별도의 설치과정이 필요하다.
pg_bigm의 경우 aws rds에서 지원은 하는데 저 sql을 실행하려면 rds_superuser 계정으로 접속하여 실행해야한다.
rdsadmin이 아니라 postgres라는 이름의 계정으로 접속해서 처리해주면 된다.
drop index word_idx;
CREATE INDEX word_idx ON words USING GIN (word gin_bigm_ops);
explain analyze
select *
from words
where words.word like '%in%';인덱스 추가 전후의 실행계획을 한번 비교해보자
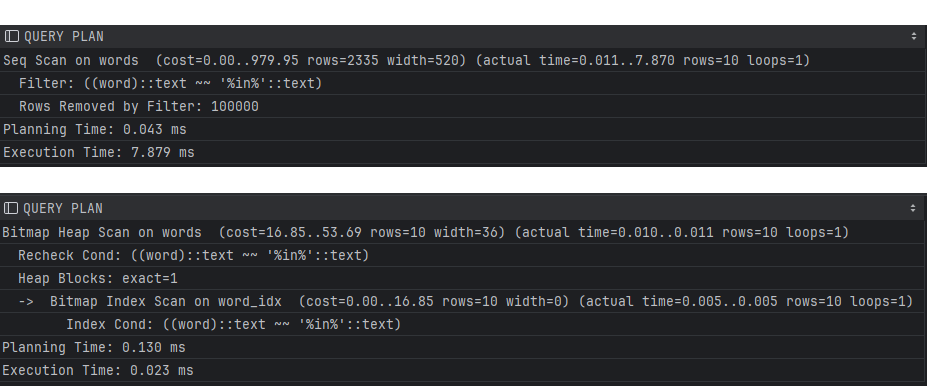
like %keyword% 연산임에도 불구하고 인덱스를 사용하여(bitmap scan) 빠르게 검색할 수 있다는 것을 확인할 수 있다.
참고로 pg_trgm에 대해서 놀라운 점을 하나 발견했는데, 2글자 이하의 검색에 있어서는 인덱스를 사용하지 않는 듯 하다.
-- bitmap heap scan이 진행됨 explain analyze select * from words where words.word like '%ins%'; -- seq scan이 진행됨 explain analyze select * from words where words.word like '%in%';
유사도검색
pg_bigm도 1.1 이후부터 유사도 검색을 지원하는데 2gram 단위로 쪼갠 뒤 공통되는 2gram의 개수를 기준으로 유사도를 검색한다
그러니까 '서울'을 검색하면 아래와 같은 결과가 나온다.
기본적으로 유사도 0.3부터 검색결과에 나오므로 하나도 검색이 되지 않는다고 할 수 있겠다.
굳이 사용하겠다면 유사도 0.06으로 낮추면 그래도 얼추 비슷하게 검색되는 느낌이다.
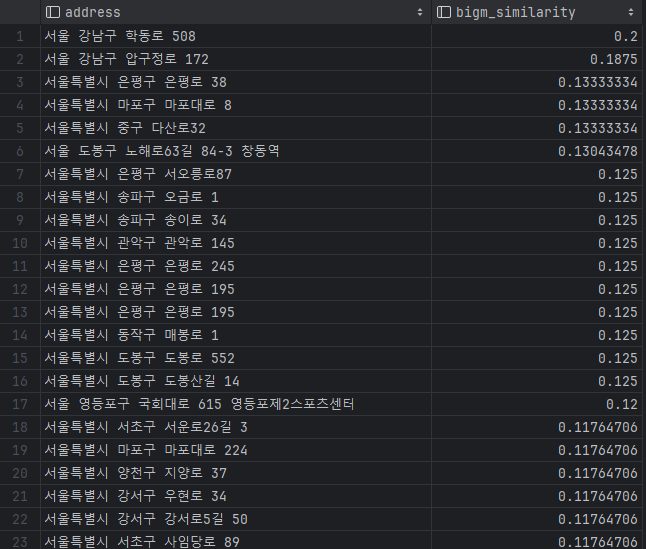
SET pg_bigm.similarity_limit TO 0.06;
select address, bigm_similarity(address, '파후시')
from libraries
where address =% '파후시'
order by bigm_similarity(address, '파후시') desc;유사도 검색의 장점은 파후시 처럼 오탈자가 있어도 얼추 비슷한 결과를 뽑아준다는 것에 있다

검색엔진
- 사실 문자열 검색을 전문적으로 해주는 검색엔진을 사용하는 것이 더 좋다는 것은 알고 있다.
- 근데 데이터베이스의 데이터를 검색엔진과 동기화시키는 것이 쉽지 않을 뿐 더러 검색엔진에 대한 학습이 쉬운 것도 아니고
- 검색엔진과 DB 동기화에도 컴퓨팅 리소스를 잡아먹고 검색엔진도 컴퓨팅 리소스를 잡아먹는다. 컴퓨팅 리소스 = 돈이므로 가벼운 프로젝트에서 무작정 사용하기에 부담스러워서 데이터베이스로 문자열 검색하는 방법을 찾아보았다.
