Throwable Class
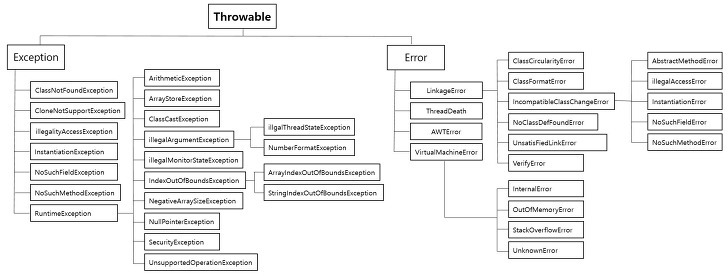
Throwable Class란?
예외 처리를 할 수 있는 최상위 클래스로, JAVA에서는 try ~ catch구문을 활용하여 처리할 수 있고, Python에서는 try ~ except 구문을 사용하여 처리할 수 있는 클래스들 위에 존재하는 최상위 클래스를 말한다.
종류로는 Error와 Exception이 존재한다.
먼저 Error는 "시스템" 내 비정상적인 상황이 발생한 것으로, 개발자가 미리 예측하여 처리할 수 없다.
Exception(예외)는 사용자의 잘못된 조작, 개발자의 잘못된 코딩으로 인해 발생하는 것으로 예외 처리(Exception Handling)으로 개발자가 처리해 줄 수 있다.
Exception의 종류는 Checked Exception과 Unchecked Exception으로 나뉘며, Checked Exception은 예외 처리가 필수적인 예외로 Compile 때 예외 발생하며 Unchecked Exception : 예외 처리가 필수적이지 않은 예외로 Runtime 때 예외가 발생한다.
공부하며 궁금했던 질문 1
- 에러(Error)는 발생하기 전까지는 개발자가 아무런 처리도 할 수 없는 것인가?
- 답 : 예외 처리를 통해 완벽히 없앨 수는 없지만 최소화 시킬 수는 있다.
대표적인 Error는 OutOfMemoryError와 StackOverflowError가 존재한다.
OutOfMemoryError는 Heap 메모리 공간이 없을 때 발생하는데, 배열 등을 사용할 때 과도한 메모리를 사용하여 발생한다. 이 경우 개발자는 자신이 가지고 있는 메모리를 파악하여 배열에 하할당할 수 있는 최대 Memory를 계산하고, 예외 처리를 통해 그 이상의 공간이 할당되는 Case 때는 사용자에게 알림을 보낼 수 있을 것이다.
StackOverFlowError는 Stack의 깊이가 너무 깊어져 Parameter나 Return 값 등을 저장할 Stack 저장 공간이 부족해져 발생한다. 이 Error는 주로 무한 재귀 함수 호출 등의 이유로 발생하므로 예외 처리나 Parameter로 수행 횟수를 다음 재귀 함수에 전달하여 재귀 함수가 N번 이상 수행될 때 무한 재귀 함수라고 생각하여 코드를 종료시키는 방법으로, 완벽한 회피는 불가하지만 최대한 회피할 수는 있을 것이다
하지만, 위에서 설명했듯 개발자가 해당 코드가 에러를 유발할 가능성이 존재한다는 것을 알고 미리 그 상황을 예측하여 처리할 수 밖에 없기 때문에, 완벽히 에러 처리를 하는 것이 아닌 발생할 수 있는 에러를 "최대한" 줄이는 것에 불과하다.(따라서, 처음 출시된 Version부터 완벽한 프로그램이나 게임은 존재하지 않는다)
공부하며 궁금했던 질문 2
- Checked, Unchecked Excpetion의 차이가 무엇일까?
나는 Checked는 (코드의) 사용자가 정해진 Rule대로 프로그램을 시행했을 때에도 발생할 수 있는 Exception, Unchecked는 사용자가 정해진 Rule을 무시하고 코드를 활용했을 때 발생할 수 있는 Exception이라고 생각했다.
예를 들어, 파일에서 특정 숫자를 다운받아 그 숫자에 사용자가 숫자 N을 입력하여, N으로 나누는 알고리즘을 수행한다고 가정하자.
만약, 파일이 존재하지 않는다면 파일에서 숫자를 가져올 수 없을 것이다. 즉, 사용자는 제대로 프로그램을 수행했더라도 예외가 발생할 수 있으므로 FileNotFoundException은 CheckedException이 될 것이다.
파일이 존재한다고 가정하자. 사용자는 0이 아닌 다른 수를 모두 입력해도 되지만, 절대로 0은 입력해서는 안된다(숫자를 0으로 나눌 수는 없기 때문에)
하지만, 사용자가 0을 입력하였다고 가정하자. 그렇다면 이 때는 ArithmeticException이 발생할 것이고, 이 Exception은 사용자가 정해진 Rule에 따라 코드를 수행하지 않아 발생한 Exception으로 UnCheckedException이다.
Checked Exception은 사용자가 완벽하게 코드를 수행해도 발생할 수 있는 에러이다. 이는 개발자의 실수로 인해 사용자가 불편함을 겪기 때문에 Compile 때 미리 해당 가능성을 지우라고 알리는 것이다. 따라서, 예외 처리가 필수적인 Exception이 될 것이다.
반대로, Unchecked Exception은 사용자가 정해진 Rule을 따르지 않아 발생할 수 있는 에러이다. 이 경우, 개발자는 잘못하지 않았어도 발생할 수 있는 예외지만 반대로 사용자가 완벽히 사용만 한다면 발생하지 않을 예외라는 것이다. 따라서, Runtime 때 사용자가 이상한 행동을 했을 경우 발생할 Exception이고, 예외 처리가 필수적이지는 않게 되는 것이다.
Python에서의 예외 처리
try ~ except 구문
- if ~ else 구문으로도 처리 가능
# Template
try:
수행할 코드
except {Exception1}:
Exception1이 발생했을 떄 수행될 코드
except {Exception2} as E:
Exception2가 발생했을 때 수행될 코드
# 예시
try:
tmp = int(input())
result = 10 // tmp
except ZeroDivisionError: # tmp = 0일 떄 발생함
print("Not Divided by 0")
except Exception as E:
# 이외 Exception이 발생하면, 해당 Exception 정보 출력
print(E) Raise 구문
- Exception을 강제로 발생 시키는 구문
- 사용 이유
- 시스템 안정성
- 코드를 구현하는 중간 과정에서 "구현하지 않은 부분"에 대한 확인을 위해 활용
# Template
raise {발생 시킬 Exception}
# 예시
def count(self):
pass
# 이 경우 실수로 count(self)를 구현하지 않을 경우에도 코드가 실행됨
def count(self):
raise NotImplementedError
# count(self)를 구현하지 않았는데 실행될 경우 에러가 발생하여 미구현임을 알림Assert 구문
- 예외 조건이 True나 False를 반환할 때, 예외 조건이 False일 경우 예외를 발생 시킴
- 입력값 혹은 출력값 검증을 위해 활용됨
- 발생시키는 Exception : AssertionError
# Template
asser {Exception 조건}
# 예시
tmp = input()
assert isinstance(tmp, int)
# tmp가 int형이면 true이며 아무일도 발생하지 않음
# tmp가 int형이 아니면 False이므로 AssertionError 발생
tmp = int(input())
tmp = tmp+2
assert 3==tmp
# 만약, tmp가 1이 아니여서 결과가 3이 나오지 않으면 AssertionError발생File 종류
- Text 파일
- 인간도 이해할 수 있는 형태로 저장된 파일
- 메모장으로 열면 읽을 수 있음
- Binary 파일
- 컴퓨터만 이해할 수 있는 형태로 저장된 파일
- 메모장으로 열어도 해석 불가
Text 파일도 사실 Binary 파일의 일종이다. 단지, Text File은 File에 저장된 이진코드를 ASCII Code 등으로 변환했을 때 인간이 이해할 수 있는 형태로 변환 가능한 Binary File일 뿐이다
Python File I/O
File I/O에 알아야 하는 정보들
- 파일 열기 모드
- r : 읽기 모드
- w : 쓰기 모드(write) => 원래 존재하는 내용 모두 지우고 새로 씀
- a : 추가 모드(append) => 원래 존재하는 내용 뒤에 입력되는 내용을 덧붙임
- encoding : 필수적 입력 사항은 아님
- Default : utf-8
- Windows 같은 경우, Default로 cp949 형태로 저장되므로 항상 File이 어떤 형식으로 저장되어 있는지 확인이 요구됨
파일 객체 얻기
# Template
f = open({파일 경로}, {파일 열기 모드}, encoding)
# 1번 방법
# 무조건 file 객체를 얻은 이후 사용이 종료되었으면
# close() 예약어를 사용해서 "무조건" 객체를 닫아주자!!!
f = open("C:/Users/idj32/Python/ex.txt",'r')
f.close() # 중요!!!!!!!!!!!!!!!!!!!!!!!!
# 2번 방법
# with 구문을 통해 close()를 통해 객체를 닫아줄 필요가 없음
with open("C:/Users/idj32/Python/ex.txt",'r') as f:
print(f.read())- Close 구문을 통해 파일 객체를 닫아야 하는 이유
- append나 write한 내용이 File에 반영되지 않을 수 있음
- 언어나 OS에 따라 다르지만, 메모리 부족이나 파일 객체 생성이 불가해질 수도 있음
파일 읽기
- f.read() : 파일의 전체 내용을 문자열로 반환함
- f.readlines() : 파일 전체 내용에서 각 줄을 리스트에 저장하여 리스트 형태로 반환
- f.readline() : 한 줄만 읽고, 해당 내용 반환 & 포인터를 다음 줄로 이동시킴
파일 쓰기
- f.write({파일에 저장시킬 내용}) : 얻어온 파일 객체에 입력한 내용을 저장함
- 파일 열기 모드가 a일 경우 : 내용을 원래 파일의 "뒤에" 덧붙여 저장함
- 파일 열기 모드가 w일 경우 : 원래 파일 내용을 reset시키고 입력한 내용만 해당 파일에 저장시킴
File 형식 및 특징
CSV
- 필드를 쉼표(구분자)로 구분한 Text File
- 액셀 양식 Data를 프로그램 상관 없이 쓰기 위한 데이터 형식
- CSV Module을 활용하여 csv 객체를 통해 데이터 추출 가능
- csv.reader({CSV 파일 객체}, delmiter, quotechar, quoting)
- delimiter : 필드(데이터)의 분할을 위해 활용되는 문자
- quotechar : 필드(데이터) 1개를 묶기 위해 활용되는 문자
- quoting : quotechar의 Level을 결정
- (ex) "A", "B", "C", "D"일 때 쉼표(,)가 delimiter가 될 것이고, A,B,C,D 각 데이터는 큰 따옴표(")로 묶여 있으므로 큰 따옴표가 quotechar이 됨
- 하지만, 최근엔 pandas를 통해 CSV를 많이 활용
JSON
- 기계, 인간이 모두 이해하기 편하고 간결한 Data
- Key : Value 쌍으로 데이터 표현
- Dict type으로 Data를 읽고 저장
- CSV와 마찬가지로 최근엔 pandas를 통해 JSON 많이 활용
- json.loads({JSON 파일 객체}) : Dict type Data 가져옴
json.dump(Dict type data, {저장할 파일 객체}) : Dict type Data 저장
WEB(HTML)
- 인터넷에서 사용자가 볼 수 있는 화면에 대한 정보를 저장한 파일
- HTML은 정해진 형식이 존재함
- 정규식을 활용하여 편히 검색 가능
- 최근에는 정규식 대신 BeautifulSoup라는 모듈 활용
import urllib.request
import re
url = "http://www.naver.com"
html = urllib.request.urlopen(url)
# html : url에 접속하여 서버쪽에서 받아온 HTML이 저장되어 있다.
html_contents = str(html.read().decode("utf8"))
# HTML 파일을 모두 읽어와 utf8로 decoding 시킨 후 문자열로 형변환
url_list = re.findall(r"{정규식}", html_contents)
# html_contents에서 정규식과 일치하는 모든 부분을 list형식으로 반환
# 꼭 정규식 앞에 r 알파벳 입력해주자!XML
- TAG : 데이터의 구조와 의미를 설명하는 item
- XML : TAG와 TAG 사이 데이터를 입력하여 표시하는 언어
- HTML과 마찬가지로 정해진 형식이 존재함
- 정규식을 활용하여 편히 검색 가능하지만, 마찬가지로 최근에는 BeautifulSoup 모듈을 자주 활용
- XML 파일 형식
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.1.0.RELEASE</version>
</dependency>
</dependencies>BeautifulSoup
- HTML, XML 등 마크업(Markup) 언어를 처리하기 위한 대표적 도구
- 속도는 상대적으로 느리지만 사용이 간편
- 하지만 매우 큰 속도 차이가 발생하는 것은 아님
- 가상 환경에 "lxml", "beautifulsoup"가 미리 설치 되어 있어야 함
# Template
soup = BeautifulSoup({파일 객체}, "lxml")
soup.find({TAG}) : TAG에 대응하는 "첫 번째" Data 반환
soup.find_all({TAG}) : TAG에 대응하는 "모든" Data를 List 형식으로 반환
# 예시
from bs4 import BeautifulSoup
soup = BeautifulSoup(./data, "lxml")
# Tag가 groupId인 모든 데이터를 리스트 형식으로 반환한다
for data in soup.find_all("groupId"):
data # TAG & TAG 사이에 존재하는 Data 모두 반환
data.get_text() # TAG는 반환하지 않고 TAG 사이에 존재하는 Data만 반환
- 사진 출처 : https://sjh836.tistory.com/122
- Throwable 클래스에 대한 설명도 잘 되어 있으므로, Throwable Class에 대해 더 알고 싶다면 방문하여 공부해보자
