작성자: 우아한테크코스 5기 여우
우테코에는 '데모데이' 라는 문화가 있어요!
매 2주간의 스프린트를 마치는 금요일에, 팀마다 프로젝트 상황을 발표하고 상호 피드백을 주고받는 행사에요.
발표 세션이 끝나고, 프로젝트의 클라이언트 파트와 백엔드 파트가 서로 잘 연결되는지 시연해보라는 요구가 갑작스럽게 들어왔어요.
우리 이돈이면 팀에서도 부랴부랴 연결 검토를 하고 있었는데,
백엔드의 멋쟁이 팀원 케로가 갑자기 제게 외쳤어요.
"전체 게시글 조회하니까 SELECT 쿼리가 스무 번 넘게 나가는데?"
'zzㅋㅋ뭐라고? 버튼 스무 번 누른 것 아니야?' 라고 현실부정을 하던 저는
서버 로그를 보여주는 작은 터미널 창이
제가 구현한 SELECT 쿼리문으로 가득 찬 걸 보고서야 무언가 잘못 구현돼있음을 깨달았어요.
팀에게 정말 감사하게도 데모데이는 성공적으로 마무리되었지만,
SELECT * FROM POST 딱 한 줄이면 끝날 조회 쿼리가
한 번의 호출에 수십 개씩 나간다는 것은 당장 해결해야 할 1순위 이슈가 되었고.
이것이 그 말로만 듣던 N+1 Query Problem임을 알게 되었습니다.
이돈이면 팀에서는 이 N+1을 어떻게 해결했을까요! 그 과정을 적어보겠습니다 😺
원인 파악
우예 이런 참혹한 일이 일어났능교
우선 우리 프로젝트는 쿼리 매핑 방법으로 JPA를 채택했으므로,
프로젝트에서 어떤 엔티티를 사용하는지 설명할 필요가 있습니다.
'게시글' 객체를 나타내는 Post 클래스의 구조는 이렇게 생겼어요!
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String title;
@Column(nullable = false, columnDefinition = "longtext")
private String content;
@Column(nullable = false)
private Long price;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(nullable = false)
private Member member;
@OneToMany(mappedBy = "post")
private List<PostImageInfo> postImageInfos;
@CreatedDate
@Column(nullable = false)
private LocalDateTime createdAt;
@ColumnDefault("0")
private Long viewCount = 0L;
...여기서 주의깊게 볼 점은 Post와 연관관계를 맺고 있는 postImageInfos로,
게시글에 함께 등록된 이미지들의 정보를 담는 엔티티에요.
게시글을 하나 작성할 때 이미지를 여러 개 첨부해서 작성하면
게시글 자체는 Post에, 첨부한 이미지는 PostImageInfos에 매핑되어 각각의 Repository에 저장되는 구조에요.
따라서 Post와 PostImageInfo는 1:N 관계에요!
해당 비정상 쿼리는
모든 게시글(Post)를 조회하는 API를 호출할 때 발생했어요.
이 API를 호출할 때 Intellij의 디버깅을 활용하면서
정확히 어디에서 어떤 쿼리가 나가는 지 확인해야겠어요!
먼저 문제의 API인 '/posts GET 요청'을 보내면
postService의 findAllPost() 메소드를 실행해요!
public List<GeneralPostInfoResponse> findAllPost(final GeneralFindingCondition generalFindingCondition) {
1. Spring Data JPA가 사용할 수 있는 페이징 객체인 PageRequest 객체 만들기
final PageRequest pageRequest = convertConditionToPageRequest(generalFindingCondition);
2. 페이징 조건에 맞게 모든 Post 엔티티 찾기
final Slice<Post> foundPosts = postRepository.findAll(pageRequest);
3. Post 엔티티들을 DTO 객체인 GeneralPostInfoResponse로 바꾸어 응답하기
return foundPosts
.map(post -> GeneralPostInfoResponse.of(post, domain.getDomain()))
.toList();
}일단 postRepository.findAll() 메소드를 실행할 때
'SELECT ~~ FROM POST' 쿼리가 1번,
'SELECT ~~ FROM MEMBER' 쿼리가 1번 나가요!


그리고 바로 다음 줄, findAll()로 찾은 List를 DTO로 변환하는
GeneralPostInfoResponse.of() 메소드 내부에는
public static GeneralPostInfoResponse of(Post post, String domain) {
return new GeneralPostInfoResponse(
post.getId(),
post.getTitle(),
post.getPostImageInfos().size() == 0 ? null : domain + post.getPostImageInfos().get(0).getStoreName(),
// Post와 연관관계인 PostImageInfo에서 storeName을 가져와 DTO에 매핑하기
post.getContent(),
new WriterResponse(post.getMember().getNickname()),
post.getCreatedAt(),
new ReactionCountResponse(0, 0, 0)
// TODO: 조회수
// TODO: 스크랩 수
// TODO: 댓글 수
);
}요렇게 각 필드를 getter 메소드로 조회하는 작업이 있어요.
이 중 PostImageInfo 엔티티를 조회하는 getPostImageInfo() 메소드를 호출할 때
'SELECT ~ FROM POST_IMAGE_INFO WHERE POST_ID = ?' 쿼리가 나가고,
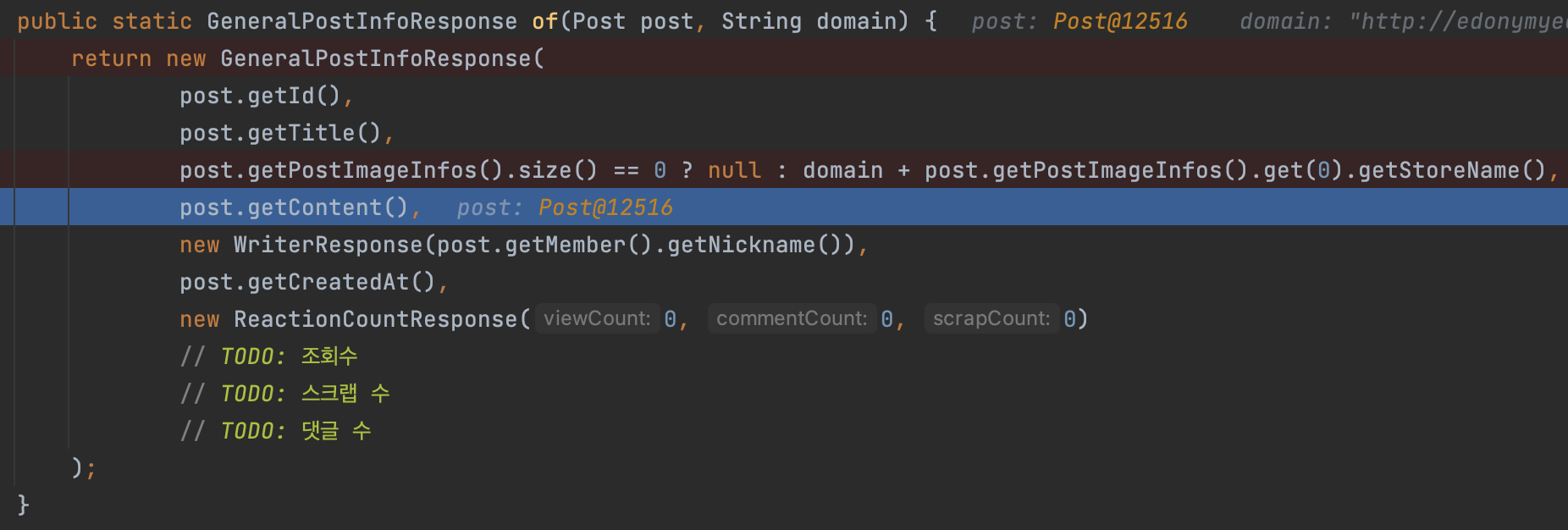

반복문을 돌 때마다 PostImageInfo를 찾는 쿼리가 실행되기 때문에
조회한 게시글 목록이 20개라면
'SELECT FROM POST' 쿼리 1번,
'SELECT FROM MEMBER' 쿼리 1번,
그리고 'SELECT FROM POST_IMAGE_INFO' 쿼리 20번이 나가면서
총 22번의 쿼리가 나가는 일이 벌어진 거에요 😮
해결 시도 1 - FetchType
하지만 저는 똑똑해요
사태를 파악하자 마자 해결책을 바로 떠올렸죠.
POST랑 POST_IMAGE_INFO를 조회하는 쿼리를 따로 날리지 말고
'inner join을 이용해 하나의 쿼리로 조회하게 만들면 되겠구나!'
하지만 이것을 JPA로 실현하는 방법을 몰라요.
먼저 떠오른 생각은
@OneToMany로 이어진 연관관계는 기본으로 지연로딩을 하도록 되어 있으니
이를 즉시로딩으로 바꾸면 되지 않을까라는 것이었어요!
곧바로 실험해 보았죠
@OneToMany(mappedBy = "post", fetch = FetchType.EAGER) <- 즉시로딩으로!
private List<PostImageInfo> postImageInfos;즉시로딩으로 바꾸었으니,
'postService.findAll()을 호출할 때 join을 이용해 한 번에 조회해 줄거야!
N+1 간단히 뿌쉈다 하하'

그러나 뿌서지는 건 나였다
즉시로딩을 하고 나니
원래는 map을 돌 때 순차적으로 나가던 22번의 쿼리가
postService.findAll() 호출 시 한꺼번에 쫘자작 나가더군요.
시기를 앞당겼을 뿐 N+1은 여전히 발생한다는 사실에 좌절했습니다.
해결 시도 2 - JQPL
에잇 이럴거면 join 쿼리를 내가 직접 쓰자
JPA에서는 데이터베이스 기준으로 작성하는 SQL문 대신
애플리케이션 객체를 기준으로 작성하는 JQPL이라는 문법을 지원해요.
저는 JPQL의 Fetch Join을 활용해 문제를 해결하고자 했습니다.
@Query("SELECT p FROM Post AS p LEFT JOIN FETCH p.postImageInfos")
Slice<Post> findAll(PageRequest pageRequest);JPQL의 Fetch Join을 사용하면
left inner join을 이용해 쿼리를 한 번에 실행함으로써
N+1 문제를 일으키지 않게 돼요!
그리고 이렇게 함께 조회한 연관관계 엔티티도 함께 1차 캐시에 영속화함으로써
엔티티 정보가 또 필요할 때 추가 SELECT문 없이 캐시에서 바로 꺼내 사용할 수 있죠.
아주 나이스하죵
과연 의도한 대로 되어줄 것인가.
제발 돼라
빰빠빰~~~
join을 사용하여 post와 postImageInfo의 정보를 한 쿼리로 한 번에 조회하는 것을 확인할 수 있었습니다
N+1 해결! ,, 이라는 생각이 들던 찰나,
SQL 로그 위에 적혀있던 스산한 기운의 로그 하나.

불길합니다. 대체 무슨 뜻일까 ,, 검색을 해보니
쿼리 결과를 전부 메모리에 적재한 뒤 Pagination 작업을 어플리케이션 레벨에서 하기 때문에 위험하다는 로그이다.
출처: fetch join 과 pagination 을 같이 쓸 때(우테코 선배림ㅋㅋ)

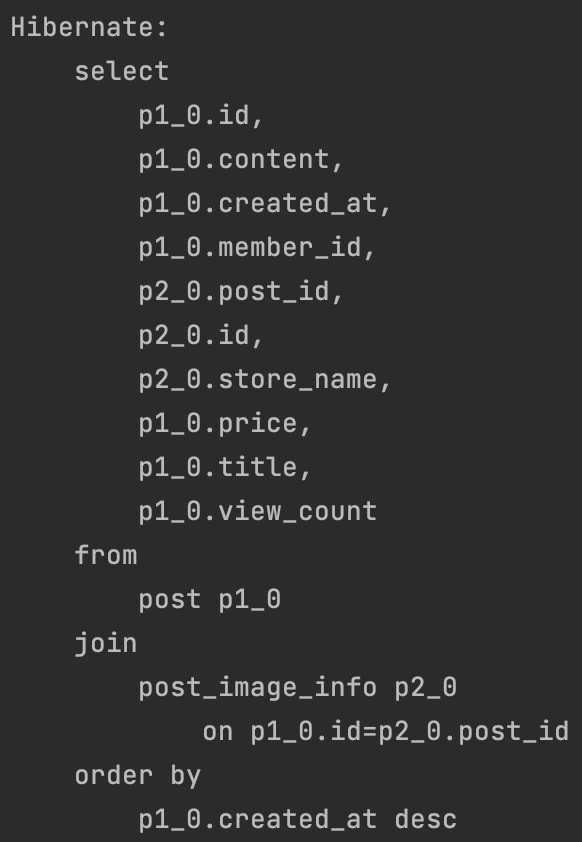
쎄한 기분에 SQL 쿼리를 다시 살펴보니
select
p1_0.id,
p1_0.content,
p1_0.created_at,
p1_0.member_id,
p2_0.post_id,
p2_0.id,
p2_0.store_name,
p1_0.price,
p1_0.title,
p1_0.view_count
from
post p1_0
join
post_image_info p2_0
on p1_0.id=p2_0.post_id
order by
p1_0.created_at desc
<- 페이징 어디감 ,,??조회할 게시글의 개수를 제한하는 limit 절이 안 보입니다.
분명 조회시 조회 개수와 페이지, 정렬 기준 등을 담은 PageRequest를 함께 넘겨주었는데,
@Query("SELECT p FROM Post AS p JOIN FETCH p.postImageInfos")
Slice<Post> findAll(PageRequest pageRequest);쿼리에는 페이징 정보 중 limit과 관련된 내용만 반영되지 않고
마치 'SELECT *'처럼 모든 데이터를 끌어와서는
애플리케이션 레벨에서 페이징을 수행하고 있다는 것을 알게 되었어요.
아니 JPA 멍충아 ..!!!
어떻게 이런 일이 일어나는가
PageRequest를 아예 인식하지 않는다면 모를까,
어떻게 limit만 쏙 빼서 모든 데이터를 가져와놓고는
자바 코드레벨에서 그걸 거르도록 설계해 둔걸까 몹시 궁금했습니다.
그래서 "HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory" 라는 로그를 출력하는 코드에 디버깅 포인트를 꽂은 후,
디버깅 화면에서 스택을 하나하나 내려가보며 코드 구조 분석을 시작했어요.
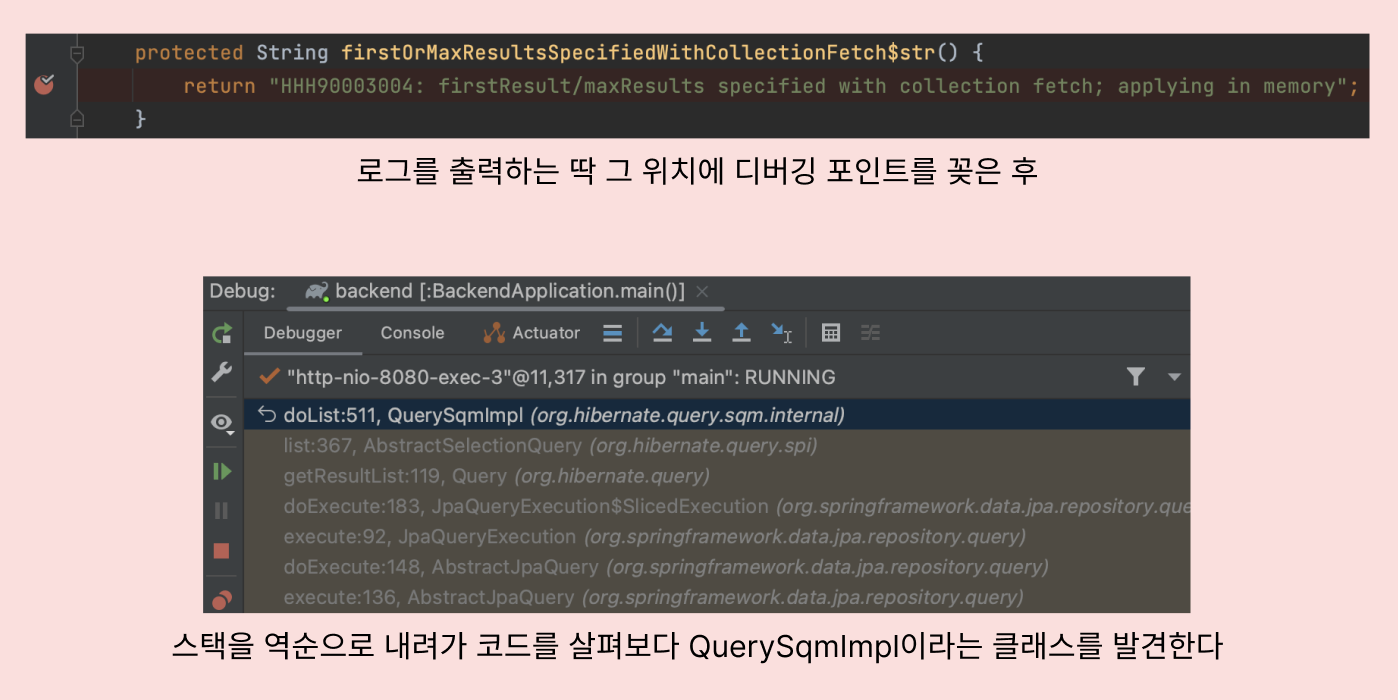
하나하나 보다보니 QuerySqlImpl 클래스의 List<R> doList()라는 메소드가 미심쩍더라구요!
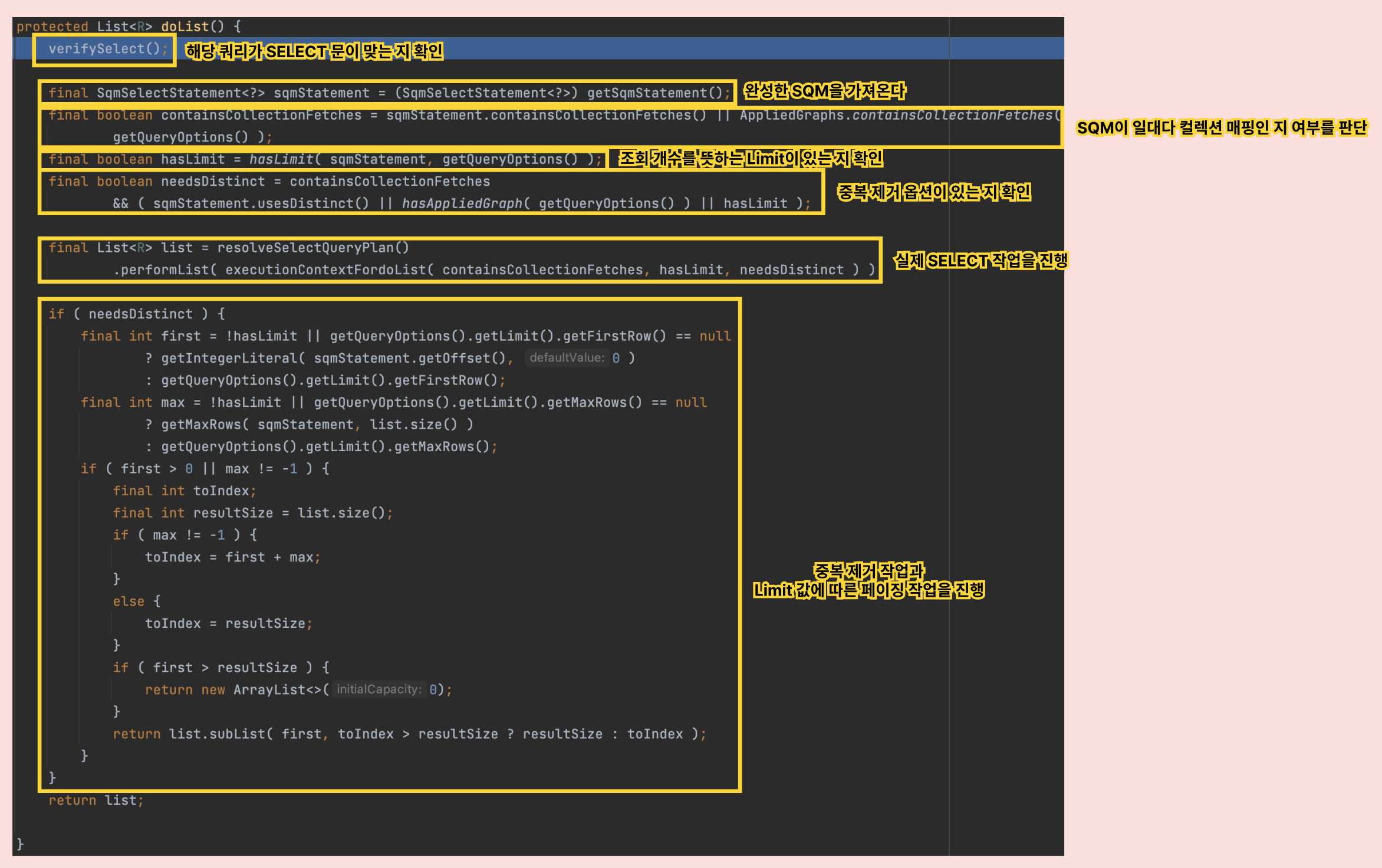
doList()의 실행 프로세스는 대략 이러했습니다. 메소드 분리가 참으로 안되어 있군요 ...
게시글이 총 10개 저장되어 있고,
한 페이지에 3개씩 보여주는 조건으로 전체 게시글을 조회한다고 할 때
위 doList() 메소드에서
실제 SELECT 작업을 진행하는 performList() 메소드를 실행하고 나면
list 변수에는 limit 없이 전체 조회한 게시글 10개가 들어있고,
마지막 list.subList() 작업에서 실제로 limit값에 맞추어 리스트를 잘라 응답하는 작업을 합니다.
만약 프로젝트에 등록된 게시글이 100만개라면
100만개의 게시글을 전부 조회해 메모리에 올린 다음
그 중 최신순 10개만 추려서 응답하겠죠?
대충격
왜 이러는가
이건 뭔가
fetch join과 페이징이 SQL 쿼리에서 동시에 일어나지 않게
JPA 개발자들이 일부러 막아둔 것처럼 보였어요.
대체 왜 그래야 했을까요?
이와 관련해 인프런에서 김영한 스승님꼐서 남기신 코멘트를 발견했어요
JPA에서 paging을 하게되면, OneToMany, ManyToMany 같은 컬렉션 관계는 fetch join이 불가능합니다. 왜냐하면 이렇게 일대다 테이블을 조인하면 데이터의 수가 변하기 때문입니다. 그래서 JPA에서는 paging을 하면서 컬렉션 관계를 fetch join 하는 것 자체를 동작하지 않도록 막아두었습니다.
출처 : 인프런
컬렉션 관계는 fetch join이 불가능하다.
일대다 테이블을 조인하면 데이터의 수가 변한다.
머선 말이고!
우선
게시글 하나에 여러 개의 이미지를 첨부할 수 있으므로
게시글과 게시글 이미지는 일대다(1:N) 관계에요.
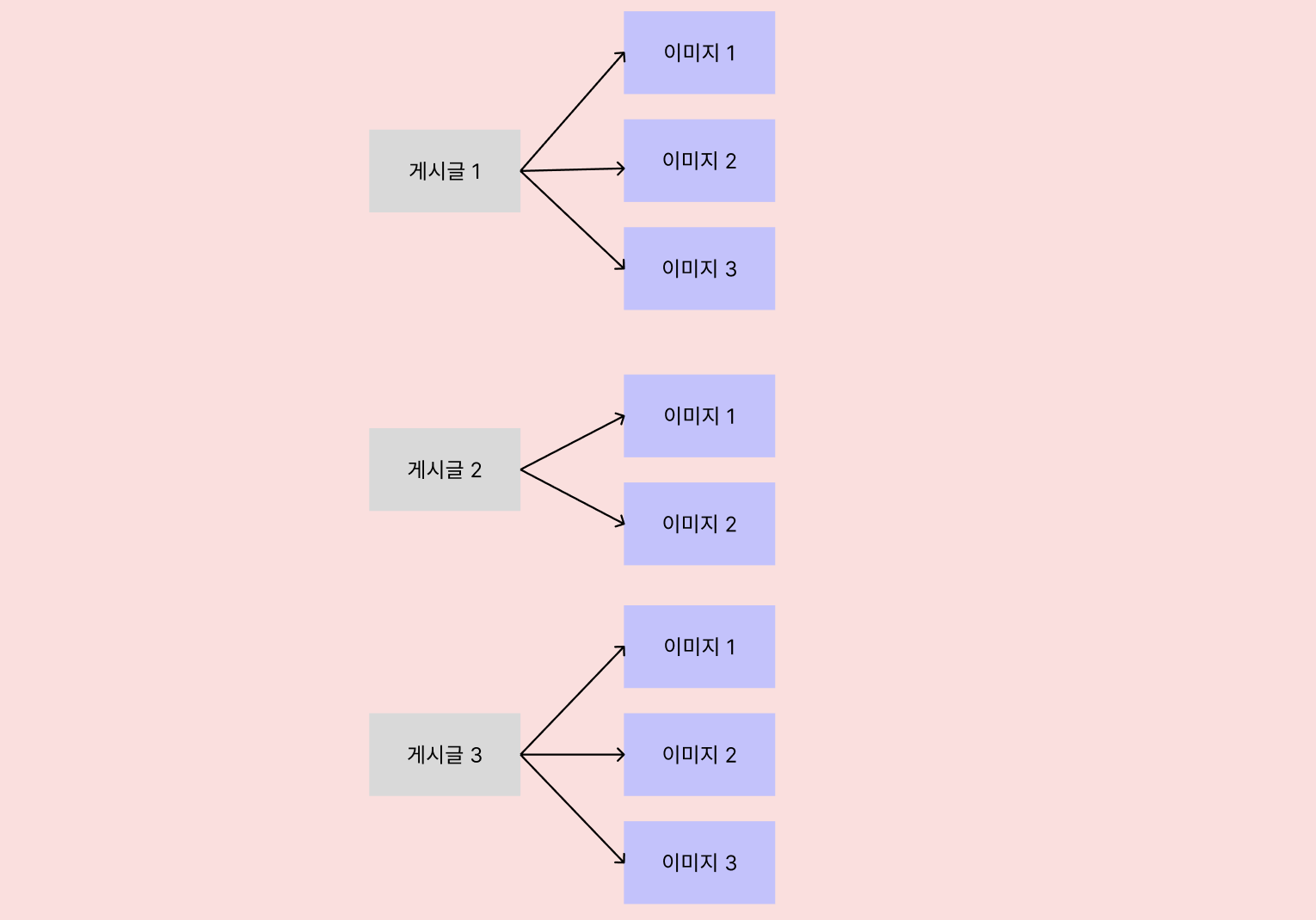
그리고 '해결 시도 2' 의 findAll()을 실행하면 left fetch join JPQL이
아래 SQL문으로 바뀌어 나가요.
select
p1_0.id,
p1_0.content,
p1_0.created_at,
p1_0.member_id,
p2_0.post_id,
p2_0.id,
p2_0.store_name,
p1_0.price,
p1_0.title,
p1_0.view_count
from
post p1_0
left join
post_image_info p2_0
on p1_0.id=p2_0.post_id
order by
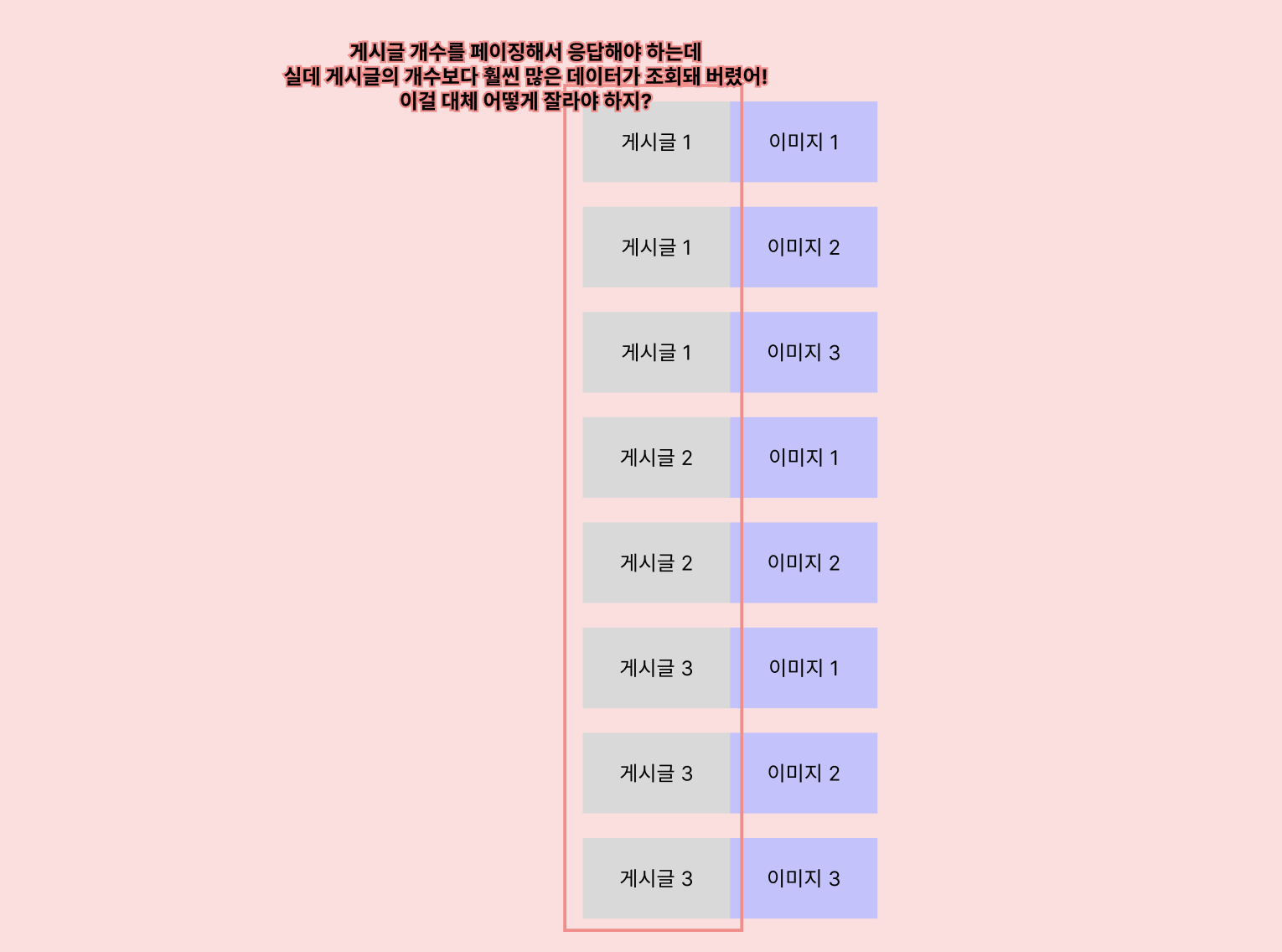
p1_0.created_at desc이 쿼리를 실행해서 가져온 데이터는 이런 형태에요!
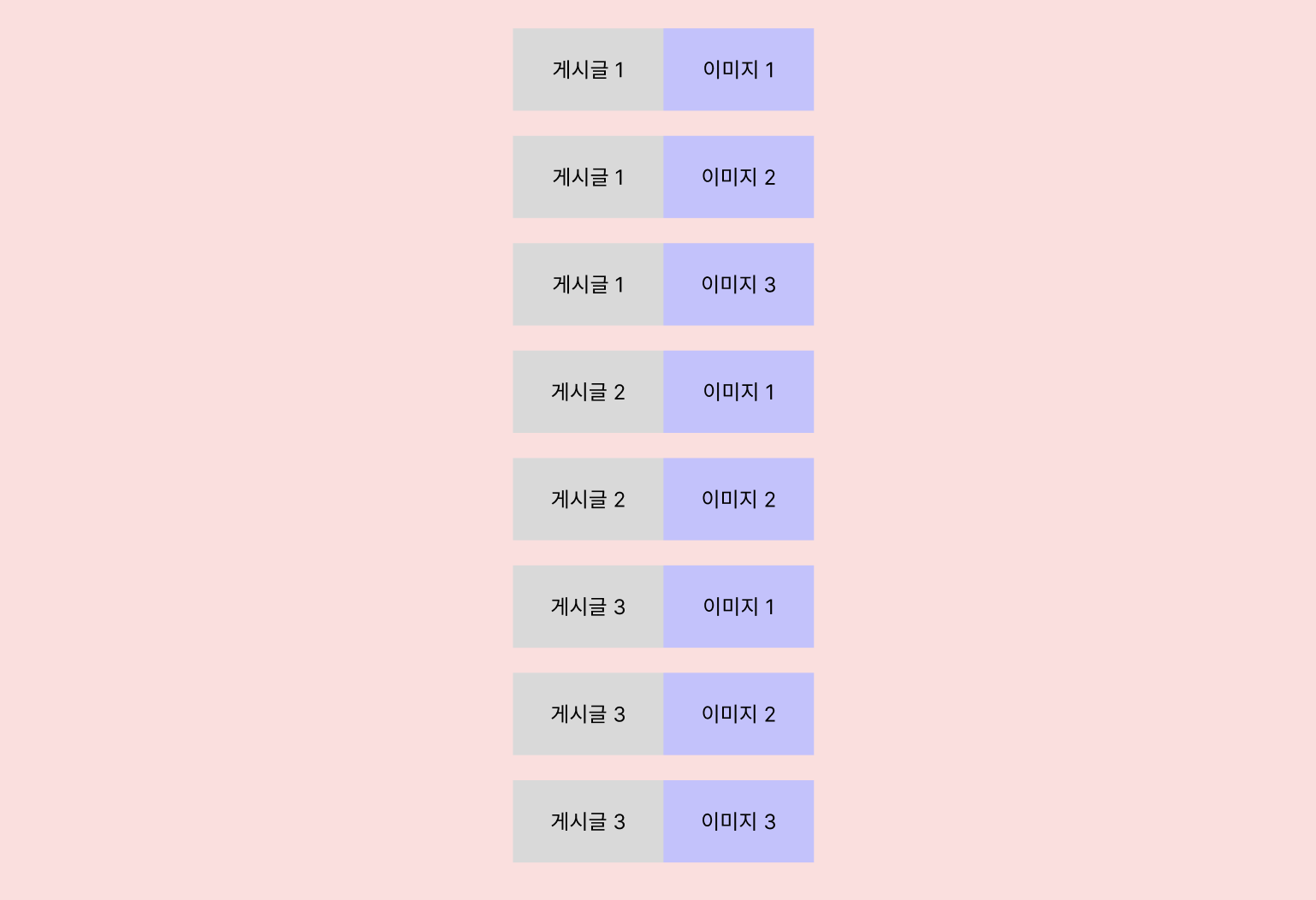
분명 게시글 개수는 3개고, 어쨌거나 'SELECT FROM POST' 문이니
3개의 결과 row가 나올 것 같았는데,
fetch join으로 연결한 게시글 이미지 데이터에 게시글 데이터가 1:1로 붙어
1:N 관계의 N개에 해당하는 9개의 결과 row가 나왔어요!
이것이 1:N 관계인 엔티티를 fetch join할 때, JPA 용어로는 CollectionFetch를 할 때 나타나는 문제이고,
이렇게 실제 POST의 개수보다 훨씬 많은 개수로 돌아온 데이터를
대체 어떻게 페이징해야 하는 지 그 기준을 JPA는 세우지 못해요.
그래서 JPA의 SELECT 코드를 보면
우선 해당 작업이 CollectionFetch를 포함하고 있는지를 확인하고,
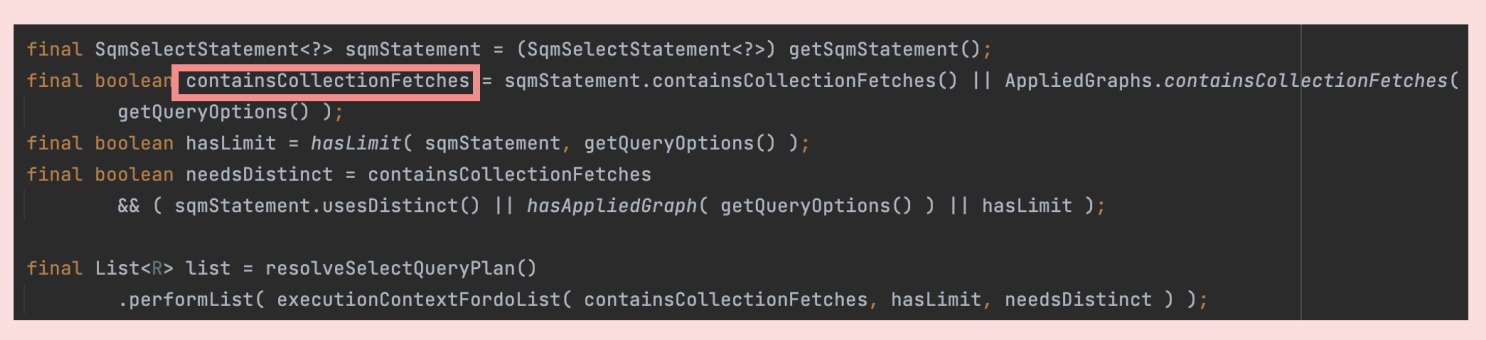
CollectionFetch를 포함하는 경우
페이징 limit이 포함된 요청이더라도 이를 무시하는 옵션으로 SQM을 생성해요.

오 씻
단순히 fetch join에서는 페이징이 안 된다라기 보다는
collectionFetch, 즉 일대다 연관관계를 fetch join으로 조회할 때 페이징이 작동하지 않는 거라고 봐도 되겠네요!
해결 시도 3 - BatchSize
작업의 성격이 일대다 조회인 이상
fetch join과 페이징은 함께할 수 없는 운명이다
대체 어찌해야 한단 말인가 고민하던 중

@BatchSize 라는 어노테이션의 존재를 알게 되었어요!
연관관계를 매핑하는 필드 위에 @BatchSize를 지정해주면
연관관계에 해당하는 엔티티를 조회할 때 'SELECT ~~ WHERE id = ?' 와 같은 단순 where 절이 아닌
'SELECT ~~ WHERE IN (-, -, -)' 처럼 IN 절을 사용해 조회해준다고 해요!
SQL에서 IN절을 사용해본 경험이 없어 많이 생소한데,
애플리케이션에 적용하여 직접 실험해보기로 했어요!
@BatchSize(size = 20) <-- BatchSize를 20으로 지정해보자!
@OneToMany(mappedBy = "post", fetch = FetchType.EAGER)
private List<PostImageInfo> postImageInfos;public interface PostRepository extends JpaRepository<Post, Long> {
// @Query("SELECT p FROM Post AS p LEFT JOIN FETCH p.postImageInfos")
// Slice<Post> findAll(PageRequest pageRequest);
<-- fetch join JPQL을 더이상 직접 사용하지 않는다
}이렇게 설정하고 전체 게시글 조회를 한다면
과연 어떤 쿼리가 날아갈까요!
두근두근
select
p1_0.id,
p1_0.content,
p1_0.created_at,
p1_0.member_id,
p1_0.price,
p1_0.title,
p1_0.view_count
from
post p1_0
order by
p1_0.created_at desc limit ?,
?일단 Post 조회 쿼리! limit 절이 쿼리에 추가됐어요 😮
select
m1_0.id,
m1_0.email,
m1_0.nickname,
m1_0.password,
m1_0.profile_image_info_id
from
member m1_0
where
m1_0.id=?다음은 member 조회 쿼리! 이전과 다른 게 없군요
이제 문제의 post_image_info 조회 쿼리!
select
p1_0.post_id,
p1_0.id,
p1_0.store_name
from
post_image_info p1_0
where
p1_0.post_id in (10,30,29,28,27,26,25,24,23,22,21,20,19,18,17,16,15,14,13,12);select
count(p1_0.id)
from
post p1_0오 씻~~~
원래는 20개의 게시글에 연관된 이미지 엔티티를 찾기 위해 20번의 쿼리를 날렸다면
지금은 in절을 사용해 한 번의 쿼리만으로 20개의 엔티티를 한꺼번에 가져오는 게 보이네요!
현재 batchSize의 크기를 20으로 설정해 두어서,
한 페이지에 조회할 게시글의 개수를 21개 이상으로 설정한다면
20개 단위로 쿼리가 나가게 될 거에요!
N+1번의 쿼리를 (N/20)+1로 만든 셈이네요 😎
그런데 신경쓰이는 점은 마지막에 나간 저 count 쿼리.
Page과 Slice의 차이점을 알아보셨다면 금방 아시겠지만
페이징 결과를 Slice로 가져오는 경우에는 저 count 쿼리를 보내지 않는 게 정상이에요.
오잉 왜 그럴까 찾아보았더니,
페이징 객체를 파라미터로 넘겨주는 메소드는 메소드 끝에 By를 붙여야 하네요!
public interface PostRepository extends JpaRepository<Post, Long> {
Slice<Post> findAllBy(PageRequest pageRequest);
}메소드 이름을 고쳐주었더니 count 쿼리도 더이상 나가지 않았어요.
그럼 해결 시도에 따른 결과를 정리해볼까요!
한 페이지 당 20개의 게시글을 조회한다고 가정했을 때
- findAll() 지연 로딩 : 게시글 SELECT 1 + 회원 SELECT 1 + 게시글 이미지 20 = 쿼리 22번!
- findAll() 즉시 로딩 : 게시글 SELECT 1 + 회원 SELECT 1 + 게시글 이미지 20 = 쿼리 22번! (findAll() 메소드 호출 시 한꺼번에 좌자작 나감)
- fetch join JPQL : 게시글 join 게시글 이미지 SELECT 1 + 회원 SELECT 1 = 쿼리 2번! (단, 쿼리에 페이징이 반영되지 않아 게시글 데이터를 풀스캔해 다 가져옴)
- BatchSize : 게시글 SELECT 1 + 회원 SELECT 1 + 게시글 이미지 SELECT 1 (in절을 이용해 20개 단위로 가져옴) = 쿼리 3개!
우리는 이 중 BatchSize를 설정함으로써 N+1문제를 해결하는 방법을 채택하였습니다.
프로젝트에 모니터링 시스템을 적용하게 된다면
위 네 가지 경우를 세팅한 후 부하 테스트를 진행해서
실제로 얼마만큼의 성능차이가 나는 지 실험해볼 예정이에요.
상상만 해도 신나네요!
그럼 이돈이면 팀의 첫 기술 포스팅을 마치겠습니다.
✌🏻






글 잘 봤습니다.