
알고 있는 metric에 대해 설명해주세요
- Metric : 평가 지표
- 공부한 사이트 : https://velog.io/@lswkim/%EC%95%8C%EA%B3%A0-%EC%9E%88%EB%8A%94-metric%EC%97%90-%EB%8C%80%ED%95%B4-%EC%84%A4%EB%AA%85%ED%95%B4%EC%A3%BC%EC%84%B8%EC%9A%94.-ex.-RMSE-MAE-recall-precision-
Accuracy(정확도)
- 데이터 분포가 동일하다는 가정이 존재할 때만 활용하는 것을 추천
- 굉장히 위험한 평가 방법
- 100개 데이터 중 1이 90, 0이 10일 때 모두 1로 예측하면 90의 Accuracy를 가지는 매우 좋은 Model로 평가할 가능성이 존재
Confusion Matrix
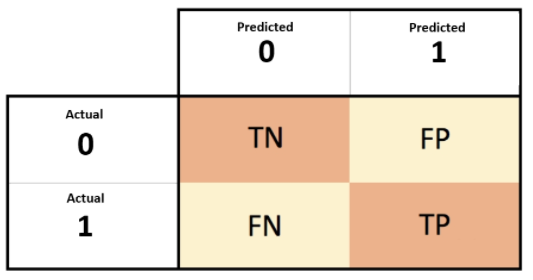
- TN : 실제는 Negative이고, Negative로 예측함
- FP : 실제는 Negative이지만 Positive로 예측함
- FN : 실제는 Positive이지만 Negative로 예측함
- TP : 실제는 Positive이고, Positive로 예측함
- 우리가 중점적으로 생각해야 할 것을 Positive로 고려함
Precision & Recall
- Precision : 예측값이 실제값과 일치하는 비율
- FP를 낮추는데 초점을 둠
- Recall : 실제값에서 내가 예측한 비율
- FN을 낮추는데 초점을 둠
- FN을 낮추는데 초점을 둠
- Precision : 확실하게 맞는 것에 비중을 두고 평가
Recall: 맞는 것을 아니라고 하지 않는 것에 대해 비중을 두고 평가- Recall : Positive인데 Negative로 판단하는 것이 큰 문제를 일으킬 경우 사용
- Precision : Negative인데 Positive로 판단하는 것이 큰 문제를 일으킬 경우 사용
F1 Score
- 라벨의 분포가 균등하지 않을 경우 활용
- Precision과 Recall의 조화평균을 구한 것
- Precision과 Recall 모두 한 쪽으로 치우치지 않을 때 높은 점수를 얻을 수 있음
- Precision과 Recall 모두 한 쪽으로 치우치지 않을 때 높은 점수를 얻을 수 있음
ROC Curve
- 참조 사이트 : https://angeloyeo.github.io/2020/08/05/ROC.html
- x축 : FPR(False Positive Rate)
y축 : TPR(True Positive Rate)- Positive : 판단자가 예측값이 "맞다"고 판별한 것
- True : 판단을 올바르게 한 것
- False : 판단을 틀리게 한 것
- TPR : 실제로 예측된 상태에 존재했을 때, 판단을 올바르게 한 비율. 즉 Recall
- 1인 상황에서 1로 바르게 예측하는 비율
- FPR : 실제로 예측된 상태에 존재하지 않았는데, 해당 상태라고 잘못 판단한 비율
- 0인 상황에서 1로 틀리게 예측하는 비율
- Threshold가 낮다 : 많은 Case에서 1이라고(즉, 예측된 상태에 존재한다고) 예측함
- 현의 휨 정도
- ROC 커브가 좌상단에 가깝게 휜다면, False Positive와 True Positive Probability Density 그래프의 거리가 멀다는 뜻
- 즉, 2 클래스를 더 잘 구별할 수 있다는 의미이므로, 판단을 올바르게 했는지 잘못했는지에 대해 잘 알 수 있다는 뜻
- 알 수 있는 점 : 가운데
y=x직선에서 거리가 멀어질수록 Model의 성능이 좋아짐
ROC-AUC Score(AUROC)
- ROC Curve 면적에 기반한 AUC(Area Under Curve)값을 지표로 활용
- ROC 면적이 클 수록 Classification을 잘 수행해줌을 말해줌
- FPR이 작은 상태에서 얼마나 큰 TPR을 얻을 수 있느냐가 관건
AURPC
- 정밀도 재현율 곡선
- ROC Curve : x축이 FPR, y축이 Recall
- 정밀도 재현율 곡선 : x축이 Recall, y축이 Precision
- AUROC보다 절댓값이 더 작으므로, 인상적으로 보이기 위해 AUROC를 많이 활용함
BLEU
- 자연어 생성 모델의 정확도를 평가하는 지표
- 특히 기계 번역 성능을 측정할 때 많이 활용
- 0이 가장 작고 1이 가장 큰 값을 가짐
- N-gram으로 묶은 단위로 Precision을 구하는 방식
- https://velog.io/@idj7183/Decoding-BLEU
EM(Extract Match)
- 질의응답 Task를 평가하는 지표로 많이 활용
- (Question + Answer) 쌍에서 실제 답과 같다면 EM = 1, 아닐 경우 0을 반환
- strict all-or-nothing metric
Rouge Score
- 생성모델의 평가를 할 때 활용하는 Metric
- 특히 Text Summarization에서 많이 활용
- n-gram Recall에 기반한 계산 수행
- Rouge에서의 Recall : 참조 요약본(정답 요약본)을 구성하는 단어 중 몇 개의 단어가 시스템 요약본(Model이 생성한 요약본) 단어와 겹치는지 보여줌
- 위에서 설명한 Recall처럼, 분모에 정답(실제 Data)가 들어감
- 위에서 설명한 Recall처럼, 분모에 정답(실제 Data)가 들어감
- Rouge에서의 Precision : 시스템 요약본의 단어가 참조 요약본에 얼마나 등장하는지 확인
- 위에서 설명한 Precision처럼, 분모에 Model 예측값이 들어감
- 위에서 설명한 Precision처럼, 분모에 Model 예측값이 들어감
- 위에서 구한 Recall 및 Precision을 n-gram 단위로 묶어서 계산한 뒤, F1-score로 계산하여 최종 Metric 반환
Pos 태깅은 무엇인가요? 가장 간단하게 POS tagger를 만드는 방법은 무엇일까요?
POS 태깅이란 Corpus를 형태소 단위로 쪼개고, 각 형태소에 품사 정보를 부착하는 작업이다. 한글은 주로 세종 말뭉치(KoNLPy)를 많이 활용한다.
가장 간단하게 POS tagger를 만드는 방법은, 먼저 사전에 존재하는 모든 단어를 미리 저장해 놓는 것이다. 이후, 몇 가지 문장을 띄어쓰기를 기준으로 단어를 쪼갠 다음 Bidirectional LSTM으로 학습시켜 유의어나 같은 스펠링이지만 다른 뜻을 가진 단어, 그리고 단어 위치에 따른 품사 등을 학습시켜 POS tagger를 만들 수 있을 것 같다.
Cost Function과 Activate Function은 무엇인가요?
Layer에서 선형 모델로 바꾼 다음 데이터를 그대로 다음 Layer로 전달하면 사실상 계속 선형 데이터로 학습을 진행하는 것이므로 많은 정보를 담지 못하게 된다.
따라서, 일부로 Layer Output에 비선형성을 줄 필요가 있고, 이런 비선형성을 주는 함수를 Activate Function이라고 한다.
주로 ReLU, Sigmoid, tanh를 활용한다.
Cost Function은 학습을 통해 최적화 시키려는 함수이다. 엄밀한 의미에서는 Loss Function과 다른 차이가 있다고 알고는 있으나, 보통 동일하게 생각한다.
항상 Cost Function 결과를 최적화시키는(Loss를 감소시키는) Parameter를 찾는 방향으로 학습이 진행된다.

개념부터 확실히!