GIL
GIL 개념에 대해 설명해주세요
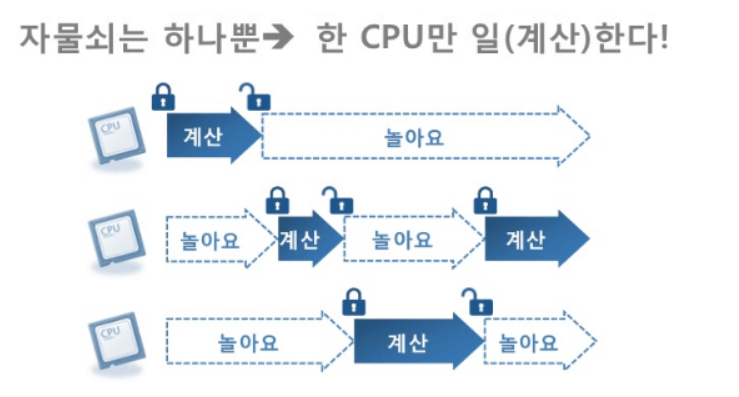
Python Interpreter가 1개의 스레드만 하나의 Byte Code를 실행시킬 수 있도록 해주는 Lock이다.
하나의 스레드에 모든 자원을 허락하고 그 후에는 Lock을 걸어 다른 스레드는 실행할 수 없게 막는 것이다
즉, Python에서는 Thread가 여러개여도(Multi THreading 시에도) 병렬 실행이 불가능하며, 이유는 GIL이 1개의 스레드만 실행하도록 Lock을 걸기 때문이다
GIL은 그럼 왜 쓸까?
GIL은 Multi Threading에서 병렬 실행을 막기 때문에, 오히려 실행시간을 늘린다.
(이유 : 다음으로 실행될 Thread를 선택하고, 해당 Thread에 Lock을 걸어줘야 하며, 이전에 실행된 Thread에 Lock을 푸는 역할까지 해야 하므로)
이렇게 실행시킬 Thread(자원을 가지고 있어 실행될 Thread)를 변환하는 과정을 Context Switching(문맥 전환)이라고 하며, 문맥 전환 비용이 든다고도 말한다.
그렇다면, GIL을 쓰면 오히려 시간이 더 오래 걸리는데 Python은 왜 이런 방식을 활용할까?
먼저, GIL는 Race Condition 문제 해결을 위해 도입했다.
Python에서 외부 연산 등을 기다릴 때 CPU가 아무것도 하지 않으면 Context Switching을 시도하는데, 이 때는 다른 Thread가 실행되어도 외부 연산을 기다리는 Thread는 Lock을 가지고 있지 않으므로 Race Condition이 발생하지 않는다
두 번째로, GIL에 의한 멀티스레딩이 무조건 느리지느 않다는 것이다
외부 연산 작업(일반적으로는 I/O 작업)이 많아서 Thread가 대기해야 하는 상황이 많을 경우, GIL을 통해 Multi Threading을 수행하는 것이 Context Switching을 통해 외부 연산 작업을 기다리는 시간을 줄일 수 있기 때문에 더욱 좋은 성능을 낼 수 있는 것이다
*args, **kwargs
*args, **kwargs 정의
*args 형식은 (key, value)를 받는 형식을 제외한 모든 형식을 인자로 받을 수 있다
**kwargs는 (key, value)를 받는 형식의 인자를 받을 수 있다
*args와 **kwargs는 동시에 활용 가능하지만, 대신 동시에 활용하기 위해서는 순서는 꼭 지켜서 인자로 넘겨줘야 한다.
왜 활용할까?
-
함수가 선택적으로 인자를 받을 수 있음
*args나 *kwargs를 동시에 활용하여 *args가 입력되면 A 메서드를, *kwargs가 입력되면 B 메서드를 수행하도록 만들 수 있다.
이렇게 될 경우 입력값의 형태를 다양하게 할 수 있으므로 모듈 및 클래스에서 더욱 유연한 API를 만들 수 있다 -
코드의 확장성
로그인하는 함수가 (ID, Password)만 입력하는 함수에서 (ID, Password, 이름)까지 입력하는 함수로 바꾸어야 한다고 가정하자.
Input 형식이나 DB 같은 경우 Column을 추가하는 것은 명령어나 HTML에 1줄을 추가함으로써 쉽게 구현 가능하지만, 함수를 변경하기 위해선 해당 함수를 찾아서 적절한 Parameter를 추가해주어야 할 필요가 있다.
하지만, *args를 활용하면 args가 포함하는 원소가 1개 늘어난 것일 뿐이므로, 이 부분에 대한 코드만 추가시켜주면 Parameter에 대한 부담이 상당히 줄어들게 된다
Copy
deep copy vs shallow copy
Deep Copy는 데이터 자체를 통째로 복사하는 형식이다.
즉, A를 Deep Copy하여 B라는 객체가 생성되었다면, A와 B는 각각 독립적인 메모리를 차지하게 된다.
Shallow Copy는 복사한 객체에 새로운 메모리를 생성하지 않고, 주솟값을 복사하여 같은 메모리를 가리키게 하는 것이다.
즉 A의 주소가 C일 때, A를 Shallow Copy한 B 또한 주소가 C라는 의미이다.
C 데이터를 확인하고 싶을 때는 A를 찾아도 되고, B를 찾아도 된다.
주솟값을 복사하기 때문에, A 값이 변경되면 B 값도 동시에 변경된다.
Reference Type의 복사
Reference Type(Value Type이 아닌 데이터; 내가 만든 클래스에 대한 Instance 등)은 따로 명시하지 않으면 Shallow Copy가 일어난다.
- Value Type은 boolean, byte, short, int, long, float, double, char, String 등을 포함함
따라서, Reference Type을 깊은 복사하고 싶다면 Deep Copy를 위한 메서드를 활용하거나 새롭게 Instance를 생성하여 값을 일일히 복사하는 방법을 통해 복사를 진행해야 한다
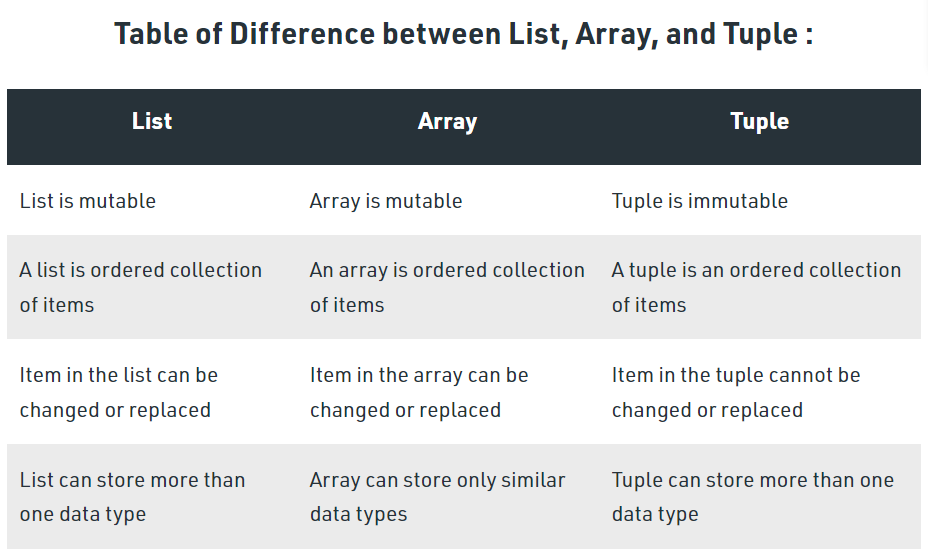
List, Tuple, Array
Python에서의 List VS Array
Python은 특이하게 list와 array가 매우 유사하다.
Python List의 근본은 배열(Array)이지만, 대신 High-level 기능들이 추가된 배열이라고 생각하면 된다.
High-level 기능의 대표적인 예는 pop, append 등이며, 이런 기능들을 활용해 Python List를 Stack이나 Queue를 만들 수도 있다.
컴퓨터공학에서의 List VS Array
Array는 일반적으로 크기(Size)가 정해져 있고, 특별한 기능이 없다.
Element의 Index는 변경되지 않으며, 인덱스를 통한 빠른 조회가 가능하다.
List는 1개의 Node가 데이터와 포인터 값을 위한 공간을 가지며, 포인터는 "다음 Node"의 주솟값을 가리킨다.
List는 데이터의 추가 및 삭제가 편하지만, Index를 통해 접근할 때 Pointer를 타고 이동하므로 조회에는 많은 시간이 걸린다
List VS Tuple
List는 Mutable하다.
Mutable이라는 것은 "변경 가능하다"라는 의미로써, 만약 List에 특정 값을 추가할 때 원래 존재하던 메모리 주소에서 그대로 확장되는 형식으로 데이터가 변경된다.
즉, List는 원래 존재하던 메모리 주소를 변경하지 않고 데이터 변경이 가능하다.
Tuple은 Immutable하다.
Tuple에 값을 추가하면, 존재하던 주솟값에 있던 Tuple에서 Size만 확장시켜 추가하는 것이 아닌, 새로운 메모리 주소를 할당받아 그곳에 새로운 Tuple을 할당하는 방식으로 값이 확장된다.
이는 "변경되었다" 라기보다는 "새로 만들었다"라는 의미가 강하며, Immutable하다라는 것으로 이해할 수 있다.
또한 List는 값에 대한 변경이 가능하지만, Tuple은 원소를 변경 혹은 삭제하는 것이 불가능하다는 차이점이 존재한다
Python 심화 기능
Python Closure
배경지식
- 함수 중첩(Function Nesting)
- 정의된 함수 내에 새로운 함수를 정의하는 것
def greeting():
def english(): # Nesting된 함수
return "Hello"
print(english())-
First Class Object
- 해당 언어에서 일반적으로 다른 모든 개체에 통용 가능한 동작(operation)이 지원되는 개체(entity)
- 동작
- 함수의 인자로 전달됨
- 함수의 반환값이 됨
- 수정되고 할당됨
- 정해진 Object라기보다는 "반환값 및 Parameter로 많이 활용되는 객체" 정도로 생각하면 될 것이다.
- Python에서는 함수(Function)도 First Class Object이다
- 함수를 인자(Parameter)로 활용 가능
-
nonlocal
- 변수는 Scope를 가지고 있다. 변수를 어디에 선언하느냐에 따라 어떤 변수를 활용할지 결정된다.
- nonlocal은 중첩 함수 내에서 해당 키워드를 활용할 경우, 새로운 지역 변수가 되지 않고 함수 밖(중첩 함수를 담고 있는 외부 함수)의 비전역 변수를 가리킨다는 것을 의미한다.
Python Closure
자신을 둘러싼 Scope의 상태값을 기억하는 함수를 의미한다.
Closure인 함수는 3가지 조건을 만족해야 한다.
특정 함수에 중첩된 함수여야 하며, 자신을 둘러싼(Enclose) 함수 내의 상태값을 "반드시" 참조해야 하며(nonlocal 변수를 활용해야 하며), 해당 함수를 둘러싼 함수는 이 함수를 반환해야 한다
Python Closure 사용시 장점
변수의 관리 및 책임을 명확히 할 수 있고, 변수의 불필요한 충돌을 방지할 수 있으며 사용 환경에 맞게 내부구조를 조정할 수도 있다는 장점을 가진다.
또한, 함수에 어떤 변화가 있더라도(심지어 삭제되더라도) nonlocal 변수 값은 계속해서 저장되어 있다는 특징을 가진다.
Python Decorator
Python Decorator이란?
대상 함수를 Wrapping하여 Wrapping된 함수의 앞 뒤에 추가적으로 코드를 붙여 내가 원하는 동작이 수행되도록 하는 것이다.
예를 들어, 함수의 "실행 시간"을 알고 싶을 때, 항상 함수 앞뒤에 time을 재는 메서드를 넣어야 할 것이다.
그런데, 실행 시간은 Log에 남길 정도로 중요한 데이터이며, 대부분의 함수에서 이 메서드는 필요할 것이다.
그렇다면, 매번 이 메서드를 넣는 것이 귀찮지 않을까?
그래서, 이런 "시간을 재는 메서드"를 미리 코드로 구현해 놓고, Decorator로써 활용하면 Decorator를 붙이고 내가 원하는 함수 내용만 입력한다면 함수가 자동으로 Decorator의 빈 공간에 들어가 원하는 기능이 실행되는 것이다
Decorator는 어떻게 형성하는가?
중첩함수를 활용하거나 Class 형태로 Decorator를 만들 수 있다.
활용은 @{Decorator 이름}으로 지정하면 된다.
Nested Function 형식
# Decorator 이름 = Enclose Function(외부 Function) 이름
def time(func):
def decorated():
start = datetime.datetime.now()
func()
end = datetime.datetime.now()
print(end - start)
return decorated- func()의 실행 시간을 Print할 것이다.
Class 형식
# Decorator 이름 = Class 이름
class DatetimeDecorator:
def __init__(self, f):
self.func = f
def __call__(self, *args, **kwargs):
start = datetime.datetime.now()
self.func(*args, **kwargs)
end = datetime.datetime.now()
print(end - start)Python Generator
Generator란?
Iterator를 생성해주는 함수이다.
함수 안에 yield 키워드를 활용해 생성한다.
yield
generator 함수가 실행 되다 yield 키워드를 만날 경우, 해당 함수는 그 상태로 정지 되며 반환 값을 next()를 호출한 쪽으로 전달한다
이후 해당 함수는 종료되는 것이 아닌 그 상태로 유지된다.
즉, 함수에서 활용된 local 변수나 instructino pointer 등과 같은 함수 내부에서 활용된 데이터들이 메모리에 그대로 유지되는 것이다
다른 말로 하자면 yield 키워드를 만나면 generator를 호출한 함수로 가서 yied i에서 i 값을 반환한다(Return 시킨다)
원래 return을 활용하면 함수가 종료되지만, Generator는 다르다.
현재 값을 return 시키고, 함수 상태를 그대로 저장시킨 이후 Generator 함수를 호출한 메서드에 가서 Return된 값에 대한 처리를 끝마친 이후 다시 함수로 돌아와 다음 부분부터 함수를 진행시키는 것이다
Generator를 왜 활용하는가?
먼저, 메모리를 효율적으로 활용할 수 있다.
List는 사이즈가 커질수록 메모리 사용량이 증가한다.
하지만, Generator의 경우 사이즈가 커진다고 해도 차지하는 메모리 사이즈는 동일하다
List는 List 안에 속한 모든 데이터를 적재하므로 데이터 양에 비례하여 메모리 사용량이 증가하는데, Generator는 데이터 값을 한꺼번에 메모리에 적재하지 않고 next() 메서드를 통해 차례대로 값에 접근할 때 해당 데이터만 메모리에 적재하는 방식을 활용하므로, 모든 데이터를 저장하지 않아도 된다.
즉, 1000개가 있든 10000개가 있든 내가 메모리에 적재할 값은 next() 메서드를 통해 얻을 수 있는 데이터이므로 반환되는 값의 Size가 같다면 Memory Size도 동일할 것이다
두 번째로 Lazy Evaluation이다.
계산 결과 값이 필요할 때까지 계산을 늦출 수 있다는 것이다
List 같은 경우 for문 등을 통해 List Iterable을 수행할 경우 list의 모든 값을 먼저 수행하게 된다.
즉, List값이 매우 클 경우, List에 있는 모든 데이터에 대하여 한꺼번에 모아서 함수를 실행할 것이기 때문에, 엄청난 Cost적 부담이 발생한다.
하지만, Generator의 경우 Generator를 생성할 때 for문이 수행될 때 1개의 함수가 실행됨 -> 다음 함수가 실행됨... 의 과정을 거친다.
즉, 함수를 한꺼번에 모아서 한번에 실행시키지 않고, 순차적으로 실행시킨다는 것이다.
이는 수행 시간이 [1,1,10,1,1]일 때, List로 수행하면 14초 후에 결과가 한꺼번에 수행되어 나오지만, Generator는 [1,1,10,1,1]초 이후에 각각의 결과가 순차적으로 나오므로, 수행시간이 긴 연산을 최대한 늦출 수 있어 대기 시간을 줄일 수 있다는 장점이 있다.
Iterator
Iterator란 값을 차례대로 꺼낼 수 있는 객체를 의미한다.
next() 메서드를 통해 다음 값을 가져올 수 있는 객체이다.
Iterable과 Iterator는 약간의 차이가 존재하는데, Iterable은 내부 요소를 하나씩 리턴할 수 있는 객체이며, Iterator는 next()를 통해 다음 요소를 찾을 수 있는 객체이다.
물론 다르긴 하지만, Iterator는 iterable한 객체를 내장함수 또는 iterable 객체의 메서드로 객체를 생성할 수 있다.
즉 Iterable한 객체는 Iterator로 변경 가능하다는 것이다
Collection
Collection이란?
다수의 데이터를 쉽고 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스 집합을 의미한다.
즉, 데이터를 저장하는 자료구조 및 알고리즘에 대해 구현해 놓은 것을 의미한다
List
- 위에서 설명했음
Map
-
Key와 Value로 구성된 객체
-
Key는 중복 저장될 수 없으나, Value는 중복될 수 있음
- Key가 중복되어 데이터를 넣으면, 원래 Key에 대응하는 Value 값이 변경됨
Set
-
중복된 요소를 포함할 수 없는 Collection
-
Index를 활용하지 않음
PEP 8
PEP 8이란?
코드를 짤 때 Pythonic하게 짠 코드가 매우 좋은 코드가 된다.
그런데, 어떻게 코드를 짜야 Pythonic하게 짜인 코드인걸까?
이 방법을 설명해준 Python Coding Convention이 PEP 8이다.
- DocString에 대한 Convention인 PEP 257도 존재한다.
들여쓰기(Indentation)
들여쓰기는 4개의 스페이스를 활용해야 한다.
1줄의 코드를 여러줄로 나눠쓰고 싶을 경우, 수직 정렬하여 읽기 좋게 만들어야 하고, 첫번째 줄에 인자가 없다면 들여쓰기를 추가로해서 다음행과(즉, 함수 본문과) 구별이 되도록 해야 한다.
Tab / Space
Space를 활용하는 것이 권장되지만 필수는 아니다
지만, 하나의 프로젝트에 tab과 space를 동시에 쓰는 일은 피해야 한다
Line 최대 길이
코드 1줄은 79자 이내로 작성하기를 권장한다.
최근 모니터의 크기 향상으로 100자 이상도 볼 수는 있으나, 불특정 다수에게 보여지는 코드일 경우 79자를 지키는 것이 좋다.
코드가 길어질 경우 백슬러시(\)를 활용하여 줄바꿈을 한다.
빈 줄(Blank Lines)
Source File Encoding
파일의 인코딩은 항상 UTF-8을 활용한다.
Imports
1줄에 2개의 모듈을 Import하는 것은 바람직하지 않다.
단, from으로 동일한 패키지엥서 여러 개의 모듈을 Import 할 때는 한 줄로 활용할 수 있다.
Standard Library imports / 3rd party Library imports / Local application, library specific imports를 구분하여 빈 줄로 구분되게 import 시키는 것이 추천된다.
또한, '*'를 통해 모든 모듈을 import하는 방식은 피해야 한다.
Dunders Names
- 더블언더스코어(__)를 활용하는 Name을 Dunders name이라고 한다.
이런 name은 모듈의 docstring과 import 코드 사이에 위치하는 것을 권장한다.
따옴표(" "또는 ' ')
문자열을 표현하는 따옴표는 Python에서는 구분하지 않는다. 하지만, 따옴표 내부에 따옴표를 활용할 경우 다른 것을 활용해야 하며, docstring에서 활용되는 따옴표3개는 꼭 "를 활용하는 것을 추천한다
Whitespace in Expressions and Statesment
Statesment는 코드 1줄, Expression은 수학 수식을 의미한다.
의미 없는 띄어쓰기를 피한다.
예를 들어, 컴마와 닫는 괄호 사이, ':' 사이, 괄호에 붙어있는 코드에 띄어쓰기를 활용할 필요는 없다
Other Recommendations
연산자를 쓸 때는 앞뒤로 스페이스를 한 칸씩 넣어줘 구분이 쉽게 만들어준다.
단, 수학 연산자가 여러 개 있을 경우 우선순위가 가장 낮은 연산자 주위로 스페이를 한 칸씩 넣고, 나머지는 넣지 않아 연산의 순서를 보기 쉽게한다.
Trailing Commas
1개의 아이템만 있는 튜플, 혹은 아이템이 추가될 가능성이 있는 객체에 대해서 Trailing Commas를 활용하는 것을 추천한다.
주석
주석의 첫 글자는 대문자로 시작해야 하며(식별자가 소문자라면 예외) 영어로 작성하는 것을 추천한다.
Inline comment(코드와 같은 라인에 주석 다는 것)을 피하는 것이 좋다.
CPython vs Pypy
CPython
C로 구현된 처음 만들어진 Python이다.
CPython은 Python Code를 Compiling하여 bytecode를 생성하고, bytecode를 1줄 씩 읽어 Interpreter를 통해 실행한다.
import를 할 때 library를 compile된 bytecode로 처리하는 ㄴ것이 속도가 더 높기 때문에 이런 방식을 채택했다.
- 장점
메모리 측면에서 우수하며 간단한 코드에서는 속도도 Pypy보다 빠르다.
Pypy
JIT Compile을 사용하여 Native Assembly Code로 변환한다.
Interpreting을 수행하지만, 자주 쓰이는 코드가 발견될 경우 bytecode 전체를 Compile하여 Native Assembly Code로 변환한다.
이후, 이렇게 변환한 코드는 Interpreting하지 않기 떄문에 속도가 상승한다.
Runtime 시 위와 같은 최적화가 처리되며, pypyjit을 통해 세부적인 통계도 얻을 수 있다.
-
장점
반복작업이 많은 경우 Pypy가 속도면에서는 우세하다. -
단점
ML의 경우 Tensorflow와 PyTorch에서 Pypy가 지원하지 않는 C library를 활용해야 하므로, 활용하지 못한다.
파이썬 메모리 관리
Python 메모리 관리에 대한 원리
Python 메모리 관리자는 Block이라는 메모리를 관리하고, 동일한 크기의 Block들이 Pool을 구성한다.
객체가 파손될 경우 메모리 관리자는 해당 공간에 동일한 크기의 새 객체로 채운다.
메서드와 변수는 스택 메모리에 작성되고, Object 및 Instance 변수는 Heap Memory에 작성된다.
Reference Count
Python은 malloc()과 free() 명령어를 많이 활용하기 때문에 메모리 누수의 위험성이 존재한다.
이런 위험성을 관리하기 위하여 레퍼런스 카운트를 활용한다.
레퍼런스 카운트란 파이썬의 모든 객체에 Count값을 할당하여, 객체가 참조될 때 증가시키고, 참조가 삭제될 때 Count를 감소시킨다.
Count가 0이 될 경우 메모리에 할당된 값을 삭제하는 형식으로 메모리 관리가 진행된다
Garabage Collection
메모리에 존재하는 객체는 Old 객체와 Young 객체로 나눌 수 있는데, 객체는 생성되자마자 버려지는 경우가 많으므로 Young 객체가 비교적 더 많이 존재한다.
따라서, Garbage Collector가 젊은 객체 위주로 관리하기 위해 작동 빈도수를 높이는 것이다.
Reference Count를 활용해 Memory를 관리하는 것도 GC의 방법이다.
또한 Python에서는 Cyclic garbage Collection을 통해 순환 참조를 방지하는데, 순환 참조란 참조하는 대상이 서로 물려 있어 참조 할 수 없게 되는 현상을 말한다.
