EDA
EDA
- 데이터를 이해하기 위한 노력
- 데이터를 이해하고, Modeling 방법 및 Data Pre-processing(전처리)에 대한 계획을 짤 수 있게 해줌
EDA에서 해야할 것
- 데이터에 대한 의문점을 해결하는 방법으로 수행
- 한번 수행하고 끝나는 것이 아닌, Modeling 도중에도 아이디어가 떠오르면 해당 아이디어를 활용하기 위해 EDA를 계속해서 수행해야 할 필요가 있음
Competition에서 수행한 EDA
Data 구조 살피기
train_data = pd.read_csv(train_csv_path)
train_data.head()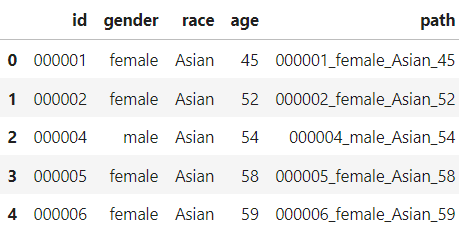
- Path에는 5개의 Image가 존재
- Mask1 ~ Mask5 : 마스크를 쓴 이미지
- incorrect : 마스크를 잘못 쓴 이미지
- Normal : 마스크를 아예 착용하지 않은 이미지
Race에 따른 Data 분포
sns.countplot(x='race', data=train_data)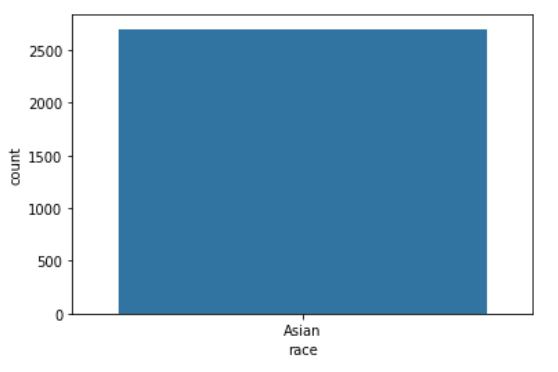
- 알 수 있는 점 : Race는 Class에 영향을 미치지 않는다(모두 같기 때문)
gender 및 Age에 따른 Data 분포
fig = plt.figure()
ax = fig.add_subplot(111)
sns.countplot(ax = ax,x='age_range',hue='gender', data= train_data)
ax.set_xticks([0,1,2])
ax.set_xticklabels(["30 Under", "30 Over 60 Under", "60 Over"])
plt.show()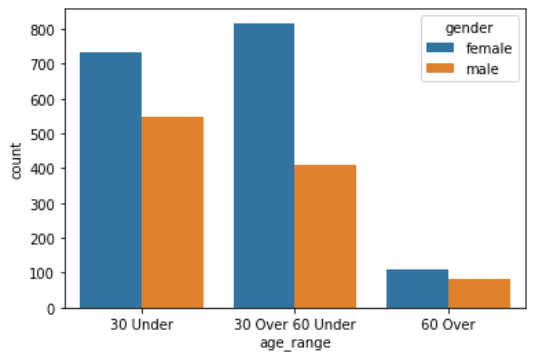
- 알 수 있는점
- 60 Over인 사람이 너무 적다. 이 부분을 처리해줘야 학습이 잘 진행될 것 같다.
- 30 ~ 60 사이의 사람은 gender에 따른 데이터 개수 차이가 너무 크다. female은 800에 다다르지만, male은 400밖에 되지 않는다. 이런 부분도 처리해 주면 더욱 학습이 잘 진행될 것 같다.
이미지 직접 보기
import matplotlib.image as img
import matplotlib.pyplot as pp
fileName = file_path
ndarray = img.imread(fileName)
pp.imshow(ndarray)
pp.show()- 사진은 저작권 때문에 올리지 않음
- 사진에서 알 수 있는 점
- Mask쓴 Data는 5개, Normal은 1개, incorrect는 1개의 Data가 존재하기 때문에, gender 및 age에 따른 Imbalance 성향이 더욱 두드러지게 표현될 것이다. 따라서, Mask 착용 여부에 대한 Imbalance도 무조건 처리해 줄 필요가 있다.
- 판단에 필요한 얼굴 이외에 배경이나 옷 등의 면적이 생각보다 넓다. 얼굴만 따로 뽑아서 학습을 진행하면 뭔가 좋은 결과물을 얻을 수도 있을 것 같다.
프로젝트 때 EDA
EDA라는 것을 처음해봐서 엄청 헤맸던 것 같다. 처음에는 그냥 데이터 구조가 어떻게 되어 있고, Class Imbalance가 있다 정도로만 이해하고 바로 Project를 수행했다. 하지만, 같은 팀원이 데이터 시각화를 통해 EDA를 체계적으로 수행한 것을 보고 내 EDA는 EDA가 아니였다는 사실을 알게 되었다.
이후 Matplotlib이나 Seaborn을 활용하여 EDA를 수행해보려고 하였고, 이렇게 시각적으로 데이터 분포를 보니 아이디어가 하나 둘씩 생각나는 것을 알 수 있었다.
EDA는 Data를 이해하기 위해서 수행하는 것도 있지만, 내가 수행하는 프로젝트의 길잡이 역할을 수행해주는 중요한 과정이라는 것을 알게 되었다. 다음 프로젝트 때부터는 EDA 결과를 다른 사람에게 보여준다는 생각을 가지고 최대한 데이터 시각화를 적극적으로 수행해야겠다고 알게 된 프로젝트였다.

개념부터 확실히!