
날짜별 프로젝트 진행
2/21
- 요약
EDA를 진행하며 Data가 어떤 형식으로 구성되어 있고, 어떤 형식으로 되어 있는지 판단하였다. 그리고 pandas를 활용하여 CSV 파일을 읽어오고, 내가 원하는 대로 변형시켜 Model에 먹일 Data 형태로 변형시키는 코딩을 수행하였다. - 자세한 수행점
- EDA
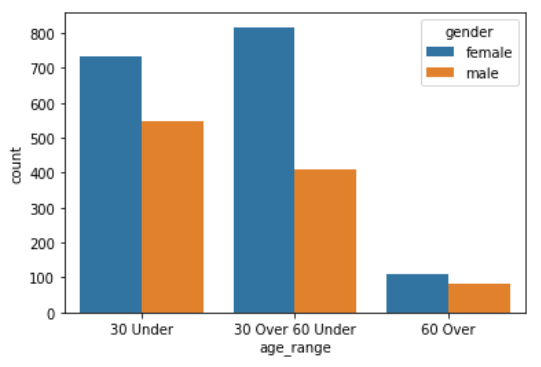
Data가 매우 Imbalance하다는 점을 알게 되었다. 특히 60 Over된 사람의 Image가 매우 적기 때문에 이런 Imbalance를 처리하는 것이 1차적 목표라고 생각했다. 그리고 AI Stages의 토론 게시판을 확인하며 Data 중 Miss Label 된 것이 있다는 것을 알게 되었으며, 이 또한 시간이 된다면 처리해야된다고 생각하였다. 또한 Data의 양이 매우 적은 편에 속하므로, Overfitting에 주의해서 코드를 짜야겠다는 생각이 들었다. - Dataset
Data 자체는 Image Path로 지정해 주었다. Label을 결정하는데 조금 애를 먹었다. 0 ~ 17까지 정리된 Label을 보며 어떻게 하면 Label을 결정할 수 있을지 조사했다. 그리고 Label은 "Age", "Gender", "Mask 착용 여부"를 조합하여 만들 수 있다는 것을 알게 되었다. 따라서 Pandas Mapping을 활용하여 아래와 같은 값을 가지게 바꾸어 서로를 더해주었다.
male : 0, female : 3, age < 30 : 0, 30 <= age < 60 : 1, x > 60 : 2
(ex) male & age < 30 = 0 + 0 = 0
이후 Mask1 ~ Mask5 파일은 마스크를 제대로 쓰고 있는 상황이므로 위에서 구한 값을 그대로 Label로 넣어줬으며, incorrect_mask 파일은 위에서 구한 값에 6을 더해줬으며, normal은 mask를 쓰지 않은 상태이므로 위에서 구한 값에 12를 더해주어 Label을 결정하였다.
- EDA
- 잘했다고 생각한 점
EDA를 처음 한 것 치고는 Data 분포나 활용 방법을 꽤 확실히 파악했다고 생각한다. 실제로 Data 분포 등 Data 자체의 문제로 문제가 생긴 적은 없었다. 또한 이런 Imbalance Data를 해결할 방법 등을 생각해보며 많은 생각을 해보기도 하였다. - 아쉬운 점
우리 팀에서 데이터 시각화를 너무 잘한 팀원이 있어서 조금 비교되었다. 데이터 시각화를 제대로 하는 것은 저렇게 하는 것이라는 것을 알게 되었으며, 다음부턴 다른 사람에게 보여준다는 생각으로 데이터 시각화를 조금 더 잘 해야겠다는 생각이 들었다. - 배운 점
속도 향상을 위해 이미지를 Image.open() 까지 수행하여 array 형태로 GPU에 넣어봤는데, OOM 문제가 발생하였다. 따라서 Image 관련 AI Model은 Dataset을 형성할 때 Image Path를 Data로 저장한다는 것을 알게 되었다.
Batch Size가 너무 크면 OOM이 발생한다는 것을 알게 되었다. 학습 속도가 너무 느려 256이나 512도 실험해봤는데 OOM이 발생하였다. 멘토님께 여쭤보니 256, 512는 너무 큰 Batch Size라고 말씀해주셨다. 이후 64나 32만 활용하여 OOM을 더 이상 보지 않을 수 있었다.
2/22 ~ 2/24
- 요약
Pretriaed Model이 아닌 나만의 Custom Model을 형성하여 25일에 만들어진 Data를 먹여 학습을 진행하도록 해보았다. - 자세한 수행점
내가 만든 모델은 가장 기초적인 CNN으로 Conv2D, BatchNorm, ReLU, MaxPool2d, Dropout2d를 활용하였다. Loss Function은 CrossEntropyLoss를 활용하였으며, Adam Optimizer를 활용하였다.
문제는, Data를 Image.open()으로 열면 Channel이 (A,B,C,D)에서 D 위치에 존재하게 된다는 것을 알게 되었다. 내가 지금까지 배운 Image Data는 B 위치에 Channel 개수가 존재하였기 때문에 이를 변경시켜줘야 할 필요가 있었다. 따라서, permute(0,3,1,2)를 활용하여 Array의 형태를 변형시켜 주었다. 나중에 알게 되었지만, Transform의 ToTensor()를 활용하면 자동으로 이 과정도 수행된다고 한다(즉, Channel이 B 위치에 존재하도록 변환됨)
이렇게 만든 Model을 활용하여 Evaluation 파일까지 돌려보았고, 결과를 제출까지 해보았다. 물론 Accuracy가 높게 나오지는 않았지만 내가 만든 Custom Model이 실제로 활용 가능하다는 것을 알게된 매우 소중하고 기쁜 경험이였다. - MyModel(CNN 활용)
class MyCNN(nn.Module):
def __init__(self, name='cnn', xdim = [3, 512, 384], ksize = 3, cdims = [32, 64],
hdims = [1024, 128], ydim = 18, USE_BATCHNORM=False):
super(MyCNN,self).__init__()
self.name = name
self.xdim = xdim
self.ksize = ksize
self.cdims = cdims
self.ydim = ydim
self.hdims = hdims
self.USE_BATCHNORM = USE_BATCHNORM
self.layers=[]
prev_cdim = xdim[0]
for cdim in self.cdims:
self.layers.append(
nn.Conv2d(in_channels=prev_cdim,
out_channels=cdim,
kernel_size=self.ksize,
stride=(1,1),
padding = self.ksize//2))
if self.USE_BATCHNORM:
self.layers.append(nn.BatchNorm2d(cdim))
self.layers.append(nn.ReLU(True))
self.layers.append(nn.MaxPool2d(kernel_size=(2,2), stride=(2,2)))
self.layers.append(nn.Dropout2d(p=0.5))
prev_cdim = cdim
self.layers.append(nn.Flatten())
prev_hdim = prev_cdim*(self.xdim[1]//(2*len(self.cdims)))*(self.xdim[2]//(2**len(self.cdims)))
for hdim in self.hdims:
self.layers.append(nn.Linear(prev_hdim, hdim, bias=True))
self.layers.append(nn.ReLU(True))
prev_hdim = hdim
self.layers.append(nn.Linear(prev_hdim, self.ydim, bias=True))
self.net = nn.Sequential()
for i_idx, layer in enumerate(self.layers):
layer_name ="%s_%02d"%(type(layer).__name__.lower(),i_idx)
self.net.add_module(layer_name, layer)
self.init_param()
def init_param(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight,1)
nn.init.constant_(m.bias,0)
elif isinstance(m, nn.Linear):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
def forward(self,x):
return self.net(x)- 잘했다고 생각하는 점
물론 이전 수업 코드를 많이 활용하긴 했지만, 그래도 나만의 Custom 모델을 만들어 Model에 데이터를 먹이고, Dimension이나 Channel을 맞추며 실력을 많이 길렀다고 생각한다. - 아쉬운 점
다음 날(2/25)부터 Pretraiend Model을 활용하며 알게 되었지만, Pretrained Model의 효율이 압도적으로 좋다. 후회라기보다는 그냥 이 CNN은 대충 기법만 이해하고 처음부터 Pretraiend Model을 활용했다면 조금 더 많은 모델을 활용해보고 조금 더 많은 HyperParameter를 활용해서 성능 향상에 도전해 볼 수 있지 않았을까 하는 아쉬운 생각이 들긴 했다. - 알게 된 점
Weight의 Tensor Type과 Data의 Tensor Type이 동일해야 한다는 것을 알게 되었다. 가장 많이 본 Error가 Weight은 Double Tensor인데 Data는 Float Tensor이므로 연산이 불가하다는 에러였다. 항상 Tensor Type을 고려하며 코드를 짜야겠다는 생각을 하였다.
permute()를 통해 Channel을 옮기는 것도 활용해보았고, 실제로 코드를 짜보며 Dropout, ReLU, BatachNorm, Conv2D 등 많은 Built-in Function을 활용해보는 좋은 기회였다.
2/25 ~ 3/2
-
요약
많은 Pre-Trained Model을 활용해보며 결과를 예측하였다. 처음에는 Tensorboard가 안되어 어쩔 수 없이 메모장에 최종적인 결과를 적어 비교하였지만, 나중에는 WandB도 활용하였다. -
자세한 수행점
- Base Line Code 분석
원래 Base Code가 발표되기로 한 목요일까지는 최대한 나만의 코드를 짜보겠다는 쓸데없는 고집으로, 2/25부터 Base Line Code를 분석하였다.
Base Line Code를 보며 든 생각은 이런 걸 어떻게 구현했지? 라는 생각밖에 없었다.
내 코드와 비교해봤을 때 너무나 효율적이며, 객체화가 잘 된 완벽한 코드였다. 2/24까지 내가 수행했던 내용이 살짝 부끄러워지는 아름다운 코드였다.
Base Line Code를 분석하며 이 코드가 Early Stopping과 Cross Validation까지 구현했다는 것을 알게 되었다.
사실 개념만 알고 있었고, 실제로 이 코드가 Cross Validation 기법을 활용했다는 것은 블로그 정리를 할 때까지도 몰랐었다. 이 때 개념을 아는 것도 중요하지만 "확실히" 아는 것도 중요하다는 생각이 들었다. - WandB의 활용
Tensorboard 접근 불가 문제로 반나절을 태우며 고민했는데 결국 해결되지 않아 지금도 매우 찝찝하긴 하다. 비슷한 문제를 해결했던 팀원에게 해결 방법을 물어봤지만 그 방법으로도 해결되지 않았고 공식 질문 게시판에도 비슷한 질문이 있어 그 방법으로도 해결을 시도해봤지만 해결되지 않아 결국 처음엔 메모장에 실험 결과를 기입하였다.
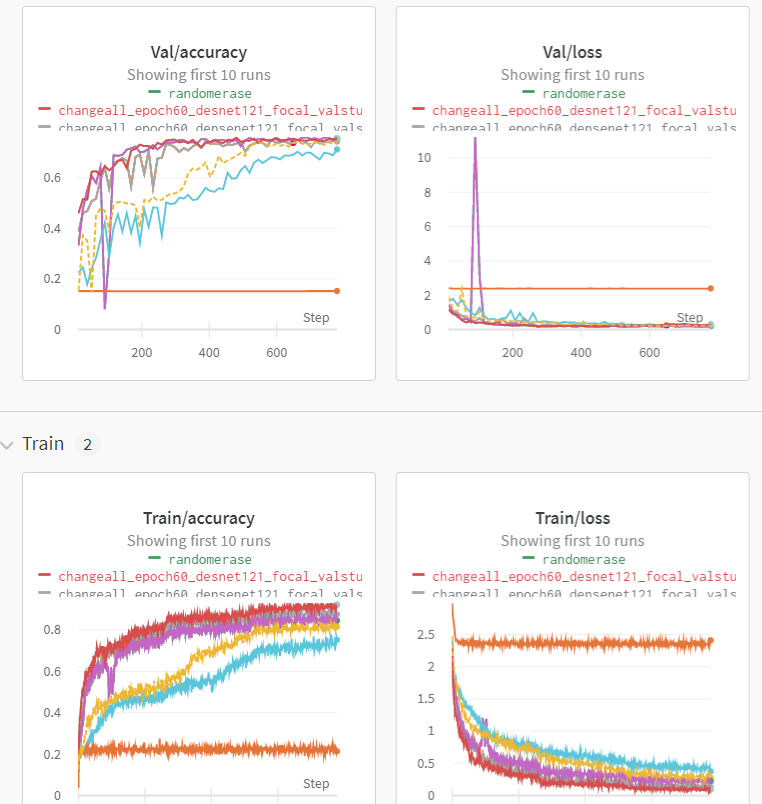
나중에(3/1) 실험을 여러 번 돌리는 것에 지친 나는 한 번 WandB에 대해 활용해볼까?라는 생각이 들어 wandb에 대해 공부한 것을 토대로 WandB 설정을 끝마쳤다. 이후 WandB로 실험 결과를 보니 매우 편리했다. 특히 Loss에 대한 경향성을 파악하고, 어디에서 학습을 끊어야 할지 확인할 수 있다는 점이 매우 매력적으로 느껴졌다. 동시에 처음부터 WandB를 활용하려는 시도를 했다면 어땠을까 라는 생각을 했다. - 활용한 Pre-Trained Model 및 활용 이유
- ResNet : AI Stages 토론 게시판에서 문제 해결을 위해 가장 먼저 나온 Model이였기 때문에 활용해보았다. 특히 Resnet18, Resnet34 등 많은 Resnet을 활용해보았다.
- DenseNet : ResNet을 활용해보며 ResNet에서 도출된 DenseNet을 활용해보자는 생각이 들었다. '+' 연산이 아닌 Concat을 활용하는 Model이므로 Data 손실이 적어지지 않을까 하는 기대감 때문에 활용하였다. 특히 Data의 절대적 수치가 부족한 상황에서 Data 손실이 조금이라도 적어질 것 같은 DenseNet을 활용을 진지하게 고민하였다.
- VGG : ResNet 보다 매우 이전에 나온 초기 모델이지만 Pre-Trained Model과 내가 만들고 싶은 Model은 서로 다른 목표를 가지기 때문에 오히려 초기에 나온 Model은 학습 Accuracy가 더 낮을 것이니 내가 조금 Layer를 추가하면 더 좋아지지 않을까라는 뇌피셜로 시도해 본 Model이였다.
-
txt 파일에 한 여러 가지 실험들
EPOCH 10번. 나머지는 Default nn.Linear만 Resnet에 붙였을 경우 : 70.08% nn.Conv2D만 Resnet에 붙였을 경우 : 71.63% nn.Linear를 활용해 여러 Layer : 69.64% -> Overfitting의 위험성까지 고려해보면 안하는게 맞곘다! Conv2D를 활용해서 여러 Layer : 69.64% 그런데, Epoch 늘려서 실험은 한 번 더 해보긴 하자 60 Epoch nn.Linear 1개 Layer를 추가한 Model : 76.61% nn.Linear 1개 Layer를 추가한 Model : 77.02% - -> 왜 이게 더 좋게.. Flatten해도 좋으면 이거 써야겠다 nn.Linear 3개 Layer & Flatten을 활용한 Model : 77.28% nn.Linear 1개 Layer & Flatten을 활용한 Model : 76.67나중에 후회할 점에 쓰겠지만, 너무 큰 편견을 가지고 있어서 실험 결과를 가지고 판단하지 않고 내 주관에 실험 결과를 맞추려고 실험을 한 것 같다. 이번 프로젝트에서 두고두고 매우 후회되는 부분이다.
Trnasform 활용 아무것도 활용하지 않음 : 75.09% RandomHorizontal : 76.49% RandomPerspective : 75.20% RandomRotation : 75.32% Validation Set을 변경해야 한다!Cross Validation을 위해 Data를 쪼갤 때, transform을 적용하면 Validation Data에도 해당 Transform이 적용되는 문제점이 존재했다. 예를 들어, Random GrayScale을 활용했을 때 Validation Set에도 흑백 사진으로 데이터가 바뀌는 경우가 존재했다. Validation Set은 무조건 원래 Image와 가까워야 하므로, Transform되면 안되기 때문에 Validation Data과 Train Data에 서로 다른 Transform을 적용하기 위해 코드를 짰다.
Loss Function(모두다 3 Layer로 수행함) 지금까지의 실험 결과 : 모두 CrossEntropy Focal Loss : 76.90% F1 Loss : 활용하고 싶었으나 학습이 제대로 진행되지 않는 것 같아 활용하지 못할 것 같음나의 한계점이 조금 드러났던 실험이였다. Focal Loss와 CrossEntropy는 모두 이미 구현되어 있으므로 쉽게 활용 가능했지만 F1 Loss 같은 경우 조금의 Custom이 필요했다. 하지만 내가 한 Custom 방식으로는 제대로 된 학습이 수행되지 않아 결국 버리게 되었다. 나중에 설명을 들을 때 F1 Loss를 활용했다는 것을 듣고, 꼭 제대로 공부하여 더 많은 기법을 다양한 곳에 활용해야겠다는 생각을 하였다
Pretrained Model vgg19 : 시간이 진짜 오래 걸린다. 77.81% -> 활용... 괜찮을지도? densenet : 77.20% mnasnet1_0 : 37%나의 착각이 작은 불이였다면, 이 착각에 기름을 부어버린 실험 결과 였다. mnasnet의 정확도가 매우 낮게 나오고 densenet 보다는 vgg가 Accuracy가 더 높게 나와 이후 이틀 동안 VGG를 기준으로 코드를 짰다.(위에서 말한 나의 가정이 맞는 줄 알았다)
하지만, 훗날 WandB를 활용했을 때 나의 잘못짠 코드와 우연한 결과의 환장의 콜라보라는 것을 알게 되었고, WandB의 유용성을 앎과 동시에 실험에 내 개인적인 생각이 들어가면 안되겠다는 생각을 하였다.val 마지막에 합친 것 : 77.40 focal + vgg : 77.40 val 마지막에 합침 + focal + vgg : 76.87% vgg + Only Linear : 77.55% val 마지막에 합침 + vgg + Only Linear + focal : 77.55%Cross Validation 기법에서 Train Data를 가장 마지막 3번 학습 때 활용하겠다는 생각으로 코드를 짜 실험을 수행하였다.
내가 Cross Validation에 대해 매우 무지했다는 것을 알게되는 실험 결과이다. 훗날 프로젝트를 피드백하면서 매우 부끄러운 부분이였다.densenet 활용해보기 -> 유용할만 하다. 활용해보자 shufflenet 활용해보기 -> 유용하긴 하지만 Loss가 맘에 안 듬. 너무 높다 focal(혹시 모르니..) 활용해 보기 -> 생각보다 경향성이 괜찮다. 활용할까? vgg도 활용은 해보자.(시간 남으면) -> 개쓰레기vgg로 짠 코드를 자신만만하게 제출했지만 정확도가 더 낮아져 나의 생각이 틀렸다는 것을 알게 된 이후 다시 여러 Model을 활용하여 실험 한 결과이다.
-
WandB를 활용한 여러 가지 실험
- WandB 사이트 : https://wandb.ai/violetto/PProject?workspace=user-violetto
- 해 본 시도가 너무 많아서, wandb 사이트를 올린다.
- 이전에 가장 좋았던 Model에서 추가시킨 부분을 Name에 추가시켜 Chart를 그렸다.
- Base Line Code 분석
-
잘했다고 생각한 점
정말 내가 할 수 있는 최대한의 실험을 해봤다고 생각한다. 물론 아는 것이 다른 사람보다 적어 활용할 수 있는 툴이 적었다는 것도 고려했어야 겠지만, 그래도 많은 Model을 활용했고 이를 통해 AI 프로젝트에 대한 자신감이 생겼다는 것이 가장 큰 소득이 아니였나 싶다.
또한 WandB에 대해 완벽히 파악했다는 것이 좋았다. 최소한 다음 팀에 가서도 WandB는 내가 담당할 수 있을 정도로 공부하였고 활용해봤기 때문에 많은 자신감이 생겼고, 다음부터는 프로젝트 초기부터 Loss에 대한 경향성을 파악하며 실험할 수 있다는 것이 가장 큰 이득인 것 같다. -
아쉬운 점
아쉽기도 하고, 나에게 매우 큰 교훈을 준 기간이였다.
먼저, 편견을 버려야 한다는 생각을 했다. 3/3 가장 점수가 높게 나온 코드를 분석해보니 1개 Layer만 추가하였음을 알 수 있었다.
나는 무조건 Layer가 여러 개 있으면 좋을 줄 알고 일부러 3개 Layer를 추가시키고, 이 상황에서 가장 높은 Accuracy를 가지는 상황을 찾았다. 또한, Epoch을 10번도 돌리지 않았는데 가장 높은 Accuracy를 가지게 된다는 것이 정말 이해가 되지도 않았다. 내가 생각하는 AI는 최소 30~40번의 학습을 통해 완벽한 학습이 진행될 것이라고 착각했기 때문이다.
하지만 결론적으로는 제일 좋은 코드에서는 절대 epoch이 20번을 넘지 않았으며, 나중에 내가 따로 짜본 1층 Layer를 WandB로 경향성 파악을 해보니 Loss도 매우 좋고 Accuracy도 더 높게 나왔음을 알 수 있었다.
매우 후회된다. 앞으로 실험할 때는 절대 편견을 가지지 말고 무념무상으로 실험한 뒤 실험 결과를 스펀지처럼 흡수하며 생각을 발전시켜 나가야겠다. -
배운 점
EfficientNet이라는 Model의 존재를 알게 되었다.
WandB의 활용 방법과 유용성을 알게 되었다.
3.3
- 요약
가장 높은 점수를 가진 코드(김소연 캠퍼의 코드)를 바탕으로 마지막 성능을 쥐어짜는 역할을 수행해 보았다. 특히 Mutli Sample Dropout을 활용하여 성능을 높이는 것을 구현했다. - 자세한 구현점
먼저, WandB를 활용하여 팀끼리 프로젝트 상황을 공유하도록 설정하였다. 시간이 조금 걸리기는 하였지만 결국 WandB 설정을 끝마치고 나에게 주어진 역할을 수행하였다.
나에게 주어진 역할은 Multi Sample Dropout을 해보는 것이였다.
Multi Sample Dropout에 대해서 처음 들어보는 개념이였기 때문에 먼저 블로그와 논문을 읽으며 많이 개념을 정리했다. 이후 코드에 적용해보며 WandB에 경향성을 파악했다.
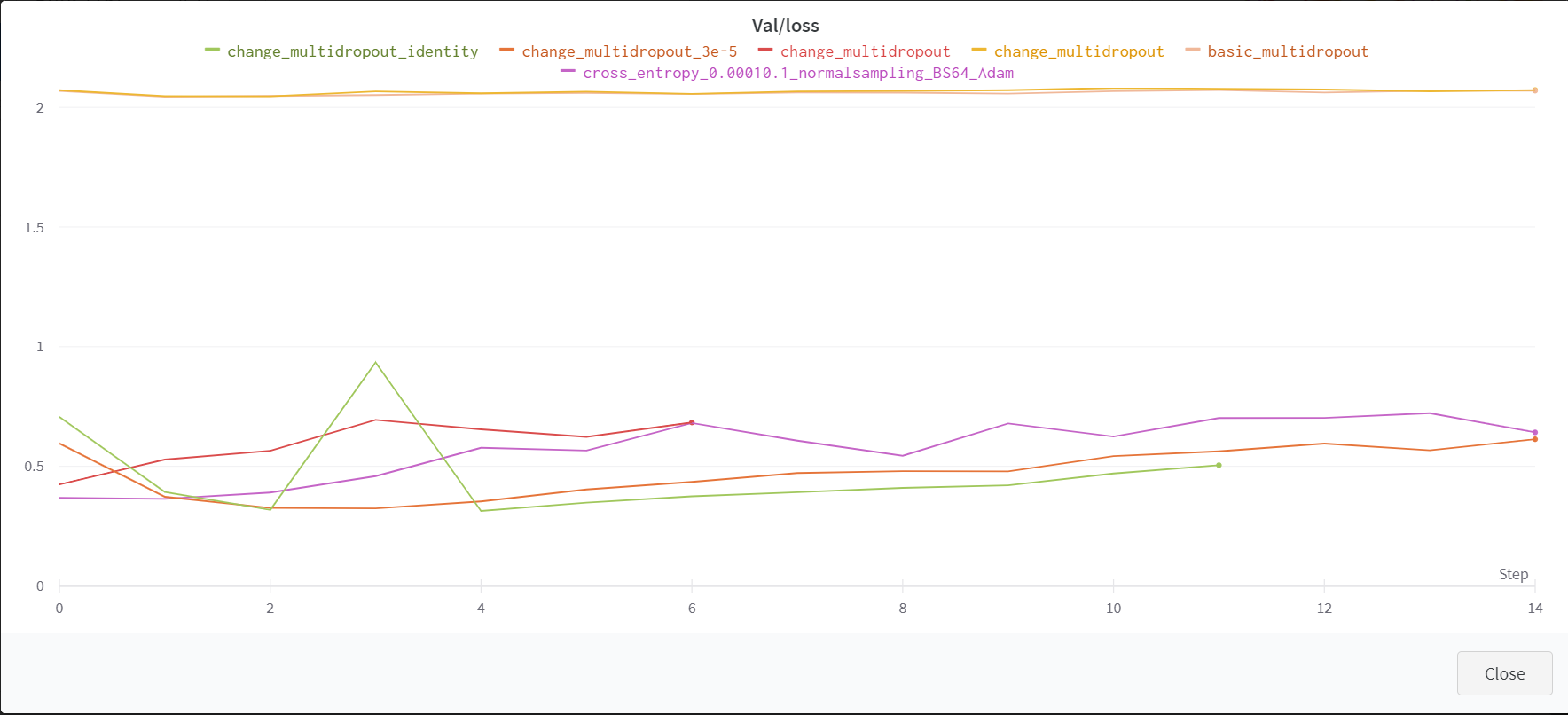
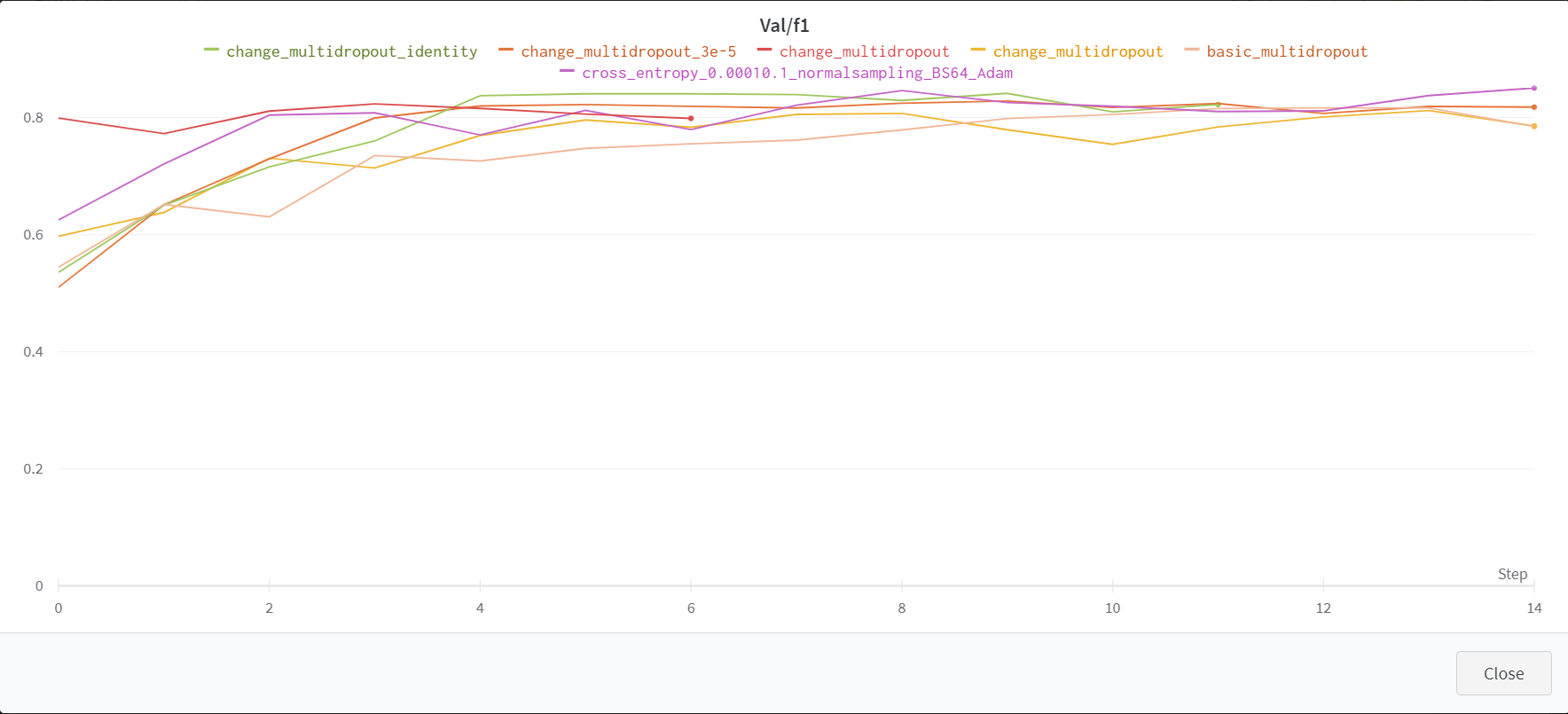
먼저, 가장 기본적으로 Drpout 2개를 설정하고 평균을 구하는 방법을 파악했다. 이 때는 0.7, 0.5의 Dropout p를 설정하였다. 하지만, 오히려 성능이 떨어지는 것을 알았다.
그래서 블로그의 기본 개념이 아닌, Multi Sample Dropout에 대한 실험 결과를 정리한 논문을 읽었다.
내가 읽은 논문에서는 Dropout 8개를 설정하고, 또한 Dropout이 0.3이나 0.2의 p를 가질 때 가장 높은 효율을 가짐을 알 수 있었다. 이를 팀원에게 공유하며 최종적으로 8개의 Dropout을 활용하고 각각의 확률은 0.3으로 지정하기로 하였다.
경향성 자체는(특히 Loss) 더 좋아져서 이를 제출해 보았다. 그런데 점수는 더 낮게 나왔다. 결국 경향성은 중요한 평가 지표지만, 경향성이 좋다는 것이 꼭 성능의 향상을 가지고 온다는 것은 보장하지 못한다는 것을 알게 되었다.(특히 Accuracy를 쥐어짜는 상황에서)
- 잘했다고 생각하는 점
Multi Sample Dropout을 처음 알게 된 개념이였지만 짧은 시간 동안 공부를 잘 하여 최대한 코드에 녹아들도록 수행한 것 같았다.
또한 다른 캠퍼의 코드를 빠른 시간 안에 분석하여 해당 코드의 구조를 이해하고 코드를 변경시켜 봤다는 점에서 매우 유용했던 것 같다. - 아쉬운 점
다른 사람의 코드를 읽고, 그 코드를 분석하여 원하는 대로 변경해보는 것도 매우 큰 경험이 된다고 생각했다. 이런 것도 큰 경험이 된다는 것을 알았다면 3/2일부터, 즉 하루 전부터 총 이틀 동안 이 과정을 수행했으면 좋았을 것 같다는 생각이 들었다.
