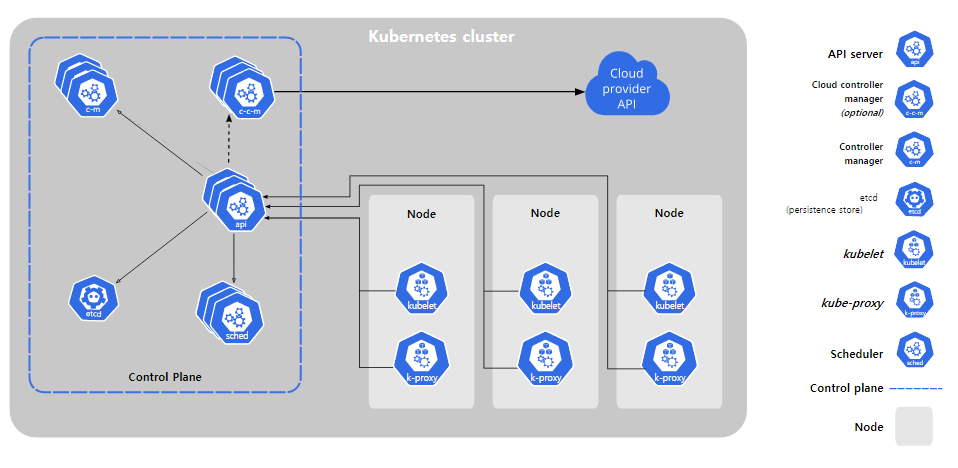

1. 쿠버네티스를 배포 -> 쿠버네티스 클러스가 구성된다.
2. 쿠버네티스 클러스터는 노드(머신)으로 구성되어 있고, 마스터 머신과 워커 머신으로 구성되어 있다.
3. 마스터 노드는 쿠버네티스 기본 컴포넌트(컨트롤 플레인 컴포넌트)들로 구성이된다. - (관리)
4. 워커 노드는 어플리케이션 구성 요소인 pod를 호스트한다. - (서비스)
5. 일반적으로 컨트롤 플레인은 여러 컴퓨터에 걸처 실행되고, 클러스터는 여러 노드를 실행한다.
control plane
-
클러스터내의 스케쥴링, 이벤트등을 감지하고 처리함.
-
kube-apiserver, etcd, kube-scheduler, kube-controller-manager
-
여러 VM에서 실행되는 컨트롤 플레인 설정 : https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
kube-apiserver
- API 서버는 쿠버네티스 API를 노출하는 쿠버네티스 컨트롤 플레인 컴포넌트
- API 서버는 쿠버네티스 컨트롤 플레인의 프론트 엔드
- 최종 사용자 - 클러스터의 다른 부분 - 외부 컴포넌트가 서로 통신할 수 있도록 HTTP API를 제공
- API 서버를 통해 쿠버네티스 오브젝트(pod, namespace, configmap, event, query)를 조작
- kubectl, kubeadm과 같은 컴낸드 라인도구를 사용하여 수행
- REST 호출을 사용하여 API 서버에 직접 접근할 수도 있다.
etcd
- 모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소
- 이 데이터를 백업하는 계획은 필수이다!!
kube-scheduler
- 노드가 배정되지 않은 새로 생성된 파드 를 감지하고, 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트
- 스케쥴링시 고려되는 요소
- 리소스에 대한 개별 또는 전체 요구 사항, 하드웨어/소프트웨어/정책적 제약, 어피니티(affinity) 및 안티-어피니티(anti-affinity) 명세, 데이터 지역성, 워크로드-간 간섭, 데드라인
kube-controller-manager
- 컨트롤러를 구동하는 마스터 상의 컴포넌트
- 논리적으로 각 컨트롤러는 개별 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 여러 컨틀롤 루프를 단일 프로세스 내에서 실행됨
- node 컨트롤러 : 노드가 다운되면 통지, 대응
- replication 컨트롤러 : 시스템의 모든 replication 컨트롤러 오브젝트에 맞게 파드 유지
- endpoint 컨트롤러 : endpoint 오브젝트를 구성(서비스, 파드 연결)
- service account & token 컨트롤러 : 새로운 namespace에 대한 default service accout와 api 접근을 위한 default token을 생성
cloud-controller-manager
- 클라우드별 컨트롤 로직을 포함하는 쿠버네티스 컨트롤 플레인 컴포넌트
- 라우드 컨트롤러 매니저를 통해 클러스터를 클라우드 공급자의 API에 연결하고, 해당 클라우드 플랫폼과 상호 작용하는 컴포넌트와 클러스터와만 상호 작용하는 컴포넌트를 구분할 수 있게 해 준다
- cloud-controller-manager는 클라우드 제공자 전용 컨트롤러만 실행
- 자신의 사내 또는 PC 내부의 학습 환경에서 쿠버네티스를 실행 중인 경우 클러스터에는 클라우드 컨트롤러 매니저가 없음
- 논리적으로 각 컨트롤러는 개별 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 여러 컨틀롤 루프를 단일 프로세스 내에서 실행됨 (kube-controller-manager와 같음)
- node 컨트롤러 : 노드가 응답을 멈춘 후 클라우드 상에서 삭제되었는지 판별하기 위해 클라우드 제공 사업자에게 확인
- route 컨트롤러 : 기본 클라우드 인프라에 경로를 구성
- service 컨트롤러 : 클라우드 제공 사업자 로드밸런서를 생성, 업데이트 삭제
Node Component
- 동작중인 파드를 유지, kubernetes 런타임 환경을 제공, 모든 node에서 동작
kubelet
- 클러스터의 각 node에서 샐힝되는 agent
- kubelet은 pod에서 컨테이너가 동작하도록 관리하는 것으로, pod spec대로 동작하는지 확인한다.
kube-proxy
- 클러스터의 각 노드에서 실행되는 네트워크 프록시로 실행됨
- 쿠버네티스의 서비스 개념의 구현부
- 각 노드의 쿠버네티스 API에 정의된 서비스를 반영
- TCP, UDP, SCTP Stream forward, round-robin TCP, UDP, SCTP forwarding을 백엔드 셋에서 수행 할 수 있음
- 서비스 클러스터 ip, port는 현재 서비스 프록시에 의해 열린 포트를 지정하는 docker-links-compatible 환경변수에서 찾을수 있음
- 노드의 네트워크 규칙을 유지 관리하는데,
- 네트워크 규칙은 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해줌
- 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용한다. 그렇지 않으면, kube-proxy는 트래픽 자체를 포워드(forward)
container runtime
- 컨테이너 실행을 담당하는 소프트웨어
- Docker, containerd, CRI-O, CRI(컨테이너 런타임 인터페이스)를 구현한 모든 소프트웨어 (https://github.com/kubernetes/community/blob/master/contributors/devel/sig-node/container-runtime-interface.md)
Add-on
-
쿠버네티스 리소스(daemonset, deployment...)를 이용하여 클러스터 기능을 구현
-
kube-system namespace에 속함
DNS
-
클러스터 DNS를 구성해야함
-
쿠버네티스는 pod, service를 위한 DNS 레코드를 생성함
- ip 주소 대신 일관된 DNS 네임을 통해 서비스에 접속 할 수 있음
-
개별 컨테이너 들이 DNS 네임을 해석할때, DNS 서비스의 IP를 사용하도록 kubelets을 구성
-
DNS 레코드가 되는 리소스
- Service, Pod
-
서비스의 네임스페이스
- DNS를 사용하여, API를 요청을 했을때, 같은 네임스페이스안에서는 파드명으로 요청가능하지만, 다른 네임스페이스에 있을경우 네임스페이스 + 파드로 요청해야한다.
- 예) DNS 구성 : {pod}.{namespace} 또는 {pod}.{namespace}.cluster.local로 사용할 수 있음
- DNS 정보는 각 pod의 /etc/resolv.conf에 있음
nameserver 10.32.0.10
search .svc.cluster.local svc.cluster.local cluster.local
options ndots:5
- DNS를 사용하여, API를 요청을 했을때, 같은 네임스페이스안에서는 파드명으로 요청가능하지만, 다른 네임스페이스에 있을경우 네임스페이스 + 파드로 요청해야한다.
-
쿠버네티스 DNS-기반 서비스 디스커버리https://github.com/kubernetes/dns/blob/master/docs/specification.md
-
Service
- A/AAAA 레코드
- normal
- 클러스터 IP
- 형식 : my-svc.my-namespace.svc.cluster-domain.example
- headless :
- 서비스에 선택된 파드 IP 집합
- 클러스터 IP 없음
- 요청시 pod는 IP 직접 선택, 라운드로빈으로 선택된다
- 형식 : my-svc.my-namespace.svc.cluster-domain.example
- normal
- SRV 레코드
- normal, headless service에 속하는 이름있는 port를 위해 만들어짐
- 형식 :
- normal : _my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster-domain.example
- headless : auto-generated-name.my-svc.my-namespace.svc.cluster-domain.example
- A/AAAA 레코드
-
Pod
-
A/AAAA 레코드
- 형식 : pod-ip-address.my-namespace.pod.cluster-domain.example
- 예) default namespace + 172.17.0.3 ip
- 172-17-0-3.default.pod.cluster.local
- 예) default namespace + 172.17.0.3 ip
- deployment, daemonset으로 생성된 pod의 DNS
- 예) pod-ip-address.deployment-name.my-namespace.svc.cluster-domain.example
- 형식 : pod-ip-address.my-namespace.pod.cluster-domain.example
-
pod spec에 hostname, subdomain 설정
- 전체 도메인 네임(FQDN)을 구성할 수 있음
- hostname : pod의 이름보다 hostname(foo)이 우선됨
- subdomain : hostname(foo) + subdomain(bar)을 구성할 수 있음
- 예) foo.bar.my-namespace.svc.cluster-domain.example
-
headless service + pod 구성
-
headless service
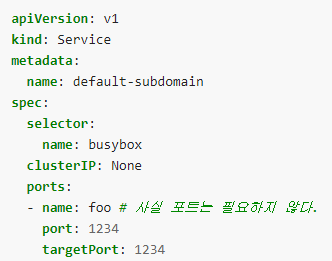
-
pod
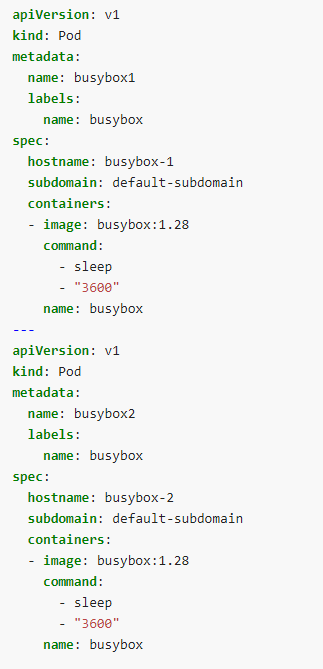
-
pod DNS
- busybox-1.default-subdomain.my-namespace.svc.cluster-domain.example
- busybox-2.default-subdomain.my-namespace.svc.cluster-domain.example
-
-
pod의 setHostnameAsFQDN 필드
- FQDN: busybox-1.default-subdomain.my-namespace.svc.cluster-domain.example라면...
- pod에서 hostname 명령은 busybox-1을 반환
- pod에서 hostname --fqdn 명령은 위의 FQDN을 반환
- pod spec에 setHostnameAsFQDN: true를 설정 시
-hostname, hostname --fqdn 둘다 FQDN을 반환 - 참고 : 리눅스에서, 커널의 호스트네임 필드(struct utsname 의 nodename 필드)는 64자로 제한
- pod에서 이 기능을 사용하도록 설정하고 FQDN이 64자보다 길면, 시작되지 않음.
- FQDN: busybox-1.default-subdomain.my-namespace.svc.cluster-domain.example라면...
-
pod의 DNS 정책
- DNS 정책은 파드별로 설정가능
- pod spec dnsPolicy에 지정 할 수 있음
- default : 노드 resolve 상속
- ClusterFirst : 노드의 resolve에 없는 것은 별도 네임서버로 전달, stub-domain, upstream DNS 서버를 구축할 수 있음 (DNS 기본 정책으로 사용)
- ClusterFistWithHostNet : hostNetwork: true인 pod의 경우 명시적으로 설정해야함.
- None : 파드가 쿠버네티스 환경 DNS설정을 무시하도록하고, pod내 dnsConfig 필드를 사용하게 함.
-
pod의 DNS 설정
- dnsConfig
- nameservers : DNS 서버가 사용할 IP주소 목록
- searches : DNS 검색 도메인의 목록(최대 6개)
- options : DNS 정책 옵션

- dnsConfig
nameserver 1.2.3.4
search ns1.svc.cluster-domain.example my.dns.search.suffix
options ndots:2 edns0 -
-
-
웹 UI (대시보드)
- 쿠버네티스 클러스터를 위한 법용 웹기반 UI
- https://kubernetes.io/ko/docs/tasks/access-application-cluster/web-ui-dashboard/
컨테이너 리소스 모니터링
- 중앙 데이터베이스 내의 컨테이너들에 대한 시계열 메트릭스를 기록 및 UI
- https://kubernetes.io/ko/docs/tasks/debug-application-cluster/resource-usage-monitoring/
- 리소스 메트릭 파이프라인
- kubectl top
- horizontal pod autoscaler
- metrics-server에 의해 수집되며 metrics.k8s.io API로 사용
- Metrics-server
- 클러스터 상의 모든 노드를 발견하고 각 노드의 Kubelet에 CPU와 메모리 사용량을 질의
- Kubelet은 쿠버네티스 마스터와 노드 간의 다리 역할을 해서 머신에서 구동되는 파드와 컨테이너를 관리
- Kubelet은 컨테이너 런타임 인터페이스를 통해서 컨테이너 런타임에서 개별 컨테이너의 사용량 통계를 가져옴
- Kubelet은 이 정보를 레거시 도커와의 통합을 위해 kubelet에 통합된 cAdvisor를 통해 가져옴
- 취합된 파드 리소스 사용량 통계를 metric-server 리소스 메트릭 API를 통해 노출
- API는 kubelet의 인증이 필요한 읽기 전용 포트 상의 /metrics/resource/v1beta1에서 제공
- 완전한 메트릭 파이프라인
- 좀 더 풍부한 메트릭에 접근할 수 있도록 해줌
- Horizontal Pod Autoscaler와 같은 메커니즘을 활용해서 이런 메트릭에 대한 반응으로 클러스터의 현재 상태를 기반으로 자동으로 스케일링하거나 클러스터를 조정할 수 있다
- kubelet에서 메트릭을 가져와서 쿠버네티스에 custom.metrics.k8s.io와 external.metrics.k8s.io API를 구현한 어댑터를 통해 노출
클러스터-레벨 로깅
-
-
검색/열람 인터페이스와 함께 중앙 로그 저장소에 컨테이너 로그를 저장
-
https://kubernetes.io/ko/docs/concepts/cluster-administration/logging/
- 다른 페이지에 작성kubelet
kubeadmkube-proxy
scheduler
corednstiller
flannelmaster
workercloud controller manager (optional)
ingress controller (nginx)
추가
iptable (프록시 모드)
cni
ipvs
fin 패킷
qps
snat
cidr
