SQLP
1.[SQLP]그룹함수(GROUP BY,ROLLUP,CUBE,GROUPING SETS)

그룹 함수(Group Functions) 또는 집계 함수(Aggregate Functions)는 여러 행의 값을 하나의 결과로 집계할 대 사용되는 함수들이다. GROUP BY,ROLLUP,CUBE,GROUPING SETS등이 있다.\-샘플 데이터GROUP BY는 지정된
2.[SQLP]SUM()함수에서 NULL값의 처리

SUM(col1+col2)랑 SUM(col1)+sum(col2)의 차이에 대해 알아보려고 한다.테스트 데이터col1의 합계와 col2의 합계를 각각 구한 후, 그 값을 더한다. NULL 값은 합계에 포함되지 않으므로, NULL이 있는 행은 제외된다.따라서, SUM(co
3.[SQLP]그룹 내 순위 분석 함수(ROW_NUMBER, RANK, DENSE_RANK)
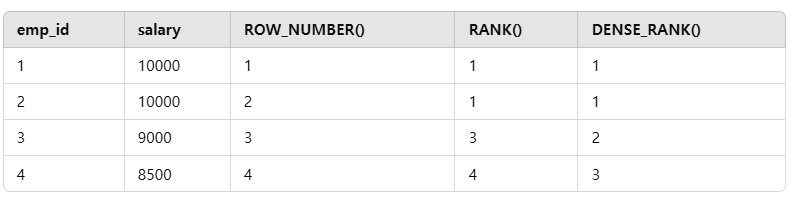
순위 분석 함수는 데이터를 순위별로 정렬하거나 순위를 매기는 데 사용되는 SQL 함수들이다. Oracle SQL에서는 주로 ROW_NUMBER, RANK, DENSE_RANK 함수가 사용된다. 이 함수들은 데이터를 정렬한 후 각 행에 대해 순위를 부여하지만, 순위를 처
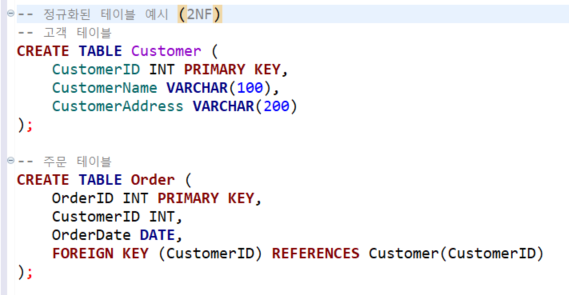
4.[SQLP]정규화(Normalization) (1NF - 3NF)
데이터베이스 설계에서 중복을 최소화하고 무결성을 유지하기 위해 데이터를 분리하고 구조를 최적화하는 과정 1차 정규화는 데이터베이스의 터이블을 정리하여 각 컬럼에 대해 원자값만 포함하도록 하는 규칙으로 반복되는 그룹이나 여러 값을 한 컬럼에 넣는 문제를 해결.1NF
5.[SQLP]반올림,버림,올림/내림(ROUND, TRUNC, CEIL, FLOOR)
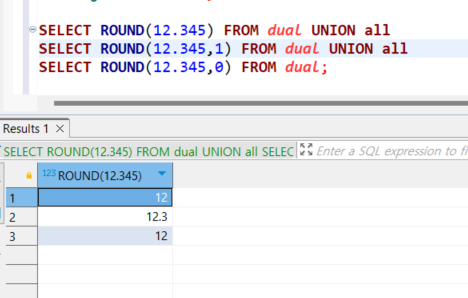
ROUND함수는 숫자를 지정한 자릿수로 반올림하는 함수로 자릿수를 지정하지 않으면 소수점 아래 첫번째자리에서 반올림한다.TRUNC함수는 숫자를 지정한 자릿수로 잘라내기 하는 함수로 반올림없이 단순히 숫자의 자릿수만큼 자른다TRUNC(잘라낼 숫자,잘라낼 자릿수(생략가능)
6.[SQLP]오라클 조인(LEFT JOIN,RIGHT JOIN,INNER JOIN,CROSS JOIN,FULL OUTER JOIN)
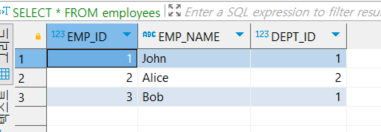
\*샘플데이터\-- Departments 테이블 생성DROP TABLE departments;CREATE TABLE departments ( dept_id INT PRIMARY KEY, dept_name VARCHAR(100));\-- Employees 데이
7.[SQLP]반정규화
정규화는 데이터 중복을 최소화하고, 일관성을 유지하는 데 중점을두고 반정규화는 성능을 향상시키기위해 중복을 허용하거나 테이블을 합치는 방법이다.조회 성능 향상 정규화된 테이블은 여러 번의 조인을 필요로 하기 때문에 성능에 문제가 생길 수 있으나 반정규화는 조회 성능을
8.[SQLP]트랜잭션 특징
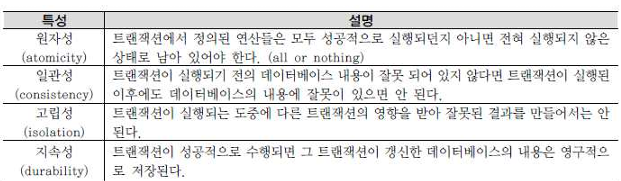
원일고지
9.[SQLP]엔티티
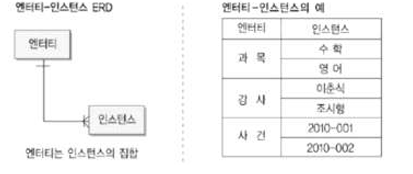
업무에 필요한 정보를 저장하고 관리하기 위한 집합적인 것(객체,실체)엔티티는 인스턴스의 집합이다.유형,무형에 따른 분류(유개사) 1) 유형 엔티티: 물리적인 형태가 있고 눈에 보이며 실제로 존재하는 엔티티로 안정적이고 지속적으로 활용할 수 있다. ex)교수, 강의실,
10.[SQLP] 계층형 질의(Hierarchical Queries)

🤷♀️ 계층형 질의란? 계층형 질의 (Hierarchical Queries)는 관계형 데이터베이스에서 부모-자식 관계를 표현하고 탐색하는 데 사용된다. 주로 트리 구조나 계층적 데이터 모델을 다룰 때 유용하며, 계층 구조를 명시적으로 나타내거나 계층 관계를 순차적
11.[SQLP]NULL처리
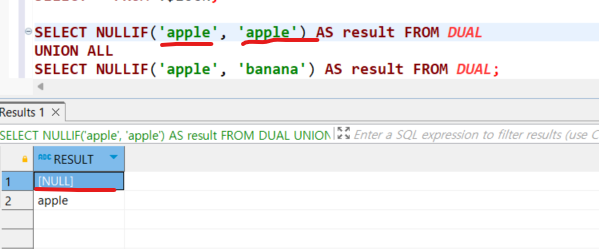
두 값이 같으면 NULL, 그렇지 않으면 첫번째 값을 반환NULL이 아닌 첫번째 값을 반환첫번째 값이 NULL이 아니면 두번째를 반환, NULL이면 세번째 값을 반환값이 null인 경우 대체 값을 반환SELECT ISNULL(NULL, '대체 값') AS result;
12.[SQLP] UNDO vs REDO
트랜잭션을 취소(롤백)할 때 읽기 일관성을 제공하기 위해변경 이전의 이전값을 저장함주로 ROLLBACK,읽기 일관성, 실패 시 데이터 복구에 사용됨예시)UPDATE employees SET salay = 5000 where id =1;UNDO에는 salary의 이전값(
13.[SQLP]노랭이 146P.22번
문제가장 최근에 수행한 SQL에 대한 실제 실행계획을 확인 할 수 있는 오라클 성능관리 도구 DBMS_XPLAN 패키지 함수는?DBMS_XPLAN.DISPLAY: SQL 실행 계획을 텍스트 형태로 출력2\. DBMS_XPLAN.DISPLAY_CURSOR: 가장 최근에
14.[SQLP]AutoTrace 옵션(노랭이 147p.24번)
AutoTrace는 Oracle SQL\*Plus에서 제공하는 기능으로, 쿼리 실행 계획과 성능 정보를 자동으로 추적하고 결과를 출력해주는 도구로 쿼리 최적화와 성능 분석에 사용된다. AutoTrace는 쿼리 실행 후 해당 쿼리의 실행 계획, I/O통계, CPU 시간등
15.[SQLP]B-Tree인덱스,Bitmap인덱스,Clustered인덱스
B-Tree는 가장 일반적인 인덱스로 데이터베이스의 기본 인덱스 형태로, 트리 구조를 이용해 빠른 검색을 제공한다.\- 빠른 범위 검색 :B-Tree 인덱스는 정렬된 트리 구조이므로 범위 검색(>, <, BETWEEN 등)이 빠르다.동적 크기 조정: 데이터가 삽입
16.[SQLP]CBO(비용기반 옵티마이저) vs RBO(규칙기반 옵티마이저)
CBO는 쿼리 실행 계획을 결정할 때, 쿼리 실행에 소요되는 비용을 평가하여 최적화된 실행 계획을 선택하는 방식이다. CBO는 통계 정보(EX.테이블크기, 인덱스 분포)와 비용 모델을 기반으로 최적화 한다.작동원리CBO는 쿼리 실행에 대한 여러 가능한 계획을 평가하고,
17.[SQLP]트랜잭션 Dirty Read, Non-Repeatable Read,Phantom Read/트랜잭션 격리성 수준
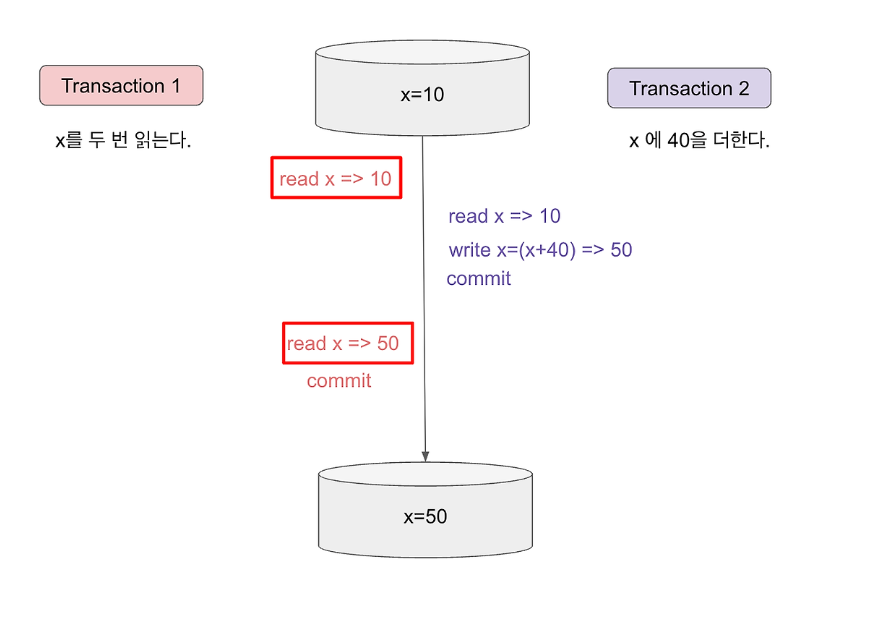
아직 커밋되지 않은 수정 중인 데이터를 다른 트랜잭션에서 읽을 수 있도록 허용할 때 발생한다. select sum(잔고) from 계좌;라는 문장이 Dirty Read를 허용하는 상황에서 이 문장이 수행되고 다른 트랜잭션에 계좌 잔고를 변경한다면?? 쿼리의 최종 결과
18.[SQLP]리스트 파티셔닝(List Partitioning),Range Partition,Hash Partition
😺List Partitioning 특정 열의 값을 기준으로 테이블을 여러 개의 파티션으로 나누는 데이터베이스 파티셔닝 기법 중 하나이다.각 파티션은 특정 값 목록을 포함하며,해당 목록에 포함된 값을 가진 행들만 해당 파티션에 저장된다. 리스트 파티셔닝의 특징 *책보고 적어 리스트 파티셔닝 예시 쿼리의 조건을 보면 2021년에 해당하
19.[SQLP]Oracle PIVOT/UNPIVOT
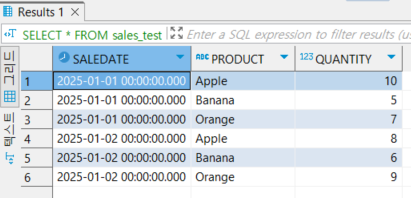
행(가로) 데이터를 열(세로) 데이터로 변환문법 select \* from (피봇할 쿼리문) pivot(그룹함수(집계컬럼) for 피벗대상컬럼 in(피벗컬럼값 AS 별칭...) SaleDate별로 Product('Apple', 'Banana', 'Orange')의
20.[SQLP]국가공인 SQLP 자격검정 핵심노트1 / 오라클 성능 고도화 원리와 해법1 - SQL 수행구조
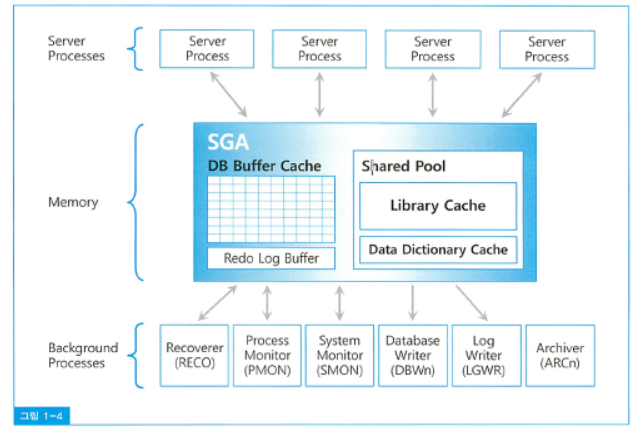
데이터베이스(Database) : 디스크에 저장된 데이터 집합(Datafile,Redo Log File, Control File)등인스턴스(Instance) : SGA 공유 메모리 영역과 이를 액세스하는 프로세스 집합(서버프로세스 + 백그라운드 프로세스)오라클에 접속하