Kubeflow Pipelines
- Pipelines
- ML Worflow를 구축하고 배포하기 위한 플랫폼
- 엔드 두 엔드 오케스트레이션으로 기계 학습 파이프라인의 오케스트레이션
- 간편한 재사용으로 파이프라인을 재사용하여 독립 실행할 수 있음
전제 : pipeline 개발
- pipline을 정의한 code가 개발되어 있다고 할때(jupyter notebook에서 개발)
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
output='gs://your-gcs-bucket',
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
train_data='gs://ml-pipeline-playground/sfpd/train.csv',
eval_data='gs://ml-pipeline-playground/sfpd/eval.csv',
schema='gs://ml-pipeline-playground/sfpd/schema.json',
target='resolution',
rounds=200,
workers=2,
true_label='ACTION',
):
output_template = str(output) + '/' + dsl.RUN_ID_PLACEHOLDER + '/data'
# Current GCP pyspark/spark op do not provide outputs as return values, instead,
# we need to use strings to pass the uri around.
analyze_output = output_template
transform_output_train = os.path.join(output_template, 'train', 'part-*')
transform_output_eval = os.path.join(output_template, 'eval', 'part-*')
train_output = os.path.join(output_template, 'train_output')
predict_output = os.path.join(output_template, 'predict_output')
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
_analyze_op = dataproc_analyze_op(
project=project,
region=region,
cluster_name=cluster_name,
schema=schema,
train_data=train_data,
output=output_template
).after(_create_cluster_op).set_display_name('Analyzer')
_transform_op = dataproc_transform_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=train_data,
eval_data=eval_data,
target=target,
analysis=analyze_output,
output=output_template
).after(_analyze_op).set_display_name('Transformer')
_train_op = dataproc_train_op(
project=project,
region=region,
cluster_name=cluster_name,
train_data=transform_output_train,
eval_data=transform_output_eval,
target=target,
analysis=analyze_output,
workers=workers,
rounds=rounds,
output=train_output
).after(_transform_op).set_display_name('Trainer')
_predict_op = dataproc_predict_op(
project=project,
region=region,
cluster_name=cluster_name,
data=transform_output_eval,
model=train_output,
target=target,
analysis=analyze_output,
output=predict_output
).after(_train_op).set_display_name('Predictor')
_cm_op = confusion_matrix_op(
predictions=os.path.join(predict_output, 'part-*.csv'),
output_dir=output_template
).after(_predict_op)
_roc_op = roc_op(
predictions_dir=os.path.join(predict_output, 'part-*.csv'),
true_class=true_label,
true_score_column=true_label,
output_dir=output_template
).after(_predict_op)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))Flow 및 메뉴
- Piplines
- 이 pipline Code를 pipline으로 등록하는 단계
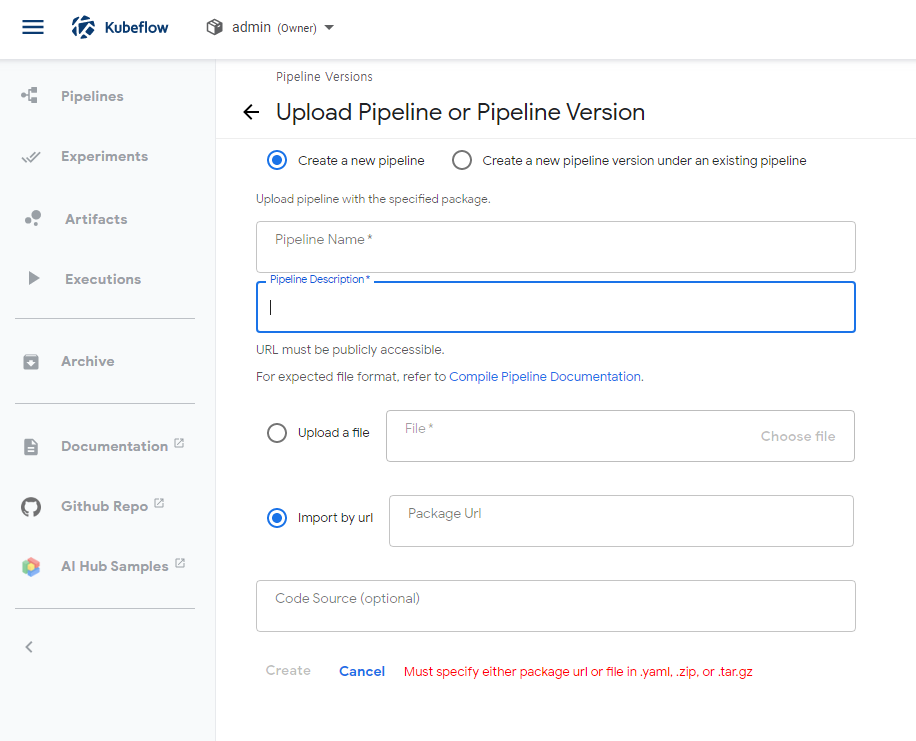
- Experiments and run (최신버전에는 메뉴가 나눠져 있음)
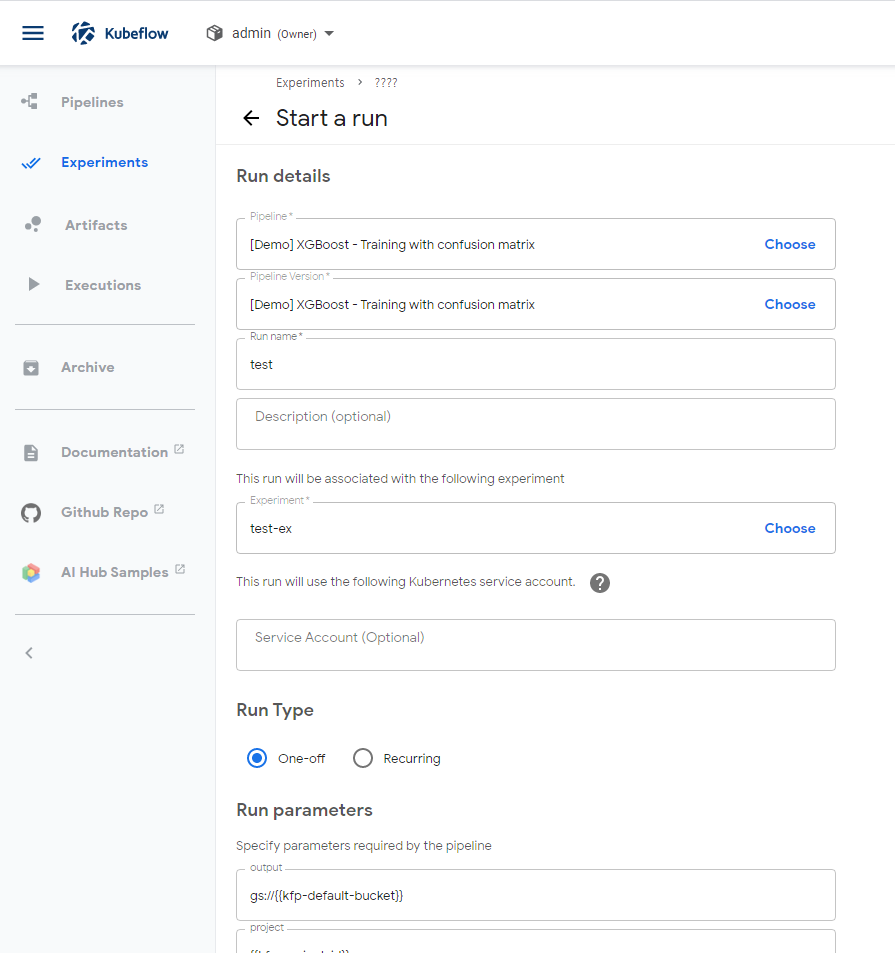
- Experiments
- 등록된 pipline으로 experiment 프로젝트를 생성하는 단계
- Run
- 만들어진 experiment을 사용하여 pipeline을 실행하는 단계
- 예약으로 experiment를 실행시킬 수 있음
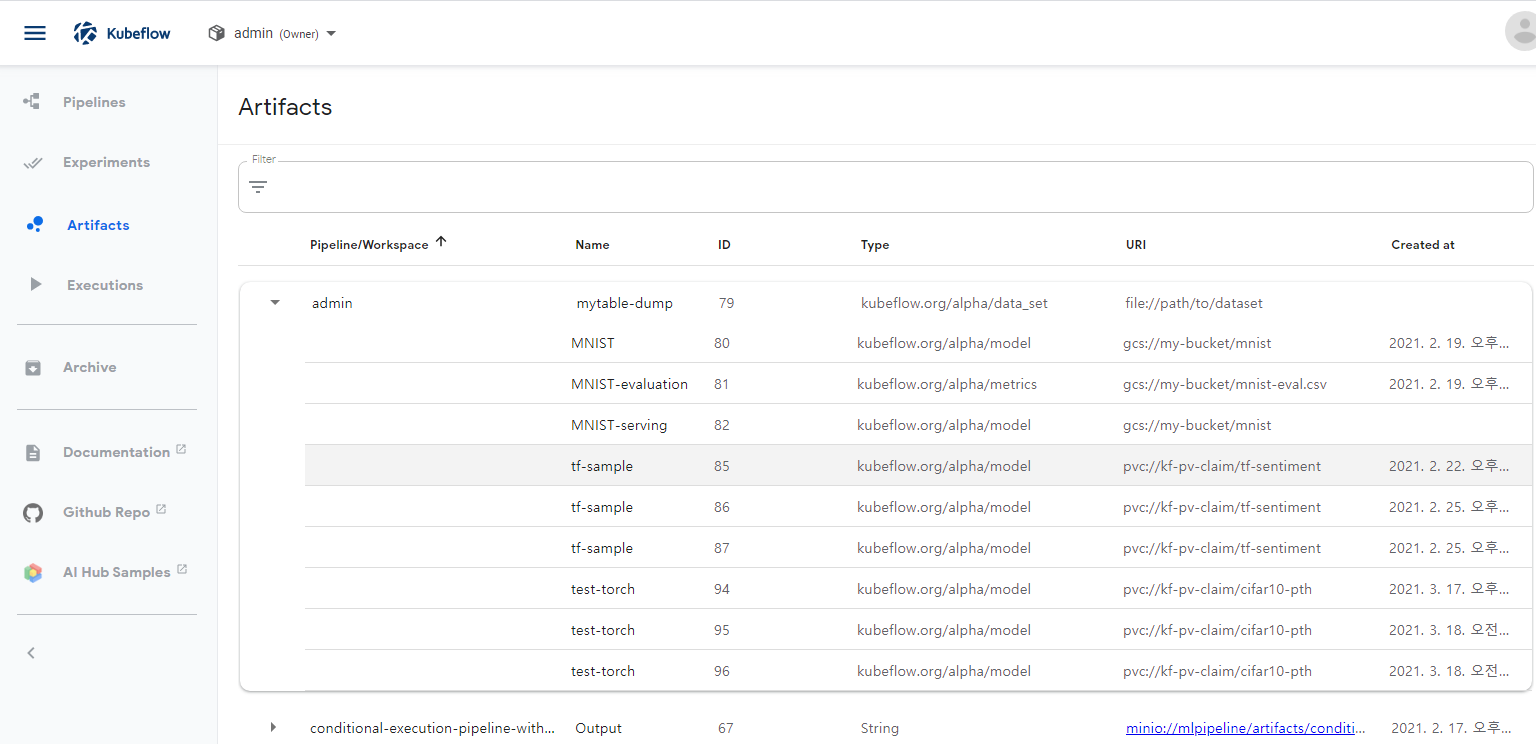
- Artifacts
- Experiment 실행시 pipeline 각 작업에서 생성되는 Metadta(input, output, 변수 등)들이 기록 되는데, 이 기록된 metadta의 정보 리스트
- 각 부분 (data_set, Execution, model, serving execution)에 대한 metadta 정보
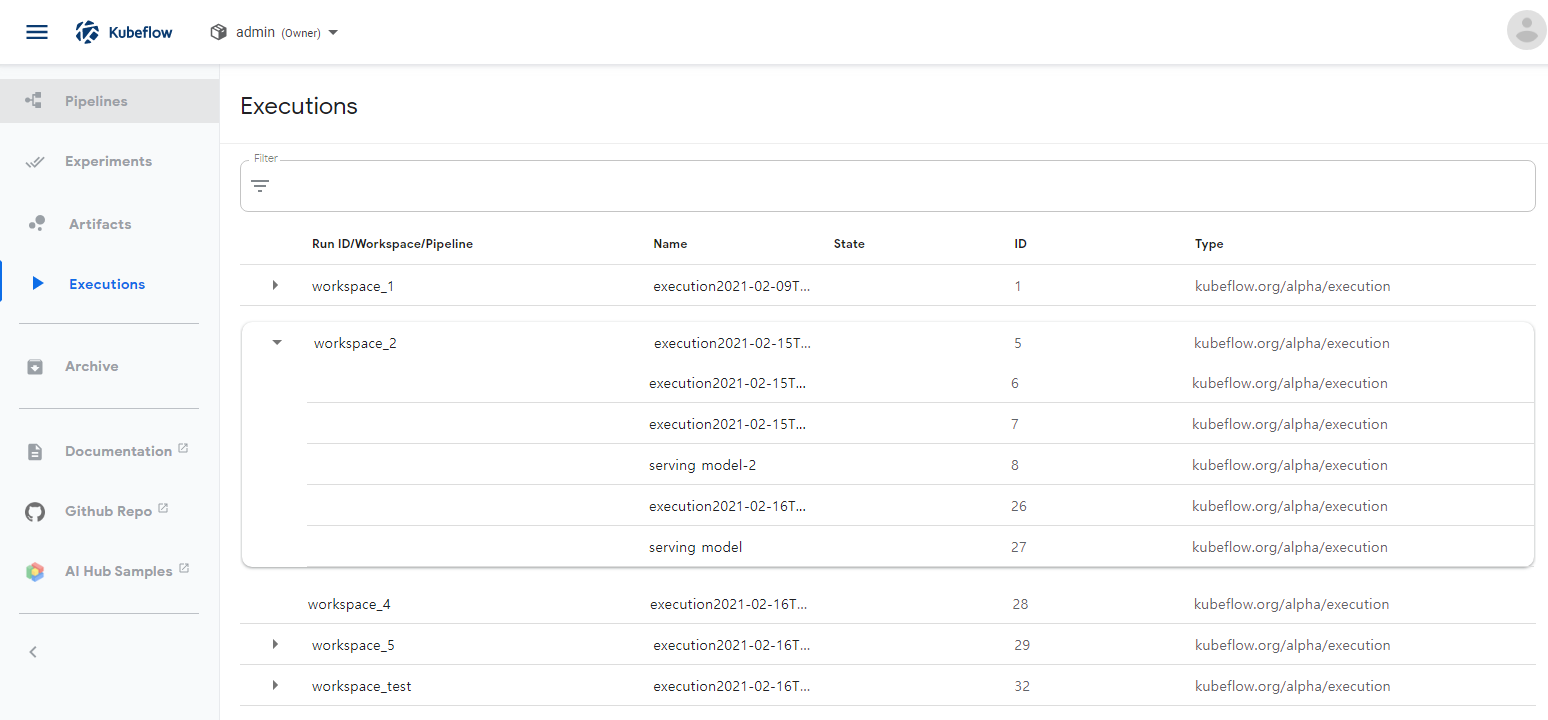
- Executions
- Experiment 실행시 pipline 각 작업 중에서 Execution 작업에서 기록된 Metadata 리스트
- Excution 종류(Trannig, Serving ...)
참고
- Kubeflow의 Home에 있는 메뉴를 간단히 보면
- Piplines
- 위에서 설명
- Nodebook Servers
- Python, R등의 언어로 개발
- Data Engineering 개발 및 테스트
- Model Tranning 개발 및 테스트
- pipline Code 개발 및 테스트
- ...
- Katib (추후 포스팅 예정)
- Hyper parameter 튜닝 및 신경망 아키텍처 탐색
- Artifact Store
- metadata (이전 포스팅에 있음)

Fullstack developer