무조건 해야할 것
- [SUB], [OBJ]가 아닌 Subject Type을 활용하여 [SUB;{subject_type}]으로 처리하면 더 좋은 결과가 발생하지 않을까?
- 수행할 이유 : [SUB], [OBJ]가 좋은 결과가 나온 것은 그 단어에 조금 더 집중했기 때문이라고 생각한다. 만약 집중할 때, Type에 대해서도 집중한다면 더 좋은 결과가 나오지 않을까? 라는 생각으로 수행해보았다.
수행한 것
GitHub 코드가 현재로써는 너무 Conflict가 많이 날만한 구조이다. 일단 구조를 변경시켜서 충돌을 최대한 막는 구조로 변경하고, 피어세션 때 활용 가능성을 얘기해 봐야할 것 같다.
- 이 부분에 대해서는 일단 나중에 코드를 깔끔히 할 때 다시 논의해보는 것으로 하였다.
- 앞으로 협업을 할 때에는 처음부터 이런 것을 다 정하고 가야할 것 같다. 중간에 합치려니 모두가 힘들고, 협업 도구가 오히려 해가 된다는 얘기를 들었던 것 같은데 실제로 그렇게 된 것 같다.
[SUB;{subject_type}]으로 변경시켜 코드를 수행해보았다. Wandb 결과 그래프는 아래와 같다
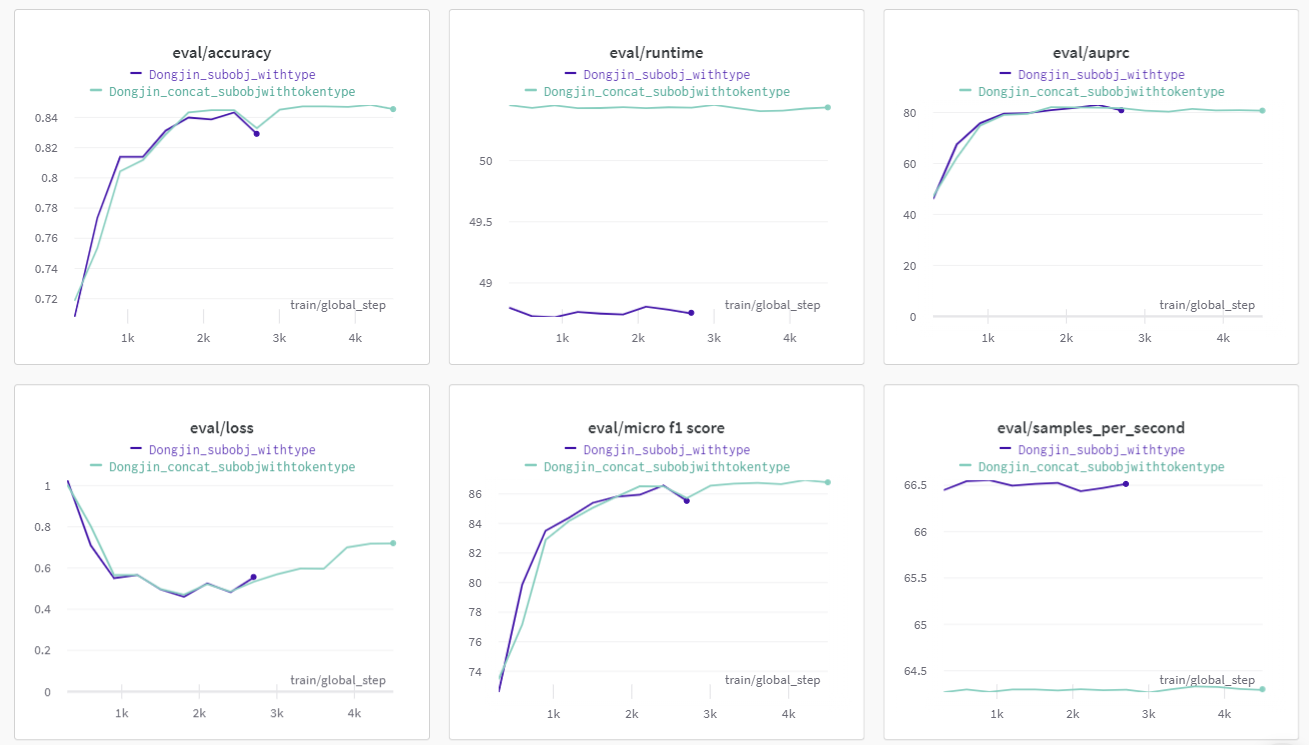
- 진한 파랑색이 Type까지 붙여 Tokenizing시킨 이후 학습시킨 것이다. Accuracy나 Loss측면에서 조금 더 낮은 성능을 보임을 알 수 있다.
- Test Data의 Subject Type에 Train에서는 없는 LOC라는 Type이 존재함을 알게 되었다.
- 성능이 떨어진 이유는 내가 생각하기에 데이터 자체가 적은데 Type까지 나눠서 학습을 시키려다보니 학습 데이터 자체가 충분하지 않았다는 느낌이다. 따라서 많이 학습시키면 Overfitting, 그렇다고 적게 학습시키자니 Underfitting이 발생하여 이런 문제점일 발생했던 것 같다.
- 실제 제출에서 0.3점 정도가 떨어졌고, [SUB], [OBJ]만 활용하기로 했다.
질문을 앞이 아닌 문장 뒤에다 붙여서 Tokenizing 해보았다.
- 수행하게 된 이유는 내가 코드를 착각하여 Tokenizing 시킨 이후 Special Token 위치를 찾았는데, 그 반대의 경우라고 착각하여 코드를 수행해보았다.
- 그런데 생각해보니, 사람이 말할 때 (A는 B이다. 이 때 A와 B의 관계는 무엇일까?)라고 하는 것이 더 자연스러울 수도 있을 것 같다는 생각이 들어 수행해보기로 하였다.
- 하지만, BERT 논문에서 QA Task를 해결할 때 질문을 앞에다 붙이는 것을 볼 수 있었다. 즉, 논문에서 실험했던 결과 질문을 앞에 붙이는 것이 더 좋다고 생각한 것 같은데, 일단 실험해보기로 하였다.
- 제출 시간을 넘겨 제출하지는 못했는데, Loss값 자체가 조금 더 높아져서 질문을 앞에다 붙이는 것이 더 좋아보인다.
Inference에 특정 확률 미만이고 no-relation일 때 2번째 꺼 선택해보자
- no-relation이 너무 많이 나왔다. 이게 데이터 Imbalance에 의해 나온다고 생각하였다.
- 결과 csv 파일을 뜯어 보니 no-relation 중 0.6 ~ 0.7의 확률을 가지고 no-relation으로 판단하는 게 있었는데, 이게 너무 많은 데이터 때문에 그냥 애매하면 대충 no-relation으로 처리하는게 아닐까? 라는 생각이 들어 한 번 no-relation을 줄이는 방향으로 수행해보기로 하였다.
- 결과적으로 0.5점이 떨어졌고, 심지어 AUPRC 점수도 떨어졌다. 즉, no-relation을 올바르게 판단했던 경우가 더 많았다는 반증이며, Data Imbalance는 다른 방식으로 해결해야 한다는 것을 알았다.
해볼 것
- Classifier Layer가 2개이다. 저번 이미지 분류 대회에서 Classifier Layer가 1개인 것이 가장 좋은 성능을 냈었는데, 이번에도 그렇지 않을까? 한번 적용해보자
- [CLS] 토큰에서 나온 값을 LSTM에 한 번 더 정제시킨 다음 Classifier Layer에 추가시키는 것은 어떨까?
- 내가 봤을 때 Punctuation이 가장 좋은 성능을 내는 것은 그 부분에 집중한다 + 그 단어가 어떤 단어인지 설명해준다의 이유인 것 같다. 예를 들어, Object가 로빈슨일 경우, Punctuation을 통해 이 로빈슨이 Person이라는 것을 알려주게 된다. 또한, 이 때 활용하는 Person도 이미 Vocab에 있는 단어이기 때문에 단어 유추에 도움을 주는 것이 아닐까? 해당 부분에 집중하는 것은 이미 [SUB], [OBJ] Special Token으로 수행했으니까 한 번 Special Token 사이에 Entity Type 정보를 넣어보자

개념부터 확실히!