Java 8, Stream 사용
Stream
- Java8부터 추가된 Collection의 저장 요소를 하나씩 참조해서 Lambda식(함수형 프로그래밍)으로 처리할 수 있도록 해주는 반복자
- InputStream, OutputStream과 헷갈리면 안된다!! 전혀 다른것!!!
Stream 종류

사용법
- 구성
- 스트림 생성
- stream
- 중간 연산
- filter, map, limit, sorted
- 최종 연산
- collect, count, average, reduce, anyMatch, forEach ....
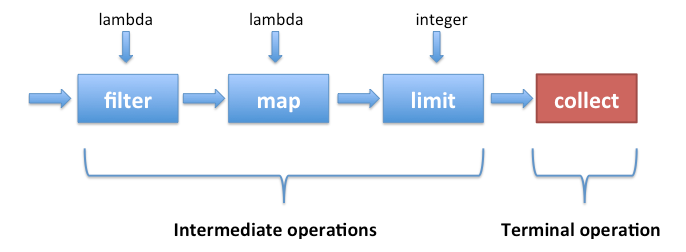
- 스트림 생성
- 처리 되는 과정 (pipeline)
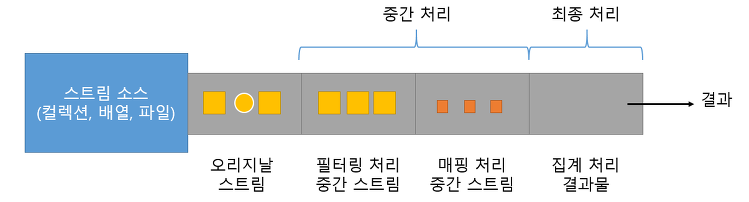
- 중간 스트림이 생성될 때 요소들이 바로 처리되는 것이 아님.
- 최종 처리가 시작되기 전까지 중간처리는 지연(lazy)되며, 최종 처리가 시작되면 중간 스트림에서 처리를 시작한다.
- return type이 Stream이라면 중간 처리 메소드이고, return type이 기본타입 이거나 OptionalXXX라면 최종 처리 메소드이다.
- 쇼트 서킷 : stream 처리중 중단함으로써 연산을 줄일 수 있음
- 연결 순서가 중요
- stream은 한번 사용하면 재사용이 불가능하다.
## 예제는 filter라는 중간 연산만 있어서 실제 실행되지 않는다.
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
});
## forEach는 최종 연산이 있어 실제로 실행되어 결과가 나온다.
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return true;
})
.forEach(s -> System.out.println("forEach: " + s));
## 결과 : 신기하게도 각 항복별로 filter-forEach의 pipeline으로 실행되는 것을 볼수 있다.
filter: d2
forEach: d2
filter: a2
forEach: a2
filter: b1
forEach: b1
filter: b3
forEach: b3
filter: c
forEach: c## anyMatch에서 Start가 'A'인 것이 있으면 종료되는 Stream을 구성한것으로 아래 경우 2번만 실행되는것으로 map의 동작도 2번만 실행하게된다.
## 따라서 스트림 모든 원소를 대상으로 map이 최대한 적게 실행된다.
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.anyMatch(s -> {
System.out.println("anyMatch: " + s);
return s.startsWith("A");
});
// map: d2
// anyMatch: D2
// map: a2
// anyMatch: A2## map - filter 순서로 비효율적임
Stream.of("d2", "a2", "b1", "b3", "c")
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("A");
})
.forEach(s -> System.out.println("forEach: " + s));
// map: d2
// filter: D2
// map: a2
// filter: A2
// forEach: A2
// map: b1
// filter: B1
// map: b3
// filter: B3
// map: c
// filter: C
## filter - map 순서로 효율적으로 변경
Stream.of("d2", "a2", "b1", "b3", "c")
.filter(s -> {
System.out.println("filter: " + s);
return s.startsWith("a");
})
.map(s -> {
System.out.println("map: " + s);
return s.toUpperCase();
})
.forEach(s -> System.out.println("forEach: " + s));
// filter: d2
// filter: a2
// map: a2
// forEach: A2
// filter: b1
// filter: b3
// filter: c- 일반적인 객체 stream이 아닌 int, long, double과 같은 특수한 종류의 stream을 만들수 있음
- 참고로 Function 대신, IntFunction, Predicate대신 IntPredicate를 사용
IntStream.range(1, 4)
.forEach(System.out::println);사용예
- stream을 사용하지 않았을때, (외부 반복자 : for, iterator, wile)
int sum = 0;
int count = 0;
for(Employee emp : emps) {
if (emp.getSalary() > 100000000) {
sum += emp.getSalary();
count++;
}
}
double average = (double) sum / count;- stream을 사용했을때, (내부 반복자)
double average = emps.stream() # return type : Stream<Employee>
.filter(empp -> emp.getSalary() > 100000000)
.mapToInt(Employee::getSalary) # return type :IntStream
.average() # return type :OptionalDouble
.orElse(0); # return type :double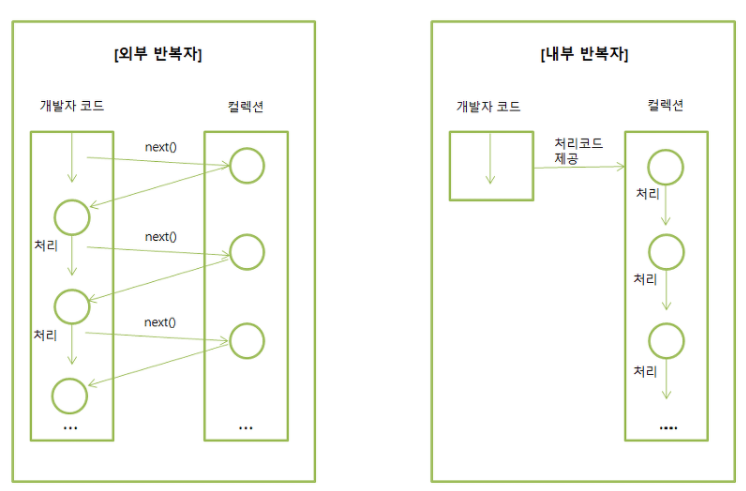
함수 예
- Optional Class
Optional 클래스는 저장하는 값의 타입만 다를 뿐 제공하는 기능은 거의 동일
디폴트 값을 설정할 수 있고, 집계 값을 처리하는 Consumer도 등록할 수 있다.
double avg = list.stream()
.mapToInt(Integer::intValue)
.average()
.orElse(0.0); // 값이 저장되지 않을 경우 defulat 0.0
list.stream()
.mapToInt(Integer::intValue)
.average()
.ifPresent(a -> System.out.println(a)); // 값이 존재하면 출력- reduce
reduce는 스트림의 모든 원소들을 하나의 결과로 합친다.
int sum = sutentList.stream()
.map(Student :: getScore)
.reduce((a,b) -> a+b)
.get();- collect
collect 메소드는 필요한 요소만 Collection으로 담을 수 있고, 요소들을 그룹핑한 후 집계할 수 있다.
List<Student> sList = Arrays.asList(
new Student("Faker", 50, "a"),
new Student("Teddy", 30, "b"),
new Student("Effort", 10, "c"));
Map<String, Student> map = new HashMap<String,Student>();
map = sList.stream()
.collect(Collectors.toMap(Student::getName, Function.identity(),
(o1, o2) -> o1, HashMap::new));병렬 스트림 처리
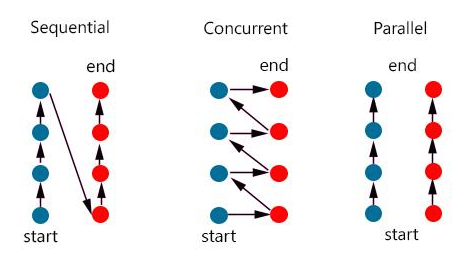
-
동시성 (concurrent) : 멀티 스레드가 번갈아가며 실행하는 성질
- 싱글 코어 CPU를 이용한 멀티 작업은 병렬적으로 실행되는 것처럼 보이지만, 번갈아가며 실행하는 동시성 작업 -
병렬성 (parallel) : 멀티 코어를 이용해 동시에 실행하는 성질
- 데이터 병렬성 : 전체 데이터를 쪼개어 서브 데이터들로 만들고 이 데이터들을 병렬 처리해 작업을 빨리 끝내는 것(parallelStream)
- 작업 병렬성 : 서로 다른 작업을 병렬 처리하는 것(Web Server : 각각 브라우저에서 요청한 내용을 개별 스레드에서 병렬로 처리) -
사용 예
public class PracticeExample{
public static void main(String[] args){
List<String> list = Arrays.asList("Faker", "Teddy", "Effort", "Wolf", "Bang", "Clid");
Stream<String> stream = list.parallelStream(); // parallesStream : 병렬처리
stream.forEach(PracticeExample :: print);
}
public static void print(String str) {
System.out.println(str + Thread.currentThread().getName());
}
}
-- 결과 --
Wolfmain
FakerForkJoinPool.commonPool-worker-3
TeddyForkJoinPool.commonPool-worker-1
ClidForkJoinPool.commonPool-worker-2
BangForkJoinPool.commonPool-worker-3
Effortmain- 내부 병렬 스트림 구조
- ForkJoin Framework 사용
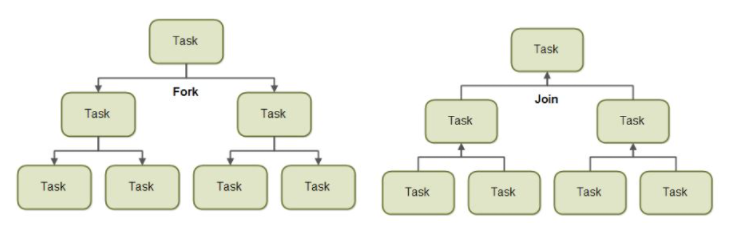
ForkJoin 프레임워크는 ExecutorService의 구현 객체인 ForkJoinPool을 사용해서 작업 스레드를 관리
- Fork 단계 : 전체 데이터를 서브 데이터로 분리
- 서브 데이터를 멀티 코어로 병렬 처리
- Join 단계 : 서브 데이터 결과를 결합해 최종 결과
- 단!!!
스트림 병렬 처리가 스트림 순차 처리보다 항상 실행 성능이 좋다고 판단해서는 안된다.
- 요소의 수와 요소당 처리 시간 : 병렬 처리는 스레드풀 생성, 스레드 생성이라는 추가비용이 발생하기 때문에 Collection에 요소수가 적고 요소당 처리 시간이 짧으면 순차 처리가 오히려 병렬 처리보다 빠를 수 있다.
- 스트림 소스의 종류 : 배열(ArrayList)은 인덱스로 요소를 관리하기 때문에 Fork 단계에서 요소를 쉽게 분리할 수 있어 병렬 처리 시간이 절약된다. 반면에 HashSet, TreeSet, LinkedList는 요소 분리가 쉽지 않아 상대적으로 병렬 처리가 늦다.
- 코어(Core) 수 : 싱글 코어 CPU일 경우에는 순차 처리가 더 빠르다. 병렬 스트림을 사용할 경우 스레드 수만 증가하고 동시성 작업으로 처리되기 때문에 좋지 못한 결과를 준다. 코어의 수가 많을수록 병렬 작업 처리속도는 빨라진다.
장점
- 코드가 간결해 진다.
- 병렬처리가 Collection내부에서 처리 가능하다.
- 쇼트 서킷 : 스트림은 특정 연사자를 사용할때, 여러 개의 조건이 중첩된 상황에서 값이 결정나면 불필요한 연산을 진행하지 않고, 조건문을 빠져나와 실행 속도를 높인다.

Fullstack developer