
이돈이면 팀 케로가 씀 ㅎㅎ
글이 길어져서 이번 글에서는 검색의 정확도를 높이는 것에 집중했습니다.
다음엔 검색 성능 발전사 로 돌아오도록..... 노력....
검색 기능은 우리 서비스에 맞게 검색어가 게시글의
제목과 내용에 일치하는 게시글들을 찾아오기로 팀에서 정했다.
🐸 1단계 - 정적 쿼리 (@Query)
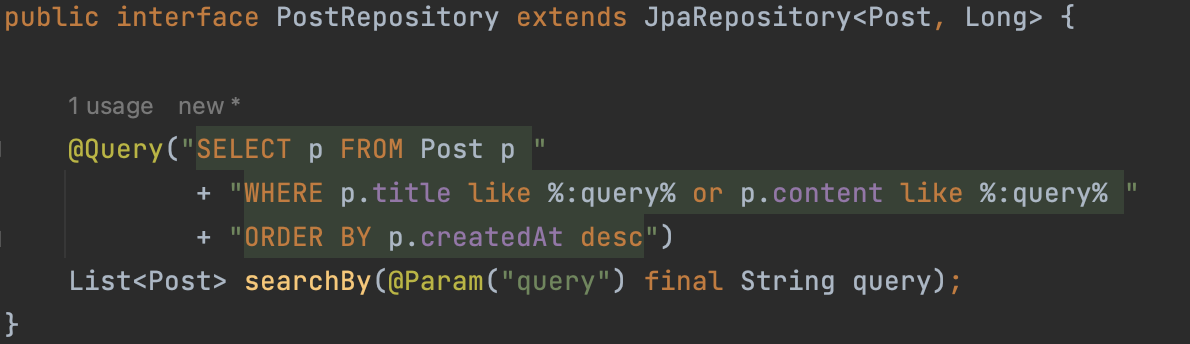
처음 구현은 @Query 어노테이션을 이용하여 직접 JPQL 정적 쿼리를 작성하여 간단하게 검색기능을 구현했다.
그러나
- 검색 조건이나 정렬 조건이 바뀔 수 있는데 위와 같이 정적 쿼리를 이용하여 고정해 두는 것이 싫다.
- JPQL 문법에 익숙치 않아서 대소문자가 헷갈림
- 쿼리문에 오류가 있을 때 컴파일 시점에서 알기 어려울 수 있다.
와 같은 단점들이 있다고 생각했다.
그 중 1번째가 가장 큰 이유였고 먼저 동적 쿼리를 이용할 수 있도록 변경하기로 하였다.
🐸 2단계 - 동적 쿼리 (Specification)
좀 더 유연하게 검색 기능을 만들기위해 찾아보던 중 Specification 이라는 것을 알게되었다.
QueryDSL와 Specification 사이에서 어떤 것을 사용할지 고민을 했지만 specification이 러닝커브가 더 적어보였고, 이미 만들어져 있는 pageRequest를 그대로 가져다가 사용할 수 있을 것 같아 서 specification로 구현하였다.

기존의 PostRepository 가 JpaSpecificationExecutor 클래스를 상속받도록 하고
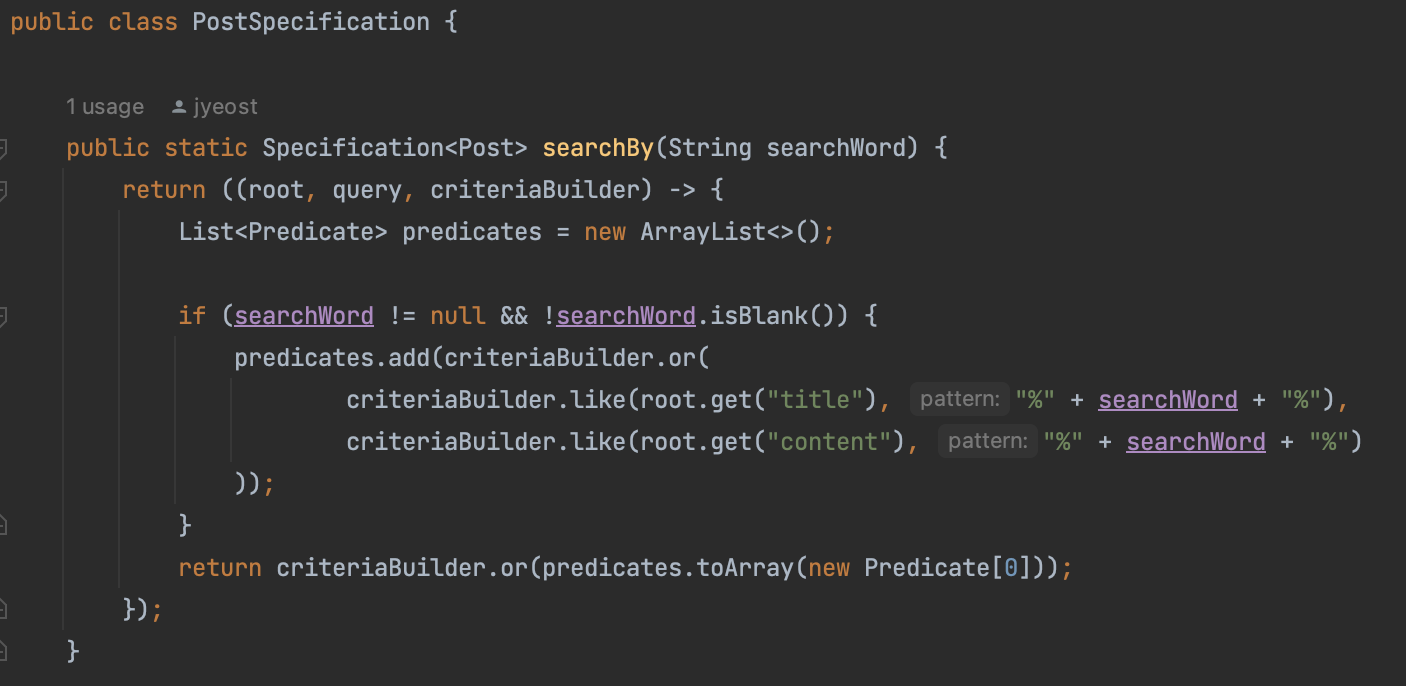
Specification 데이터 타입을 반환하는 클래스와 메서드를 만들었다.
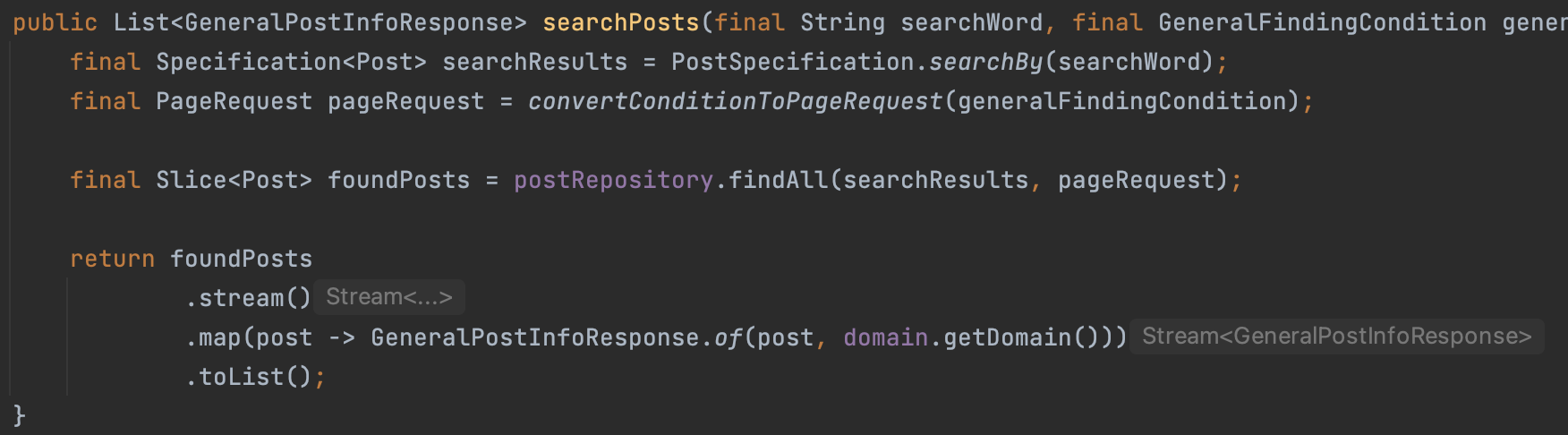
JpaSpecificationExecutor가 제공하는 메서드 중,
다른 팀원이 만들어둔 Page (size, page, 정렬조건, 정렬순서) 들을 사용할 수 있는 findAll() 메서드를 사용하여 구현하였다.
n+1 문제
그러나 지난 전체 게시글 조회와 마찬가지로 n+1 문제가 발생하였다.
여기 까지 구현에서 검색에서 쿼리는 아래의 순서로 진행되고 있었다.
- 게시글을 검색하여 페이지 사이즈 만큼 게시글을 가져온다
- 각 게시글의 작성자를 불러 온다
- 게시글에 해당하는 사진을 가져온다 (사진(oneToMany)은 이미 batchSize 설정이 되어있었으므로 in절로 가져 올 수 있었다. )
이 n+1 문제는 조회된 게시글에서 작성자를 불러오는 과정에서 발생하였다.

이 문제는 게시글 전체 조회에서 미리 n+1의 문제를 만난 여우의 포스팅을 참고해가며 해결할 수 있었다
Post 엔티티에 Member는 @ManyToOne으로 매핑되어있었기 때문에 레포지터리에서 ****@EntityGraph 옵션을 붙여 fetch join 하여, 한번에 조회하도록 했다.

JpaSpecificationExecutor의 findAll메서드를 인터페이스에서 정의 하고
@EntityGraph 옵션을 붙여 member로 fetch join이 가능하도록 해주었다.
// 적용 전 검색 게시글 조회
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
where p1_0.title like replace('%애퓨%','\\','\\\\')
or p1_0.content like replace('%애퓨%','\\','\\\\')
order by p1_0.created_at desc limit 0,20;// 적용 후 검색 게시글 조회
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,**m1_0.id,m1_0.email,m1_0.nickname,m1_0.password,m1_0.profile_image_info_id**,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
**join member m1_0
on m1_0.id=p1_0.member_id**
where p1_0.title like replace('%애퓨%','\\','\\\\')
or p1_0.content like replace('%애퓨%','\\','\\\\')
order by p1_0.created_at desc limit 0,20;Post의 정보와 함께 회원 정보를 찾아오기 때문에 기존에 회원 아이디로 회원 하나하나를 직접 찾던 +n 개의 쿼리문을 사용하지 않을 수 있었다.
Specification 동적 쿼리 만들기
처음 목적이 조금 더 확장성 있는 쿼리를 만들기 위해서 였기 때문에 가상으로
- 닉네임 검색을 추가하고
- 페이징 조건
- order 조건들을
클라이언트에서 받아와서 검색하는 코드를 구현하고 테스트를 해 보았다.
PostSpecification class
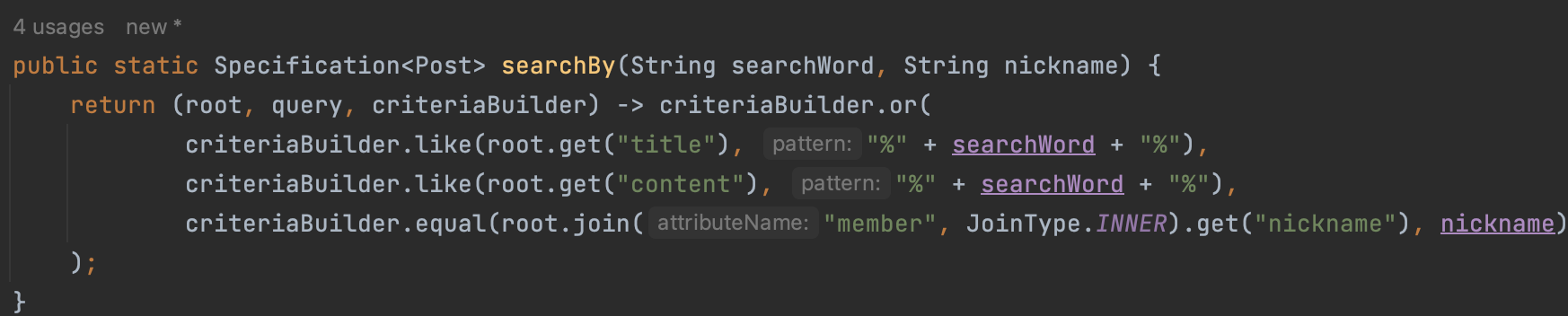
public static Specification<Post> searchBy(String searchWord, String nickname) {
return ((root, query, criteriaBuilder) -> {
List<Predicate> predicates = new ArrayList<>();
if (searchWord != null && !searchWord.isBlank()) {
predicates.add(criteriaBuilder.or(
criteriaBuilder.like(root.get("title"), "%" + searchWord + "%"),
criteriaBuilder.like(root.get("content"), "%" + searchWord + "%")
));
}
if (nickname != null && !nickname.isBlank()) {
predicates.add(criteriaBuilder.or(
criteriaBuilder.equal(root.join("member", JoinType.INNER).get("nickname"), nickname)
));
}
return criteriaBuilder.or(predicates.toArray(new Predicate[0]));
});
}테스트 코드와 sql문
@Test
void 동적쿼리_확인_제목만으로() {
Specification<Post> 사과 = PostSpecification.searchBy("사과", null);
List<Post> 사과검색결과 = postRepository.findAll(사과);
assertThat(사과검색결과.size()).isEqualTo(1);
}
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
where p1_0.title like '%사과%' escape ''
or p1_0.content like '%사과%' escape '';@Test
void 동적쿼리_확인_닉네임만으로() {
Specification<Post> 저리내 = PostSpecification.searchBy(null, "저리내");
List<Post> 저리내검색결과 = postRepository.findAll(저리내);
assertThat(저리내검색결과.size()).isEqualTo(2);
}
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
join member m1_0
on m1_0.id=p1_0.member_id
where m1_0.nickname='저리내';@Test
void 동적쿼리_확인_아무것도_없을때() {
Specification<Post> 아무것도_안함 = PostSpecification.searchBy(null, null);
List<Post> 아무것도_안함_검색결과 = postRepository.findAll(아무것도_안함);
assertThat(아무것도_안함_검색결과.size()).isEqualTo(0);
}
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
where 1!=1;@Test
void 동적쿼리_확인_sort조건_변경() {
Specification<Post> 저리내 = PostSpecification.searchBy(null, "저리내");
PageRequest page = PageRequest.of(0, 3, Sort.Direction.ASC , SortBy.CREATE_AT.getName());
List<Post> 저리내검색결과 = postRepository.findAll(저리내, page).stream().toList();
assertSoftly(softly -> {
softly.assertThat(저리내검색결과.size()).isEqualTo(2);
softly.assertThat(저리내검색결과.get(0).getId()).isEqualTo(postId1);
softly.assertThat(저리내검색결과.get(1).getId()).isEqualTo(postId2);
}
);
}
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,m2_0.id,m2_0.email,m2_0.nickname,m2_0.password,m2_0.profile_image_info_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
join member m1_0
on m1_0.id=p1_0.member_id
join member m2_0
on m2_0.id=p1_0.member_id
where m1_0.nickname='저리내'
order by p1_0.created_at
offset 0 rows fetch first 3 rows only;@Test
void 동적쿼리_확인_paging조건_sort조건_변경() {
Specification<Post> 저리내 = PostSpecification.searchBy(null, "저리내");
PageRequest page = PageRequest.of(0, 1, Sort.Direction.DESC , SortBy.CREATE_AT.getName());
List<Post> 저리내검색결과 = postRepository.findAll(저리내, page).stream().toList();
assertSoftly(softly -> {
softly.assertThat(저리내검색결과.size()).isEqualTo(1);
softly.assertThat(저리내검색결과.get(0).getId()).isEqualTo(postId2);
}
);
}
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,m2_0.id,m2_0.email,m2_0.nickname,m2_0.password,m2_0.profile_image_info_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
join member m1_0
on m1_0.id=p1_0.member_id
join member m2_0
on m2_0.id=p1_0.member_id
where m1_0.nickname='저리내'
order by p1_0.created_at desc
offset 0 rows fetch first 1 rows only;주의점
Specification으로 동적 쿼리를 만들 때 입력값이 null, 빈 값이 들어올 경우를 반드시 처리를 해주어야 한다.
이와 같이 아무런 처리 없이 구현한다면 아래와 같은 쿼리를 만나볼 수 있다.
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
join member m1_0
on m1_0.id=p1_0.member_id
where p1_0.title like '%사과%' escape ''
or p1_0.content like '%사과%' escape ''
or ***m1_0.nickname=NULL;***
select p1_0.id,p1_0.content,p1_0.created_at,p1_0.member_id,p1_0.price,p1_0.title,p1_0.view_count
from post p1_0
join member m1_0
on m1_0.id=p1_0.member_id
where ***p1_0.title like '%%' escape ''
or p1_0.content like '%%' escape ''***
or m1_0.nickname='저리내';널처리나 빈 값 처리를 따로 해주지 않으면 해당 항목을 NULL이나 '' 로 조회할 수 있기 때문에 반드시 null처리를 해주어야한다
특히 제목이나 내용을 '' 로 조회하게 된다면 모든 게시글이 조회될 가능성이 있기 때문에 주의해야 한다.
🐸 3단계 - 검색 기능 개선
검색 정확도 개선
기존의 검색기능은 검색한 내용이 전부 일치해야 조회가 되었다. 예를 들면 '다이슨 청소기' 와 같은 검색 키워드로 '청소기 사려는데 다이슨 어떤가요?' 와 같은 글을 검색할 수 없었다.
그래서 띄어쓰기를 기준으로 검색어를 나누고 해당하는 검색어를 모두 포함한 게시글을 조회할 수 있도록 했다.
public static Specification<Post> searchBy(String searchWord) {
return ((root, query, criteriaBuilder) -> {
List<Predicate> predicates = new ArrayList<>();
if (searchWord != null && !searchWord.isBlank()) {
appendSearchCondition(searchWord, root, criteriaBuilder, predicates);
}
return criteriaBuilder.***and***(predicates.toArray(new Predicate[0]));
});
}
private static void appendSearchCondition(String searchWord, Root<Post> root, CriteriaBuilder criteriaBuilder, List<Predicate> predicates) {
List<String> searchWords = splitKeyWordByBlank(searchWord);
for (String word : searchWords) {
predicates.add(criteriaBuilder.***or***(
criteriaBuilder.like(root.get("title"), "%" + word + "%"),
criteriaBuilder.like(root.get("content"), "%" + word + "%")
));
}
}where (p1_0.title like replace('%거지%','\\','\\\\') or p1_0.content like replace('%거지%','\\','\\\\'))
and (p1_0.title like replace('%자취%','\\','\\\\') or p1_0.content like replace('%자취%','\\','\\\\'))
and (p1_0.title like replace('%사회%','\\','\\\\') or p1_0.content like replace('%사회%','\\','\\\\'))
and (p1_0.title like replace('%거지%','\\','\\\\') or p1_0.content like replace('%거지%','\\','\\\\'))
and (p1_0.title like replace('%초년%','\\','\\\\') or p1_0.content like replace('%초년%','\\','\\\\')) 구현을 하고나니 키워드가 많아질수록 성능에 영향을 많이 미칠지 궁금해졌다
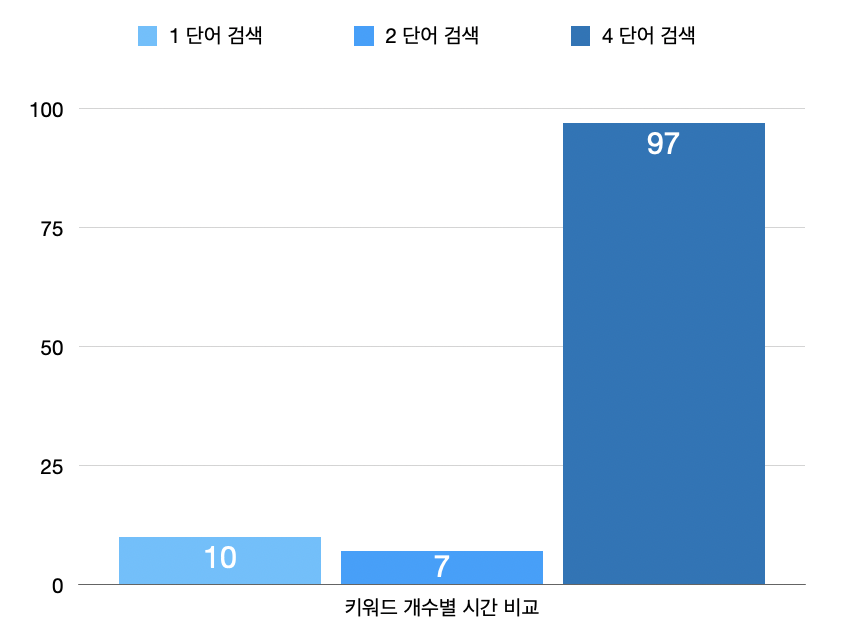
그래서 1000글자의 본문의 글을 한 단어와 2단어, 4단어로 검색하여 각각 걸린 시간을 비교하였다.
- 페이지 사이즈 20, 1번째 페이지, 최신순 정렬
- 테스트는 Jmeter로 실행
- 요청은 각각 1,000건씩 보내보았다.
키워드 개수 별 비교
- 시간별 비교
- 시간 당 처리량 비교
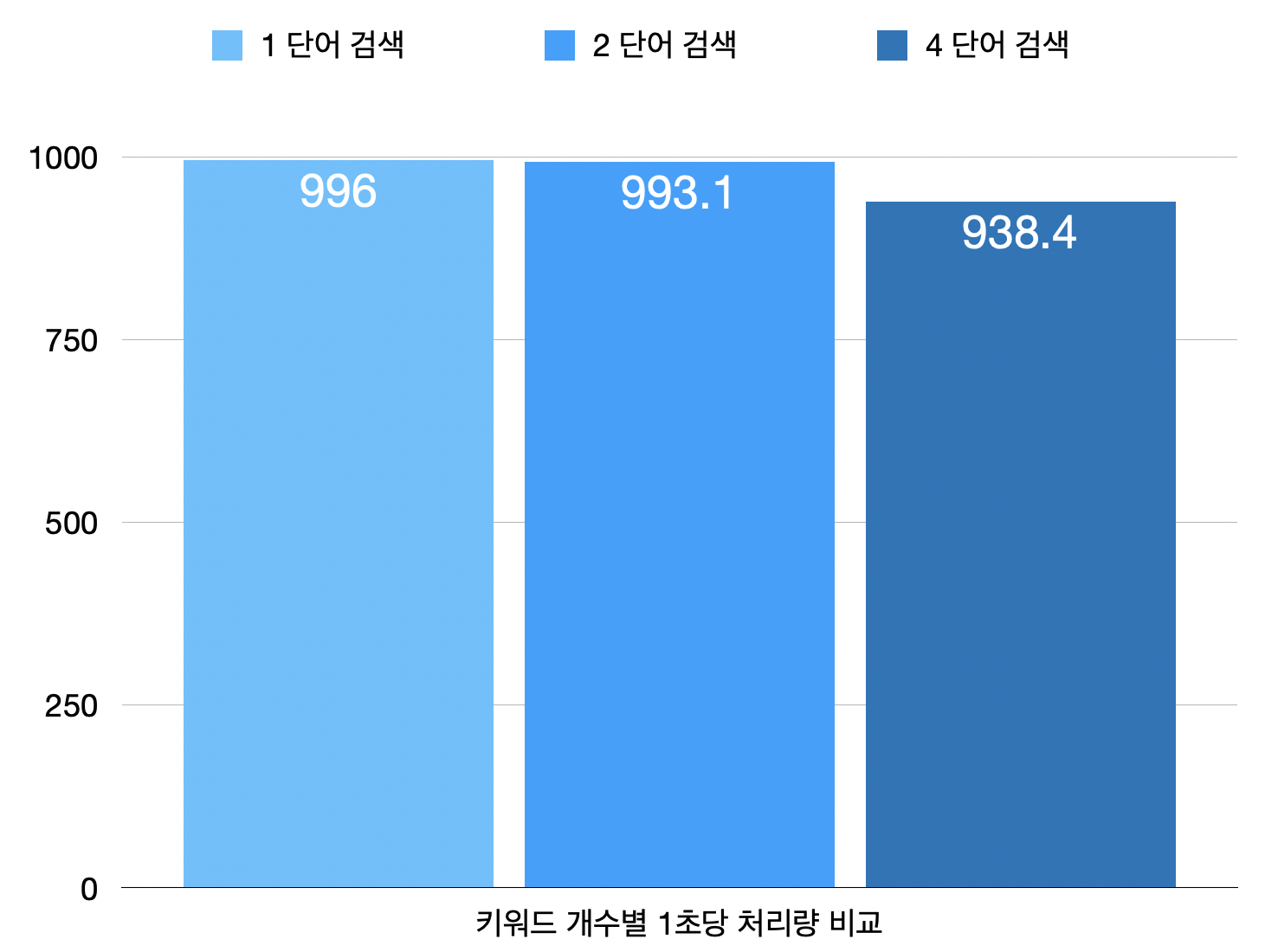
1단어와 2단어의 경우, 성능 테스트를 여러 번 진행하여도 거의 비슷한 값이 나왔다.
3단어이상부터는 시간은 느려지고 처리량은 줄어들었다.
키워드가 많아질수록 or 연산과 and 연산이 많아지기 때문에 느려지는 것은 어쩔 수 없다.
그러나 키워드로 검색할때 세 단어 이상 검색하는 일은 잘 없기 때문에 이 구현방법 그대로 진행하기로 하였다.

좋은 글 감사합니다.