
오늘 하루엔 뭐했니?
그냥 적어봐! LEE렇게!
2020.05.31 LEE'Today_회고록
목차
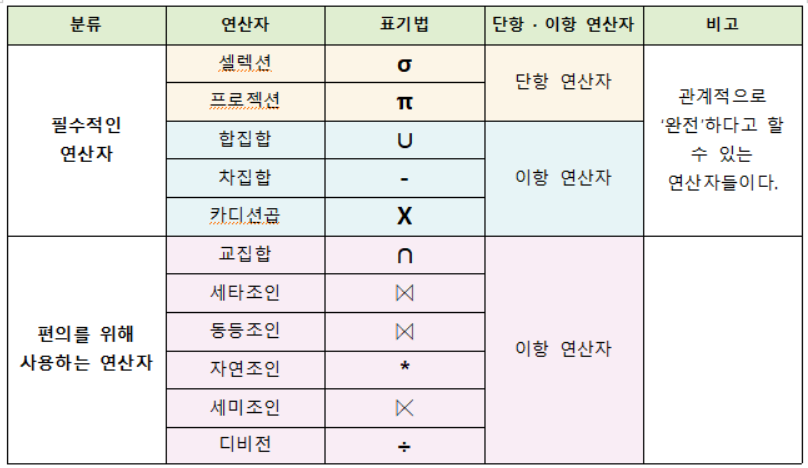
1. 관계대수
2. 관계대수 ~> SQL
3. SQL
4. 마무리
1. 관계 대수
관계대수가 뭐에요?..
관계형데이터 모델링에는 두 가지 언어가 존재하죠!
바로 관계해석과 관계대수입니다.
- 관계해석 : 원하는 데이터만 명시하고 "어떻게 질의를 해석하는가"에 대해 언급이 없는 선언적 언어이다.
- 관계대수 : "어떻게 질의를 해석하는가"에 대해 언급하는 절차적 언어이다.
1-1. 관계대수
특징
- 단일 혹은 두 개의 테이블들을 입력 받아 결과 테이블을 생성한다.
- 집합 연산을 토대로 만든 것이 관계 대수이며, 기본적으로는 집합 연산자에 속한다.
종류
<보기> EMP Table & DEP Table
FROM EMP
- EMPNO : 사원 번호
- EMPNAME : 이름
- TITLE : 직급
- SALARY : 급여
- DNO : 부서
FROM DEP
- DEPNO : 부서번호
- DEPNAME : 부서이름
1-2. 셀렉션(1/8)
- 원하는 데이터를 수평적으로 도출함!
- 중복이 존재하지 않음.
(아래첨자가 안먹히네요..흐음)예제
 질의가 3번 부서의 정보가 궁금했나봅니다.
질의가 3번 부서의 정보가 궁금했나봅니다.
그렇다면 3번인 분을 찾아보니 이기백씨네요!
이기백씨의 정보를 모두 수평적으로 검색하는 것이 셀렉션입니다!
1-3. 프로젝션(2/8)
- 원하는 데이터를 수직적으로 도출함!
- 중복이 나타날 수 있음.
예제
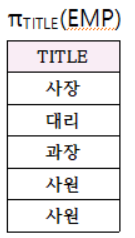 질의가 무슨 직급들이 있나 궁금했나보군요!
질의가 무슨 직급들이 있나 궁금했나보군요!
프로젝션을 이용하면 수직적으로 정보를 도출할 수 있습니다.
EMP 테이블에 있는 TITLE부분을 프로젝션했더니 다음과 같은 결과가 나오군요!
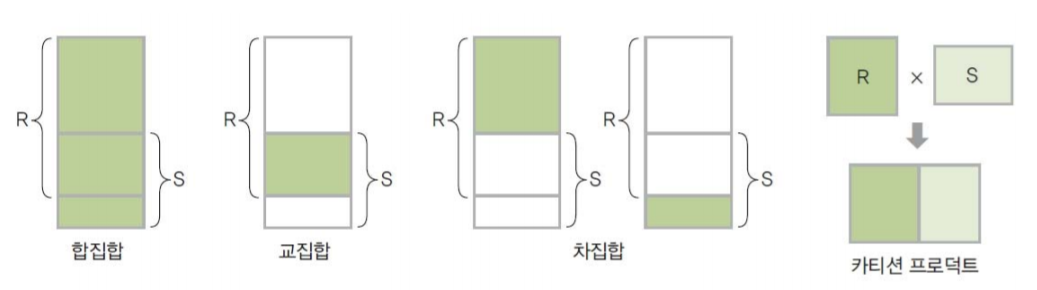
1-4. 합집합(3/8)
- 합집합은 합집합 호환 조건이 따로 있답니다! 조건에 맞아야만 실행할 수 있죠.
※ 합집합 호환 조건
합집합을 아시려면 좋든 싫든..! 호환 조건에 따라야합니다!
두 릴레이션의 차수가 같고, 대응되는 도메인도 같아야합니다.
이 규칙은 합집합, 차집합, 교집합에 모두 적용됩니다.예제
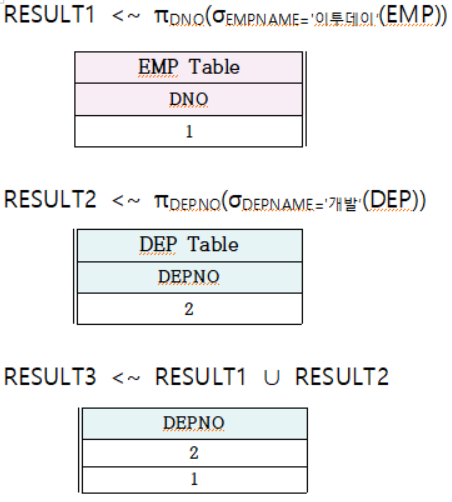 질의를 보아하니, 셀렉션과 프로젝션을 이용해보고, 합쳐주었군요!
질의를 보아하니, 셀렉션과 프로젝션을 이용해보고, 합쳐주었군요!
대응되는 도메인이 같고, 차수도 같죠?
합집합 호환조건에 성립되네요!셀렉션과 프로젝션부분을 배웠으니 금방 이해하셨을 것이라 생각합니다.
다음 예시적인 부분은 햇갈리는게 많겠군요. 왜 DEPNO이지?
이 부분에 대해서는 알려주는 곳마다 많이 제각각이라고 합니다.
그래서 다른 예시를 들자면...
 주로 이런 로직을 갖고있죠.
주로 이런 로직을 갖고있죠.
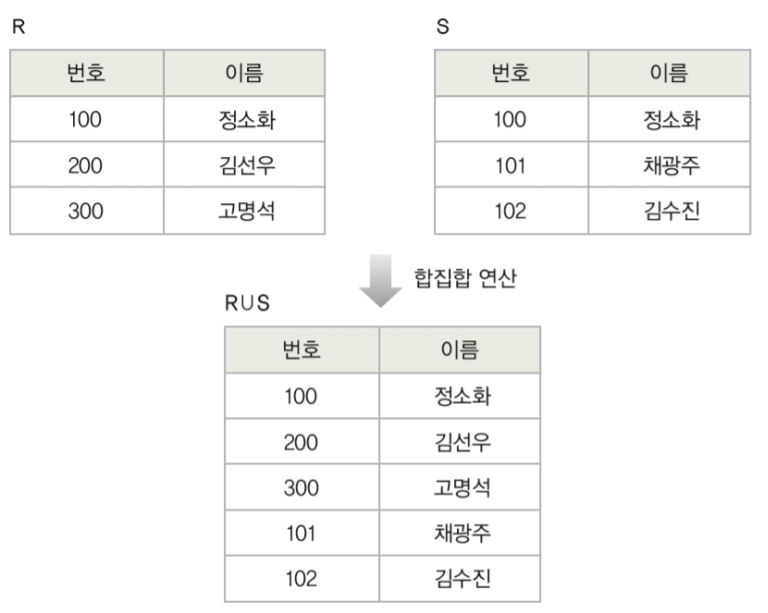 이해가 되시나요?! 같은 차수와 대응되는 도메인이 같고, 합쳐지니 중복된 부분은 사라졌습니다.
이해가 되시나요?! 같은 차수와 대응되는 도메인이 같고, 합쳐지니 중복된 부분은 사라졌습니다.
신기합니다!
1-5. 교집합(4/8)
- 교집합도 마찬가지로 합집합 호환조건이 필수적이죠.
예제
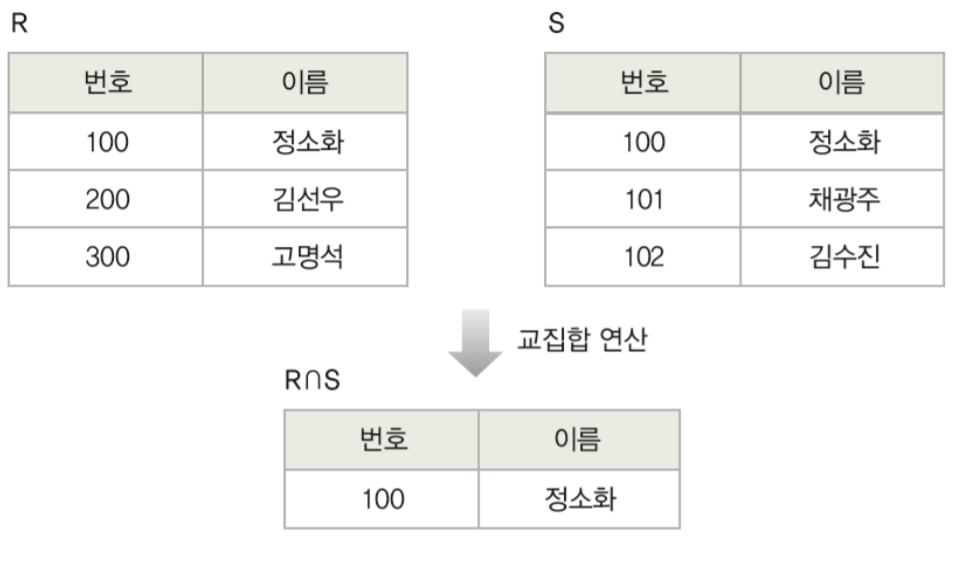 합집합에서 중복되어 사라졌던 것만! 보여집니다.
합집합에서 중복되어 사라졌던 것만! 보여집니다.
수학에서 보았던 교집합 그대로군요!
1-6. 차집합(5/8)
- 차집합도 마찬가지로 합집합 호환조건이 필수적입니다.
예제
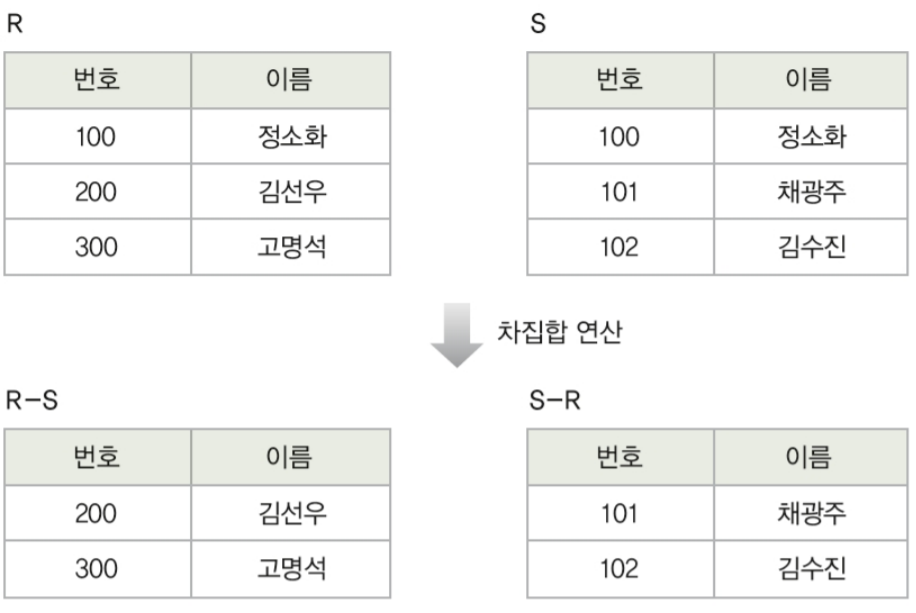 어떤 모습인지 아시겠나요?
어떤 모습인지 아시겠나요?
벤다이어그램으로 한번 본다면,
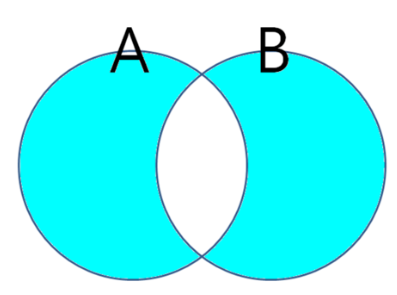 다음과 같겠죠?
다음과 같겠죠?
A가 R이며, B가 S로 생각하시면 됩니다!
1-7. 카디션 곱(6/8)
- 카디션 곱? 이게 뭐지...
- 두 릴레이션(테이블) R과 S가 존재하면 두 테이블로 만들 수 있는 모든 경우의 수를 나타내는 연산자입니다!
- 이 기능은 뒷부분에 있는 쪼개진 정규화들의 질의를 주로 해결하기 위한 통합연산자로 사용되기도 합니다!
예제
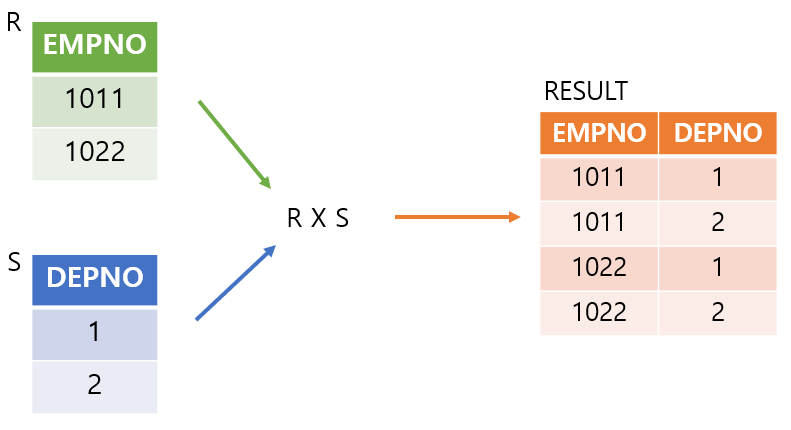 R과 S의 릴레이션에 속해있는 모든 경우의 수들을 테이블화 시켜주는 연산자입니다!
R과 S의 릴레이션에 속해있는 모든 경우의 수들을 테이블화 시켜주는 연산자입니다!
행렬의 곱이 생각나네요?
행렬의 곱도 행렬 속에있는 숫자끼리 한번씩 마주하지요?
같은 맥락으로 이해하시면 될 것 같습니다!
1-8. 조인(7/8)
- 조인... 너무 중요하죠
- 두 테이블의 연관된 칼럼끼리 통합해주는 연산자입니다.
- 관계 대수에서는 상호 연산이 안된 데이터는 명시되지 않습니다!
종류
- 세타조인 : 세타는 { <>, =, <=, >=, <, >} 중 하나이다.
- 동등조인 : 세타 중 비교연산자인 '='만 활용한 조인
- 자연스럽게 연관된 부분을 조인시키고 가장 활용도가 높다.
예제
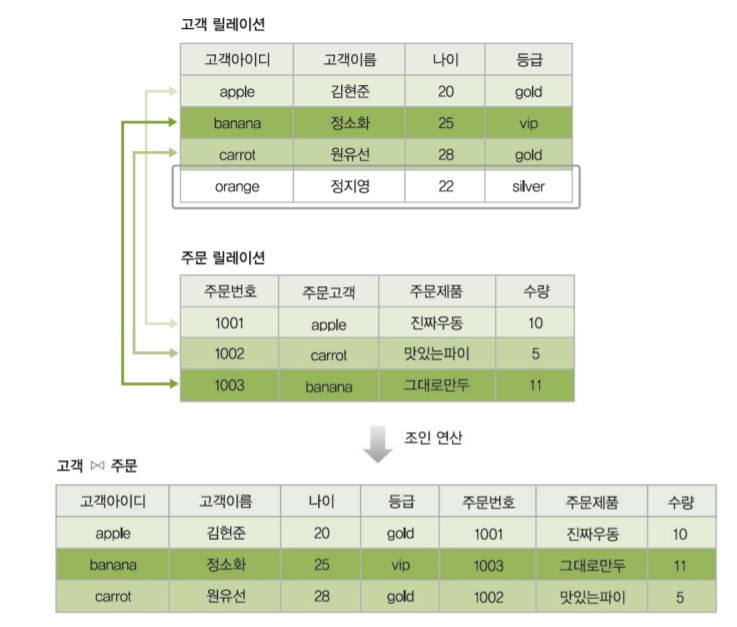 고객 릴레이션과 주문 릴레이션을 조인 연산을 실행한 결과입니다.
고객 릴레이션과 주문 릴레이션을 조인 연산을 실행한 결과입니다.주문 고객에 따라 조인이 된 상태이며 상호 연산이 없는 정지영고객은 명시되지 않았네요!
1-9. 디비전(8/8)
수학적해석
차수가 n+m인 릴레이션 R(A1, A2, ... , An, B1, B2, ... , Bm)
차수가 m인 릴레이션 S(B1, B2, ... , Bm)의
디비전 R÷S는 차수가 n이고, S에 속하는 투플에 대하여,
투플 tu(투플 t와 u를 결합한 것)가 R에 존재하는 투플 t의 집합
예제
모두 결과를 보면 나눠지는 C부분에 포함된 A# 투플의 결과이다.
나눠지는 b(?)의 모든 부분을 가지고 있는 A#의 a(!)만 가져온다!
2. 관계대수 ~> SQL
음.. 그럼 관계대수는 알았고, SQL은 뭐죠?
라는 답변에는 이렇게 대답하겠습니다!
이러한 다양한 연산들이 있는 관계대수에도 한계가 명확히 존재합니다.
관계대수의 한계
- 정렬이 안된다.
- 집단 함수를 지원하지 않는다.
- 산술 연산(+, -, *, /)을 못한다.
- 데이터 베이스를 수정할 수 없다.
- 결과에 중복된 투플들을 명시하고 싶을 때, 명시하지 못한다.
이러한 한계를 극복하기 위해 확장을 시키고,
확장을 시킨 후 투플기반의 관계해석과 결합한 것이 SQL입니다!
- SQL = 관계대수 + 투플기반의 관계해석
그럼 관계대수의 확장된 기능으로는 무엇이 존재할까요?
2-1. 집단함수(1/3)
집단함수는 다양한 연산들을 가능하게 합니다.
주로 AVG, SUM, MIN, MAX, COUNT를 사용하게 되죠!
예제
AVG_SALARY(EMP) = 320,000
MAX_SALARY(EMP) = 500,000
_SALARY : 아랫첨자
2-2. 그룹화(2/3)
그룹화는 원하는 목록을 그룹으로 묶어주는데 예제로 살펴보죠!
주로 각 부서별 사원들의 급여 평균은 얼마일까?
예제
DNOgAVG_SALARY(EMP) 는?
DNO에 따라 그룹화가 진행되었죠!
그룹은 급여의 평균들로 맺어졌군요! 완벽해요!
2-3. 외부조인(3/3)
조인이 문제가 뭐가 있었을까요?...
- 조인의 문제점은 상호 연산이 없는 데이터들이 배제당한다는 것입니다.
- 그래서 배제당하는 데이터들도 표현해주기 위해 외부조인이 등장했답니다!
예제
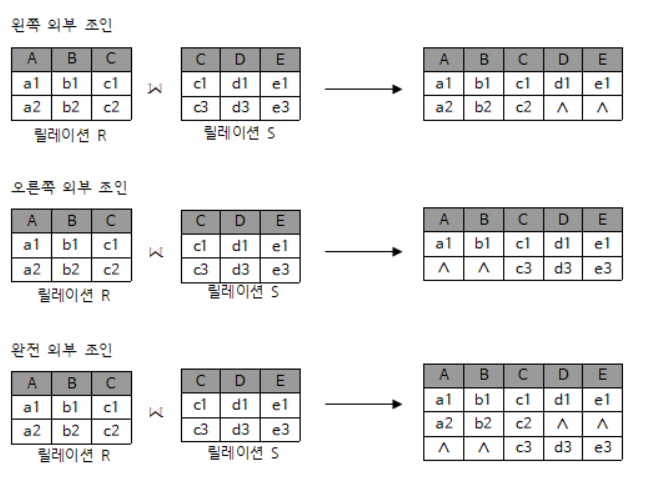 신기하죠?
신기하죠?
비어있는 공간들은 모두 null로 표현이 되었답니다!
우린 이제 드디어 관계대수의 역사를 밟아 왔습니다.
이제 SQL을 보게될텐데요!
기본적으로 SQL은 관계대수의 영향을 받으면서도 관계해석의 영향도 받죠.
관계해석?
정의
원하는 데이터만 명시하고 질의를 어떻게 수행할 것인가는 명시하지 않는 선언적인 언어죠.특징
- 비절차 언어
- 투플 관계 해석과 도메인 관계 해석이 있다.
- 기본적으로 관계해석과 관계대수는 관계 데이터베이스를 처리하는 기능과 능력면에서 동등
- 연산들의 절차를 사용하여 데이터를 가져온다.
- 기본적인 연산자로 union, intersection, difference를 사용한다.
- 전체관계를 조작하는데 사용되는 연산들의 집합
3. SQL
드디어 SQL입니다.
저희가 이론적이고 데이터베이스에서 다룬 '릴레이션'들은 용어가 '테이블'이라는 용어로 변경되고 말그대로 코딩화 되는 것입니다!
SQL이란?
표준 관계형 데이터 베이스이다.DBMS의 지장에선 '관계형 데이터베이스'가 석권하고 있죠!
왜(why) 일까요???
언어로 가장 먼저 나오고, 더 좋은 기능들이 나온다해도 편하고 익숙하기 때문에 못 벗어나고 남아있기 때문입니다!But!
그러나 빅데이터의 등장으로 시장이 크게 흔들리고 있습니다.
데이터가 크고, 정량화 되어 있지 않기 때문이죠.
※ 여기서 잠깐!
관계형 데이터베이스 소프트웨어(RDBMS)는 정량화된 데이터를 요구합니다.
3-1. SQL 흐름
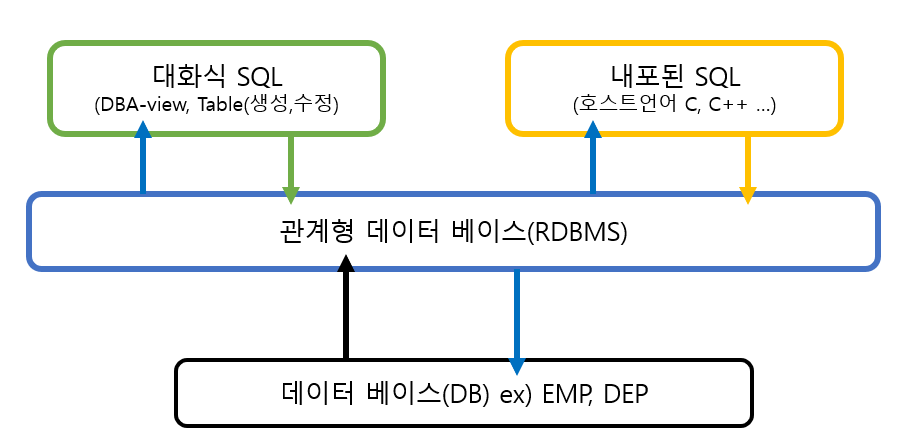
EMP나 DEP는 릴레이션 명칭이었죠!
대화식 SQL
- 주로 사용자가 DBA이며 뷰나 테이블을 다루게 됩니다.
- 학교 감사시스템이 있다면, 이것을 과연 소프트웨어 담당자가 다 하게될까요?
------------------아닙니다!
학교측에 SQL과 사용법을 구두로 알려주어 자체적으로 수행시키는 방식이죠.
이것이 대화식 SQL입니다.
내포된 SQL
1. SQL은 순차구조적인 문장을 가지고 있기 때문에 프로그램을 만들지 못합니다.
2. 프로그램을 만들려면 3요소인 선택, 반복, 조건이 있어야하죠.
3. 그러나, 내포된 SQL은
(1) 호스트언어 지원
(2) GUI를 구현할 수 있다.
그덕분에 프로그램을 만들 수 있게 됩니다.
3-2. 오라클 SQL 5가지
- 데이터 검색
- 트랜젝션 제어
3. 데이터 정의어(DDL)
: 뷰나 테이블을 나타내며,
뷰는 사용자에게 편의성을 제공하고, 보안의 효율성이 우수하다는 장점이 있죠!4. 데이터 조작어(DML)
: 데이터의 생성, 삭제, 수정, 검색 등을 조작합니다.
주로 '검색'을 자주 사용하고 나머지는 현실과의 맞춤으로 인해 사용합니다. 유지보수이죠?!5. 데이터 제어어(DCL)
: 개체 무결성제약조건으로 데이터가 불일치 되는 현상을 방지하는 제어 역할입니다.
3-3. 데이터 정의어(DDL) 종류
CREATE/DROP - DOMAIN : 도메인 생성 및 삭제
- TABLE : 테이블 생성 및 삭제
- VIEW : 뷰 생성 및 삭제
- INDEX : 인덱스 생성 및 삭제
ALTER TABLE - 테이블의 구조 변경 및 칼럼 추가, 제거3-4. 무결성 제약조건
테이블 생성 시에 제약조건을 사용해서 입력하는 자료에 대해서 제약, 즉 규칙을 정해줄 수 있죠!
이때, 정해진 제약에 따라서 데이터가 입력이 됩니다.
만약 제약에 배반된다면 자료 입력이 거부되면서 오류가 납니다.
- 무결성 : 데이터 및 네트워크 보안에 있어서 정보가 인가된 사람에 의해서만 접근이나 변경이 가능한 성질
- 데이터 무결성 : 데이터를 인가하지 않은 방법으로 변경할 수 없도록 보호하는 성질
간단하게 정리하면?
권한이 부여된 계정이나 사람만이 접근이 가능하고, 정확하고 완전한 데이터가 저장되어있는 상태!
이러한 무결성을 보장함으로 데이터 불일치 및 중복 저장 등을 해결해 주는 것이죠!
(1) 데이터 베이스 제약 조건
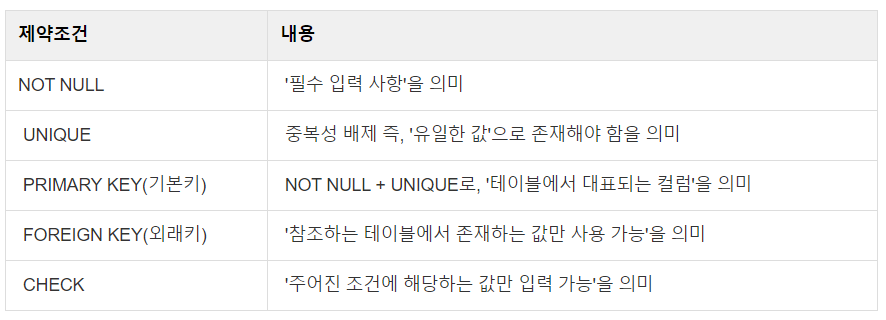
(2) FOREIGN KEY 옵션
ON DELETE NO ACTION // 오류 발생시 롤백
ON DELETE CASCADE // 부모 테이블 업데이트시, 참조 테이블도 업데이트 혹은 삭제
ON DELETE SET NULL // 부모 테이블에서 행을 업데이트, 삭제 시 외래키 구성 모든 값은 NULL로 설정
ON DELETE SET DEFAULT // 부모 테이블에서 업데이트할 시, 모든 값이 기본값 설정
RESTRICT // 자식 테이블에 데이터가 남아있는 경우 부모 테이블에 삭제 및 업데이트 불가 이 모든 것은 링크로 남기겠습니다. 꽤 잘 정리되었으므로 필요하신 분들은 참고하세요!
링크 : https://brownbears.tistory.com/182
3-5. 기본적인 SQL 형태
[ ] : 생략 가능
SELECT [DISTINCT] 칼럼(들) (1) - 필수 명시
FROM 테이블(들) (2) - 필수 명시
[WHERE 조건 (3)
중첩 질의] ]
[GROUP BY 칼럼(들) ] (4)
[HAVING 조건 ] (5)
[ORDER BY 칼럼(들)[ASC|DESC]]; (6)
SELECT문(1/10)
- '*' : ''제외, 모든 칼럼에 대해서 검색
- DISTINCT : 중복 제거
FROM문(2/10)
- 별칭 : ex) FROM EMP As E
EMP 테이블을 현재 SQL문에서만 E로 별명을 새기는 기능
WHERE문(3/10)
-
LIKE
EMPNAME LIKE '이%' or '이투_이' '이%' : 글자숫자를 정해주지 않음 '_' : 글자숫자를 명시 -
AND
EMPNAME='이투데이' AND DNO=1 사원명이 이투데이이며, 부서번호가 1인 조건 -
BETWEEN AND
SALARY BETWEEN 300,000 AND 400,000 -
IN
DNO IN (1,3) 부서번호에 1, 3이 속하는 조건 -
IS NULL
DNO IS NULL 널 값을 새기는 올바른 표현
GROUP BY절(4/10)
- 그룹화를 사용가능하다.
- 칼럼에 대해서 한 공통된 투플끼리 각 각 그룹을 형성한다.
HAVING절(5/10)
- 집단함수를 사용한다.
- COUNT, SUM, AVG, MAX, MIN 등
ORDER BY절(6/10)
- 정렬을 시킬 수 있다.
- 한 칼럼에 대해서 테이블의 전체 검색 결과에 대해 정렬시킬 수 가 있다.
- ASC(오름차순), DESC(내림차순)
조인(JOIN)(7/10)
- 두 개이상의 테이블에 대해 연관된 투플끼리 조인(통합)한다.
- 정규화가 가능한 이유는 조인이 가능해서이다!
<형태>
SELECT ...
FROM R, S
WHERE R.A <비교연산자(주로'=') > S.B;INSERT문(8/10)
- 한 테이블에 대해 수 없이 투플을 삽입시킬 수 있다!
<형태>
INSERT
INTO 테이블(칼럼1, 칼럼2, ... , 칼럼n)
SELECT ... FROM ... WHERE ...;DELETE문(9/10)
- 한 테이블로 부터 투플들을 삭제시킬 수 있다.
- 참조되는 테이블에 대해 DELETE문을 수행하고 참조무결성 제약조건에 위배 될 수 있지만, 참조하는 테이블에는 위배 되지 않는다.
<형태>
DELETE
FROM 테이블
WHERE 조건;UPDATE문(10/10)
- 한 테이블에 대한 투플의 칼럼에 대해 값을 수정시킬 수 있다.
- 기본키나 외래키에 속한 칼럼에 대해서 수행할 시 참조 무결성 제약조건에 위배될 수 있다.
<형태>
UPDATE 테이블
SET 칼럼 = 값 또는 식[, ...]
WHERE 조건;4. 마무리
휴.. 긴 글이 드디어 끝이났군요!
간단하게 데이터베이스에 대한 이론들을 정리해본거랍니다!
정말 간략하게 배경지식을 익히고 싶은 분들은 읽으시면 도움이 되실거라 생각합니다!
더 자세하게 배우시려면 필요한 용어에 대해 구글링 하시는 것도 잊지 마시고!
저는 이만 잘 놀다 갑니다ㅎㅎ!

기억보단 기록하자! LEE'Today로!

설명 감사합니다!