Server
Server의 형태
- 모놀로식 아키텍처(Monolithic Architecture)
- 모든 작업을 1개의 서버에서 처리함
- 처리 작업 : Client에서 요청 받기, 요청에 대한 Output 생성, Output을 Client에게 Respond
- 모든 작업을 1개의 서버에서 처리함
- 마이크로서비스 아키텍처(Microservice Architecture-MSA)
- 각 역할마다 서버를 구성
- 서버마다 통신하며 전체 서비스를 수행하도록 구성하는 것
REST API
REST API란?
-
정보를 주고받을 때 널리 사용되는 형식
-
REST란?
- HTTP URI를 통해 자원을 명시함
- HTTP Method를 통해 통신함
- 자원(URI)에 대한 CRUD Operation을 적용하는 것
- CRUD: Create, Read, Update, Delete
- Request를 보고 어떤 작업을 요청하는 것인지 추론 가능함
-
Resource + Method + Representations of Resource
- Resource : Unique한 ID를 가지는 자원(URI)
- Method : 서버에 요청을 보내기 위한 방식
Resource(URI)
-
URI : 특정 Resource를 식별하는 식별자
-
URL : 리소스가 어디 있는지 알려주기 위한 규약
-
URI는 "식별"을 위한 것이며, URL은 "특정 위치"를 의미함
-
URL은 URI의 Subset
ex)
index.html파일을 접속하고 싶다고 가정하자. 이 때 우리는 'https://~/index.html' 로도 접속 가능하며,'https://~/index' 로도 접근 가능하다. 전자는 URI임과 동시에 URL이다. 왜냐하면 해당 파일이 /index.html에 존재함을 알리기 때문이다. 하지만, 후자는 주소 자체로는 index.html 파일인지, index.js 파일인지 알 수가 없다. 이런 연결 과정은 서버 내부에서 처리해주기 때문에, 식별을 위한 URI는 맞지만 리소스가 어디있는지는 알려주지 않으므로 URL은 아니다
HTTP Method
- GET : 정보를 요청(Read)
- URL에 변수(데이터)를 포함시켜 요청함
- Header에 데이터를 포함시켜 전송
- URL에 데이터가 노출되어 보안에 취약하지만, 캐싱이 가능함
- POST : 정보를 입력(Create)
- URL에 변수(데이터)를 노출하지 않고 요청
- Body에 데이터를 포함시켜 전송
- URL에 데이터가 노출되지 않아 조금 더 안전함
- 캐싱이 불가능하지만, Architecture적으로 수정을 가해 캐싱이 가능하도록 만들 수는 있음
- PUT : 정보를 업데이트(Update)
- PATCH : 정보를 업데이터(Update)
- PUT : Resource 전체에 대하여 Update가 수행됨
- PATCH : Resource 중 원하는 값에 대해서만 Update 수행함
- DELETE : 정보를 삭제(Delete)
REST API 특징
-
Server-Client 구조
-
Stateless : 작업을 위한 상태정보를 따로 저장하고 관리하지 않음
- 세션이나 쿠키 정보를 별도로 저장 및 관리하지 않으므로 들어온 요청에 대해서만 처리함
-
Cacheable
-
Uniform Interface : Resource에 대한 조작을 통일되고 한정적인 인터페이스로 수행하는 스타일
-
계층형 구조
REST API 디자인 핵심
-
URI는 정보의 자원을 표현해야 함
-
자원에 대한 행위는 HTTP Method로 표현함
-
URI는 "자원"에 집중해야지, 행위에 대한 설명은 부가되지 않는 것이 좋음
- (ex) GET /members/delete/1으로 요청을 보내기보다는 DELETE /members/1으로 보내는 것이 REST API적으로 잘 설계된 것
HTTP
-
정보를 주고 받을 떄 지켜야 하는 통신 프로토콜(규약)
- HTTP는 80 Port를 활용
- 서버에서 80 포트를 열어 놓지 않으면 HTTP 통신 불가능
-
HTTP를 통해 Request 및 Respond를 수행할 때 정보를 Packet에 저장하여 통신
-
Packet 구조 : Header + Body
- Header : 보내는 주소, 받는 주소, 시간 등
- Body : 실제 전달하고 싶은 내용(데이터)
- Body의 데이터 형식을 설명하는 Content-Type은 Header 필드에 존재해야함
- application/json : JSON 파일
- application/x-www-form-urlencoded : Body에 Key, Value 활용. & rnqnswk tkdyd
- text/plain : 단순 txt 파일
- multipartform-data : 데이터를 Binary Data로 전송
HTTP 응답 상태 코드
-
Client 요청에 따라 서버의 반응을 알려주는 Code
-
1xx(정보) : 요청을 받았고 프로세스를 진행하겠음을 알림
-
2xx(성공) : 요청을 성공적으로 받아 실행함
-
3xx(Redirection) : 요청 완료를 위해 추가 작업이 필요
-
4xx(클라이언트 오류) : (클라이언트측 실수로) 요청을 처리할 수 없음
-
5xx(Server 오류) : (Server측 문제로) 요청에 대한 응답에 실패함
동기 VS 비동기
-
동기 : 요청을 보낸 후 응답(결과물)을 받아야 다음 동작이 이루어지는 방식
-
비동기 : 요청을 보낼 때 응답 상태와 상관 없이 다음 동작을 수행함
-
비동기를 위해 AJAX나 setTimeout 등을 활용함
A() 메서드와 B() 메서드가 관련이 없는 메서드라고 생각하자. 만약, A() B()를 연속 해서 실행시키는데 A는 시간이 많이 걸리는 작업이고 B는 시간이 적게 걸리는 작업일 경우, B는 A가 실행이 다 될 때까지 억울하게 기다려야 할 것이다.
이런 방식을 "동기"라고 한다.
내가 먼저 도착했으면 쟤보다 빨리 수행됐을텐데... ㅂㄷㅂㄷ.....
이런 단점을 해결해주는 것이 "비동기"이다.
A()는 A나름대로 수행하고, 바로 B 메서드까지 수행시키는 것이다. 그러면 B메서드는 먼저 수행되었기 때문에 B에 대한 Respond를 먼저 줄 것이며, 나중에 A 메서드의 수행 결과를 제출해줄 것이다.
IP
-
Internet Protocol
- 인터넷 상에 사용하는 주소체계
-
네트워크에 연결된 특정 PC의 주소
-
4덩이의 숫자로 구성된 IP 주소 체계를 IPv4라고 함
-
몇가지 IP 주소는 용도가 정해져 있음
- localhost(127.0.0.1) : Local PC
- 0.0.0.0, 255.255.255.255 : Local에 접속된 모든 장치와 소통하는 주소
-
최근 IPv4 주소로 부족해져 IPv6가 나옴
Port
-
PC에 접속할 수 있게 하는 통로(Channel)
-
포트는 중복해서 활용할 수 없음
- Port 1개 당 허가할 수 있는 작업이 1개
- 국내인 검사장에 외국인을 통과시킬 수는 없음
-
0 ~ 65535까지의 Port가 존재하나, 이 중 통신에 의한 규약에 몇 개는 사용되고 있음
- 22 : SSH
- 80 : HTTP
- 443 : HTTPS
Path Parameter VS Query Parameter
웹에서 Get Method를 활용할 때 데이터를 전송하기 위해서는 "URI"에 정보를 담아 보낸다.
이 때 URI에 정보를 담는 방법에 Path Parameter 방식과 Query Parameter 방식이 존재한다.
-
Path Parameter
- URI에 "/" 아래에 정보를 담아 요청을 보내는 것
- 경로(Path)를 변수로서 활용
-
Query Parameter
- ? 이후 "값=쌍"형태 여러개를 &로 연결하여 요청을 보내는 것
- 경로 뒤에 입력 데이터를 따로 제공
- (key, Value) 쌍 1개를 Query String이라고 하며, Query String은 &로 연결하여 여러 데이터를 넘길 수 있음
-
예시로 보는 Path Parameter, Query Parameter
- 내가 ID가 100인 사용자 정보를 가져오고 싶다.
- Path Parameter : /users/100
- Query Parameter : /users?user_id=100
-
Resource 식별 시 차이점
위에서 ID가 100인 사용자 정보를 가져오는 예시를 생각해보자.
이 때, user ID가 100인 사용자가 없다고 가정해보자.
이 때 Path Parameter는 경로에 존재하는 내용이 없으므로 "404 Error"가 발생하며, Query Parameter는 해당 Query String에 적절한 데이터가 없으므로 빈 리스트가 나온다.
Path Parameter는 전해지는 데이터도 "경로"로 파악하기 때문에 데이터가 없을 경우 "잘못된 경로"라고 이해하여 404 Error를 내며, Query Parameter는 "데이터"가 온 것으로 파악하기 때문에, 데이터가 없을 경우 "입력 데이터에 해당하는 데이터가 없음"으로 이해하여 빈 리스트를 반환하는 것이다. -
그렇다면 언제, 어떤 것을 활용해야할까?
결론만 말하자면 Resource를 식별하는 상황에서는 Path Variable이 적합하며, 정렬이나 필터링을 해야 할 경우 Query Parameter가 적절하다
만약 정해지지 않은 값에 대한 요청이 올 경우 빈 쿼리를 내는 것보다는 404 Error를 내서 Client가 잘못된 요청을 보냈다는 것을 알리는 것이 User입장에서도, 관리자 입장에서도 편하다(User : 내가 잘못 입력했음을 알 수 있음, 관리자 : Request 내용을 보고 서버 관리가 수월해짐)
만약 내가 잘못된 입력을 보냈는데 빈 리스트가 오면 이게 데이터가 있는데 에러가 난건지, 빈 데이터 자체가 데이터인지 알 수가 없을 것이다(Optional한 값이라 빈 칸으로 놔뒀는데, 이 값을 요청할 경우에도 빈 리스트가 반환되므로)
Query Parameter는 "정렬"이나 "필터링"을 해야하는 경우에 적합하다고 말한다.
예를 들어 내가 기사를 모으는데 "AI"에 관련된 기사만 모으고 싶다. 이 때 news?category=AI라고 요청했을 때, 해당하는 데이터가 없다고 가정하자.
만약 news/AI로 입력했다면 404 Error가 발생할 것이다. 그런데 User는 이 에러가 "news"라는 경로가 존재하지 않는지, "AI"가 잘못된건지, 아니면 데이터 자체가 없는 것인지 알 수가 없다.
즉, 'news'라는 데이터는 존재하지만, AI 관련 기사가 없다는 것을 말해주기 위해서는 Query Parameter를 통해 빈 리스트를 반환해주는 것이 더 User가 보기에 적합할 것이다
FastAPI
Fast API 정의 및 특징
-
최근 떠오르는 Python Web Framework
-
High Performance
- Node.js, go와 비슷한 성능
-
쉬움
- Flask와 비슷한 구조
- MicroService에 적합
-
Productivity
- Swagger 자동 생성
- Pydantic을 활용한 Serialization
- Serialization : 객체 데이터를 Stream에 쓰기 위해 연속적인 데이터(Byte Stream)로 변환하는 것
- 목적 : 객체 상태를 그대로 저장하여 필요할 때 마다 다시 생성해 활용하기 위함
Fast API 장점
-
Flask보다 간결한 Router 문법
-
Asynchronous(비동기) 지원
-
Built-in API Documentation(Swagger)
- Docs를 자동으로 만들어준다는 것인데, 웹 개발자 입장에서는 매우 편리한 기능
-
Pydantic을 이용한 Serialization 및 Validation
Fast API 단점
-
아직은 다른 웹 프레임워크 사용자가 많음
-
ORM 등 Database와 관련된 라이브러리가 적음
Swagger
-
Postman과 같은 역할을 수행할 수 있게 만든 기능
-
해당 사이트를 "어떻게 활용해야하는지" 등에 대해 자동으로 Document를 만들어주며, 제대로 실행되는지 여부도 확인할 수 있기 때문에 편안함
-
REST API 설계 및 문서화할 때 활용
-
구축된 프로젝트를 유지보수하거나 다른 개발팀과 협업할 때 좋음
- 다른 개발팀에게 일일히 수행 방법, 접속 방법 등에 대해 설명하지 않아도 됨
- POST 요청 같은 것은 웹에서 확인하기 힘들어 Postman 등의 앱을 활용하는데, 별도의 앱 활용을 안해도 작동 여부 확인 가능
-
기능 : API 디자인, API 빌드, API 문서화, API 테스팅
-
아래 설명에 실행을 통해 자세히 확인 가능
Poetry
Poetry란?
-
Depndency Resolver
- 복잡한 의존성들에 의한 버전 충돌을 방지하기 위한 툴
-
Virtualenv를 생성하여 격리된 환경에서 빠르게 개발이 가능해짐
-
pyproject.toml을 기준으로 여러 툴들의 Config를 명시적으로 관리
-
Python 2.7이나 3.5+ 버전이 존재해야 활용 가능
poetry.lock
-
Writing lock file에서 생성되는 파일
-
이 파일을 활용하면 Local과 동일한 의존성을 가질 수 있음
- Github Repository에 커밋하여 협업자들에게 의존성(환경)을 공유할 수 있음
- 의존성 충돌을 줄임
-
poetry.lock 파일로 requirements.txt 파일 만들기
poetry export -f requirements.txt > requirements.txt
-
poetry.lock Update
- poetry.lock 파일을 Update함으로써 Dependency에 대한 충돌을 줄일 수 있음
poetry update: 패키지 Updatepoetry update --lock: poetry.lock 파일만 Update- 만약 poetry.lock과 pyproject.toml 파일이 다르다면 Poetry에서 따로 Warning 문구를 보내줌
- poetry.lock의 의존성을 가져야 충돌이 안나는데, pyproject.toml가 poetry.lock과 다르면 충돌이 날 가능성이 생김(이전 실험 환경임을 알림)
Poetry 프로젝트 생성하기
Poetry 설치
-
Mac OS / Linux
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python -
Windows(Powershell)
(Invoke-WebRequest -Uri https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py -UseBasicParsing).Content | python -- 설치 후 재시작을 해야 PATH에 적용되어 활용 가능
-
Pip을 활용한 설치
pip install --user poetry
프로젝트 init
-
사용할 라이브러리를 지정하는 과정
-
대화 형식으로 Package 설치 가능
- 패키지 이름 검색 및 선택
- 패키지 버전 명시
- Dependency
- Production, Dev용을 따로 설치할 수 있음
- 테스트 때 활용하는 pytest 패키지는 Production 환경에는 설치할 필요 없음
- 개발 환경마다 필요한 패키지 분리 가능
-
설치한 패키지 목록은
pyproject.toml에 저장됨
실행 화면
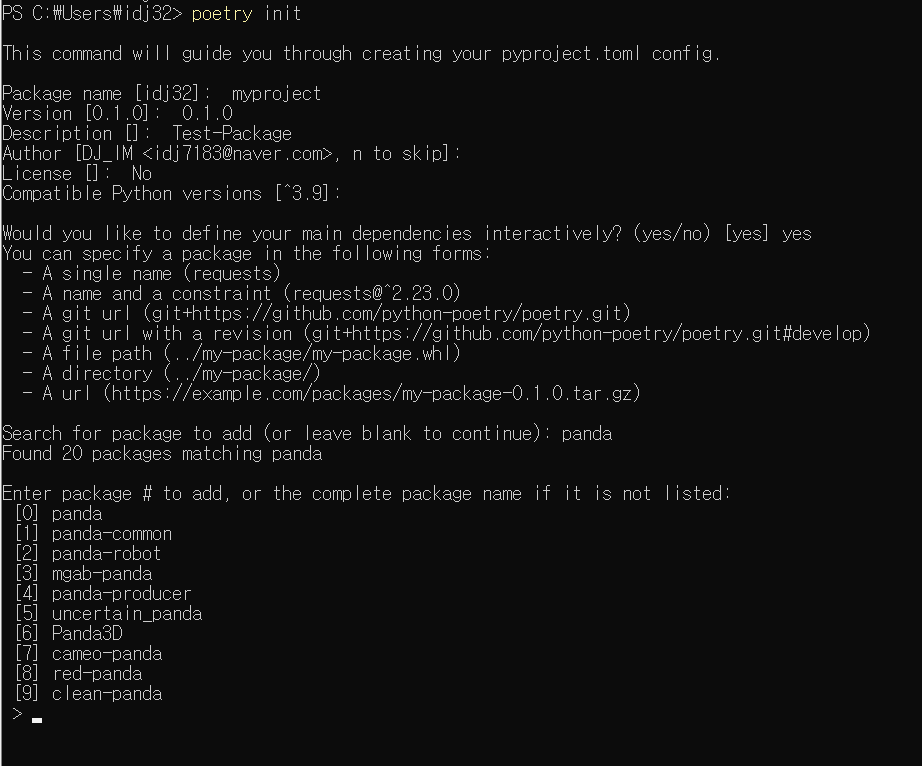
-
poetry init을 수행했을 때, 만약 toml파일이 없는 경우라면 Package name, Version 등에 대한 정보를 입력하도록 한다. 아무렇게나 써도 큰 문제가 없는 것은 확인했지만, 이왕이면 구분을 위해 입력해주자 -
Search for packages to add부분을 보자. 이 곳에 내가 원하는 설치 라이브러리 이름을 입력하면, 아래 부분에 [0] ~ [9]까지 list가 나옴을 알 수 있다. 여기에서 "내가 원하는 라이브러리"를 선택하면 된다.
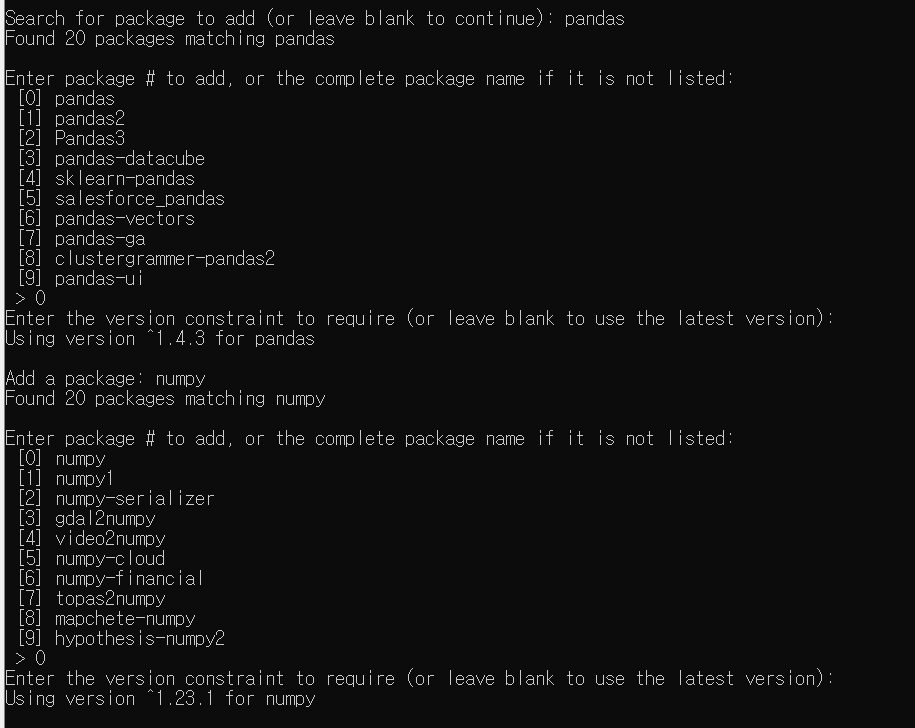
-
Pandas와 Numpy를 설치해봤다. 원하는 라이브러리 List의 숫자를 입력 후 엔터를 치면 설정되며 Version을 선택할 수도 있다. 만약, Version을 선택하지 않고 엔터를 치면 최신 버전으로 설치한다.
-
설치할 라이브러리를 모두 선택했다면 "Add a Package"를 물어보는 구간에서 Blank(엔터)를 누르면 다음 질문으로 넘어간다
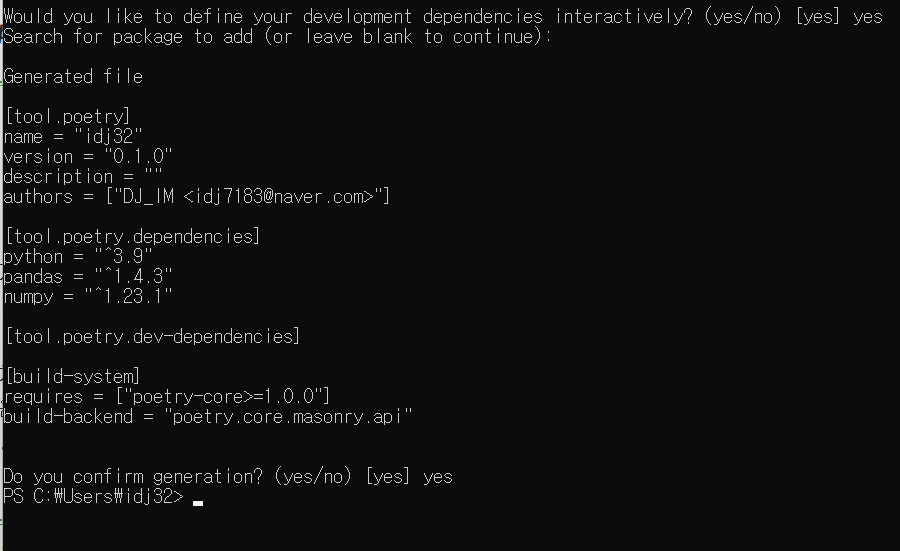
-
Development Depndency를 설치할 것이냐는 질문을 하는데, 이는 "Dev용 서버"를 만들 것인지 묻는 것이다. 만약 만든다면, Dev용 서버에서만 설치할 라이브러리를 입력하면 된다
-
Generated file은 곧 pyproject.toml의 내용과 동일하다.
cat pyproject.toml을 통해 파일을 보면 동일하게 입력되어 있음을 알 수 있다
Poetry Shell 활성화
poetry shell: Poetry를 활성화

Poetry Install
poetry installpyproject.toml에 저장된 내용을 Base로 라이브러리 설치
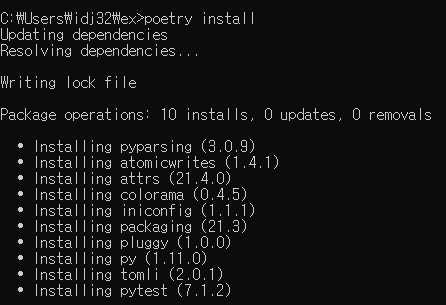
-
pyproject.toml파일에 존재하는 모든 라이브러리에 대한 정보를poetry.lock에 저장시키고, 라이브러리를 설치함 -
poetry.lock파일만 항상 일치한다면poetry install명령어를 통해 의존성 관리를 최신으로 할 수 있음
Poetry Add
-
poetry add {설치할 라이브러리} -
Poetry 환경에서 실험을 진행하던 도중 모듈(라이브러리)을 추가하고 싶을 경우 사용하는 명령어
-
Poetry Add로 필요한 패키지를 추가할 경우 설치가 진행되며, 자동으로
pyproject.toml파일도 Update됨
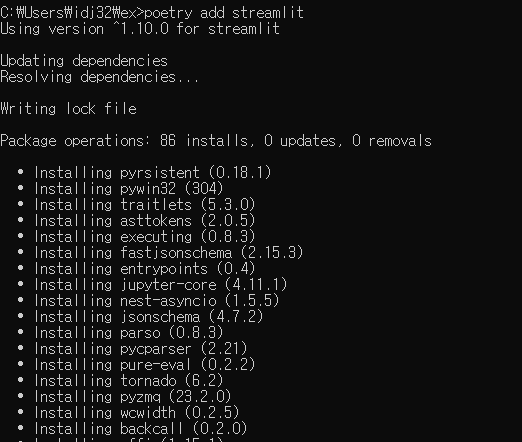
poetry add명령어를 활용하면 Dependency 추가를 할 뿐만 아니라 자동으로 설치까지 진행되는 것을 알 수 있다
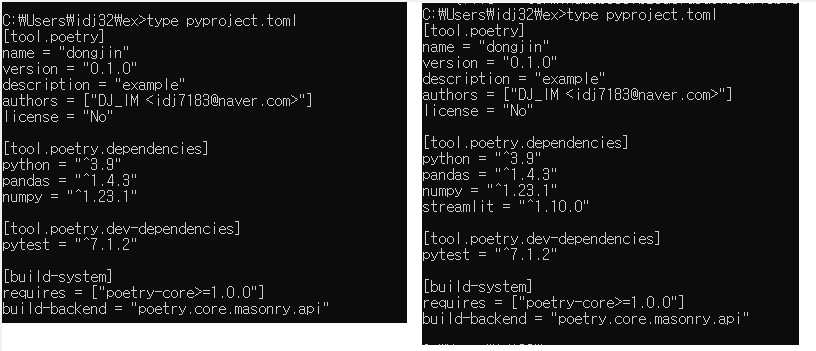
- 왼쪽은
poetry add이전, 오른쪽은 명령어 수행 이후 pyproject.toml 파일이다.
tool.poetry.dependencies를 보면 streamlit이 새로 생겨났음을 볼 수 있다
