https://github.com/opensearch-project/spring-data-opensearch
aws opensearch는 elasticsearch와 싸운 뒤 elastic7에서 fork된 프로젝트이다.
아무튼 spring data elasticsearch로 opensearch에 접근하는 것이 어려운데, 알고보니 spring data opensearch에서 알아서 다 해결해줘서 spring data elasticsearch를 사용해서 aws opensearch에 접근할 수 있다.
1. AWS opensearch 생성하기
AWS Free tier는 opensearch도 지원한다.
t2.search.small, t3.search.small을 무료로 한달 750시간 제공한다.
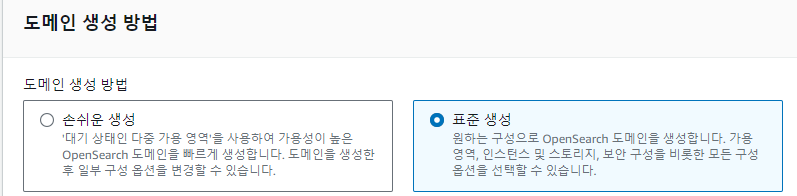
표준생성으로 해야한다
밑에 템플릿은 개발 및 테스트로 한다
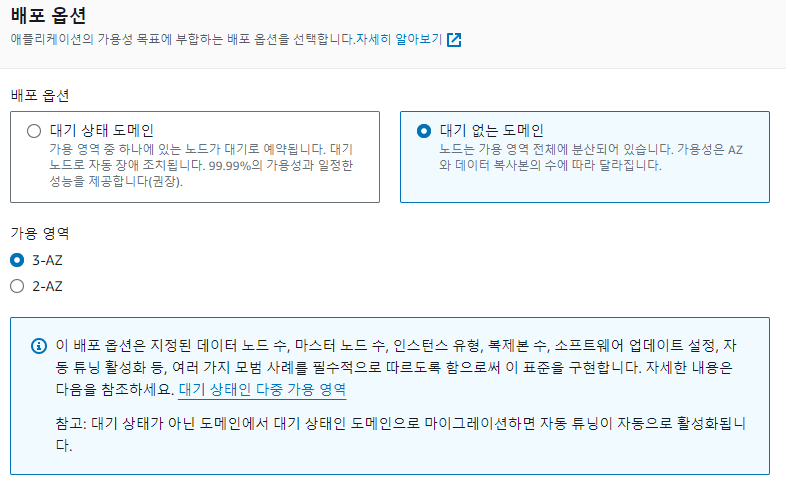
대기없는 도메인을 해야한다
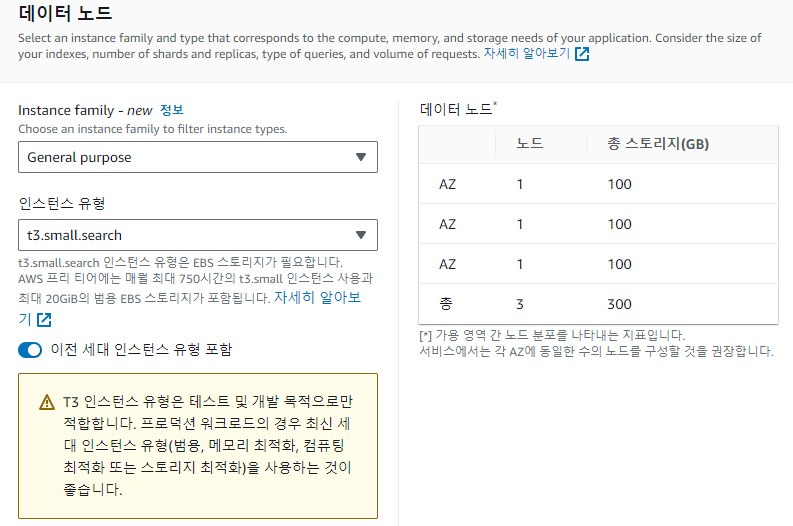
이전 세대 인스턴스 유형 포함을 클릭한 뒤 Instance family를 General purpose로 해야 t3.small.search가 나온다. 참고로 t2.small.search를 클릭하면 가격은 같은데 성능은 더 좋은 t3쓰라고 권고한다
(나오지 않는 다면 대기없는 도메인으로 설정했는지 확인하라)
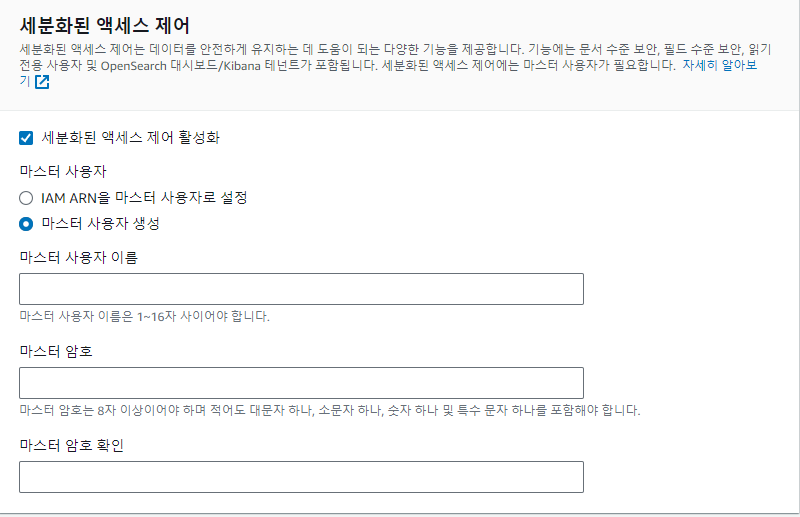
세분화된 액세스 제어는 마스터 사용자 생성을 해주고 이름과 비밀번호를 생성해주자
여기서 생성한 username, password가 이후 spring에서도 사용하고, 뿐만 아니라 opensearch의 kibana 격인 opensearch dashboard의 id로 사용된다.
2. spring opensearch
username과 password는 아까 설정한 마스터 사용자의 id와 비밀번호이다.
@Configuration
public class OpenSearchConfig extends AbstractOpenSearchConfiguration {
@Value("${opensearch.username}")
private String username;
@Value("${opensearch.password}")
private String password;
@Value("${opensearch.host}")
private String host;
@Value("${opensearch.port}")
private int port;
@Override
public RestHighLevelClient opensearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(host + ":" + port)
.usingSsl()
.withBasicAuth(username, password)
.build();
return RestClients.create(clientConfiguration).rest();
}
}이렇게만 해주면 이제 spring data elasticsearch를 사용할 수 있다.
하지만 spring data Elasticseach가 자동으로 config되는 것을 막아야 충돌이 나지 않는데, @SpringBootApplication(exclude = {ElasticsearchDataAutoConfiguration.class})를 추가해주면 된다.
@SpringBootApplication(exclude = {ElasticsearchDataAutoConfiguration.class})
public class AwsApplication {
public static void main(String[] args) {
SpringApplication.run(AwsApplication.class, args);
}
}이제 spring data Elasticsearch에서 제공하는 ElasticsearchOperations나 ElasticsearchRepository를 그대로 사용할 수 있다.
(공식 예제에서도 ElasticsearchRepository를 사용한다.)
