
1. Spring Batch DB Schema 개요
Spring Batch는 배치 작업의 메타데이터를 관리하기 위해 전용 데이터베이스 스키마를 사용합니다. 이 스키마는 Job과 Step의 실행 상태, 실행 이력, 파라미터 등을 체계적으로 저장하여 배치 작업의 모니터링, 재시작, 실패 처리 등을 지원합니다.
주요 특징
- 메타데이터 중심: 실제 비즈니스 데이터가 아닌 배치 실행 정보만 저장
- 트랜잭션 지원: 배치 작업과 동일한 트랜잭션 내에서 메타데이터 관리
- 다양한 DB 지원: MySQL, PostgreSQL, Oracle, H2 등 주요 데이터베이스 지원
- 버전 호환성: Spring Batch 버전별로 스키마 구조가 진화
스키마의 역할
- 작업 추적: Job과 Step의 실행 상태 모니터링
- 재시작 지원: 실패한 지점부터 배치 작업 재개
- 중복 실행 방지: 동일한 파라미터로 실행된 Job의 중복 방지
- 실행 통계: 처리된 아이템 수, 실행 시간 등 통계 정보 제공
2. DB Schema 생성 방식
Spring Batch의 DB Schema는 여러 가지 방법으로 생성할 수 있으며, 각각의 장단점이 있습니다.
2-1. 자동 스키마 생성 (Spring Boot 기본)
Spring Boot 환경에서는 기본적으로 자동 스키마 생성이 활성화되어 있습니다.
# application.yml
spring:
batch:
jdbc:
initialize-schema: always
# 기본값: embedded DB는 always, 외부 DB는 never설정 옵션
always: 항상 스키마 생성 (기존 테이블이 있어도 재생성)embedded: 임베디드 DB(H2, HSQL 등)에서만 생성never: 스키마 생성하지 않음 (수동으로 생성해야 함)
2-2. 수동 스키마 생성
프로덕션 환경에서는 보통 수동 스키마 생성을 권장합니다.
spring:
batch:
jdbc:
initialize-schema: neverSQL 스크립트 위치
Spring Batch는 각 데이터베이스별 DDL 스크립트를 제공합니다.
지원 데이터베이스
schema-mysql.sqlschema-postgresql.sqlschema-oracle.sqlschema-h2.sqlschema-sqlserver.sql
2-3. 커스텀 스키마 생성
특별한 요구사항이 있는 경우 커스텀 스키마를 생성할 수 있습니다.
@Configuration
public class BatchSchemaConfig {
@Bean
public DataSourceInitializer dataSourceInitializer(DataSource dataSource) {
DataSourceInitializer initializer = new DataSourceInitializer();
initializer.setDataSource(dataSource);
ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
populator.addScript(new ClassPathResource("custom-batch-schema.sql"));
initializer.setDatabasePopulator(populator);
return initializer;
}
}3. Job 관련 테이블
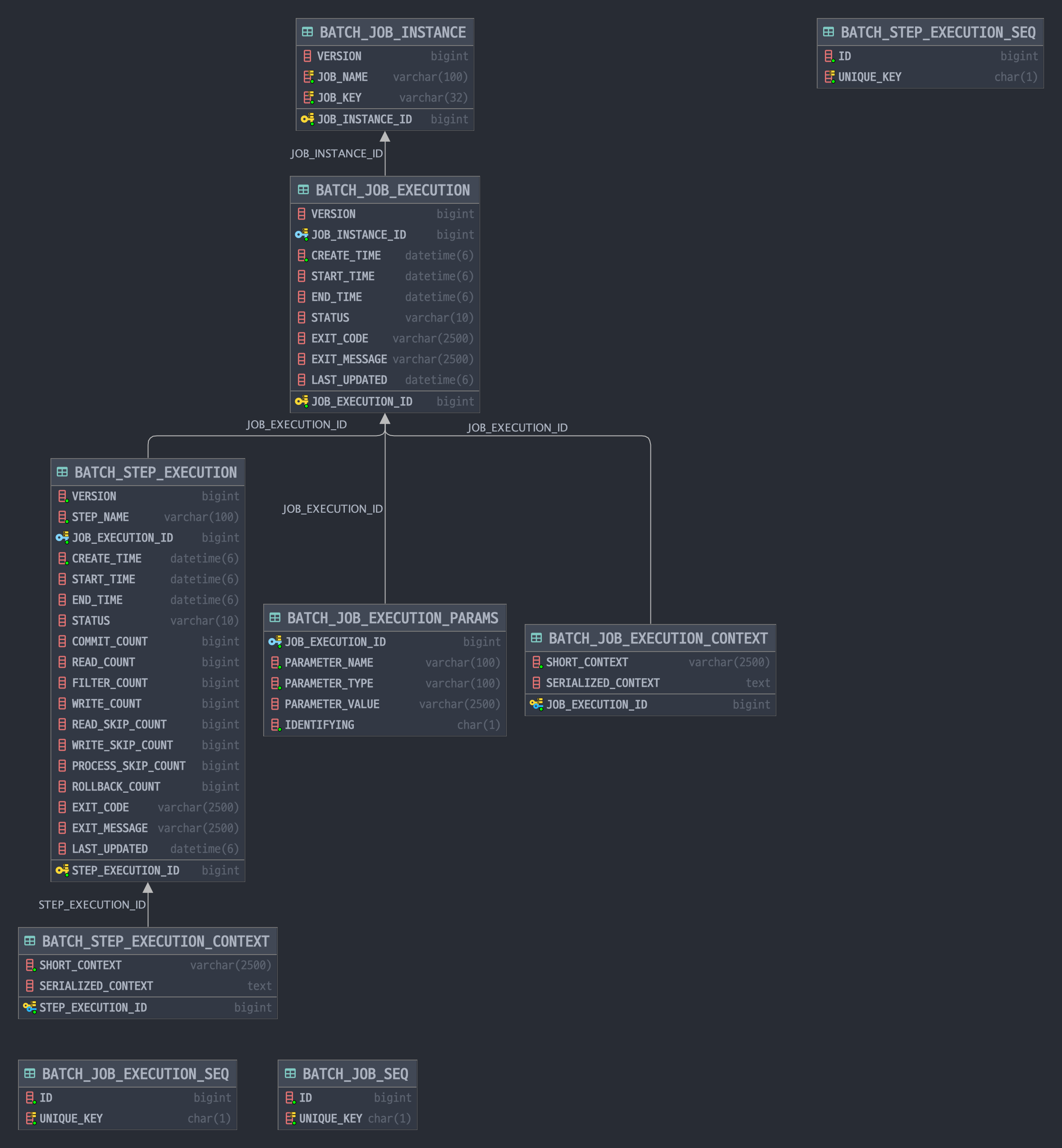
Spring Batch의 Job 관련 테이블은 Job의 실행 단위와 Job의 실행 인스턴스를 관리합니다.
3-1. BATCH_JOB_INSTANCE
Job의 논리적 실행 단위를 나타내는 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| JOB_INSTANCE_ID | BIGINT | Job Instance의 고유 ID (PK) |
| VERSION | BIGINT | 낙관적 락을 위한 버전 |
| JOB_NAME | VARCHAR(100) | Job의 이름 |
| JOB_KEY | VARCHAR(32) | Job 파라미터의 해시값 |
주요 특징
- 유니크 제약:
JOB_NAME + JOB_KEY조합이 유니크 - 파라미터 기반: 동일한 Job이라도 파라미터가 다르면 별도 인스턴스 생성
- 재실행 방지: 성공한 Job Instance는 재실행 불가
-- 예시 데이터
INSERT INTO BATCH_JOB_INSTANCE VALUES
(1, 0, 'dailyReportJob', 'd41d8cd98f00b204e9800998ecf8427e');3-2. BATCH_JOB_EXECUTION
Job Instance의 실제 실행 기록을 저장하는 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| JOB_EXECUTION_ID | BIGINT | Job Execution의 고유 ID (PK) |
| VERSION | BIGINT | 낙관적 락을 위한 버전 |
| JOB_INSTANCE_ID | BIGINT | Job Instance ID (FK) |
| CREATE_TIME | DATETIME | 실행 생성 시간 |
| START_TIME | DATETIME | 실행 시작 시간 |
| END_TIME | DATETIME | 실행 종료 시간 |
| STATUS | VARCHAR(10) | 실행 상태 |
| EXIT_CODE | VARCHAR(2500) | 종료 코드 |
| EXIT_MESSAGE | VARCHAR(2500) | 종료 메시지 |
| LAST_UPDATED | DATETIME | 마지막 업데이트 시간 |
실행 상태 (STATUS)
STARTING: 실행 시작 중STARTED: 실행 중STOPPING: 중지 중STOPPED: 중지됨FAILED: 실패COMPLETED: 완료ABANDONED: 포기됨
-- 예시 데이터
INSERT INTO BATCH_JOB_EXECUTION VALUES
(1, 2, 1, '2025-01-01 09:00:00', '2025-01-01 09:00:01',
'2025-01-01 09:05:30', 'COMPLETED', 'COMPLETED', '', '2025-01-01 09:05:30');3-3. BATCH_JOB_EXECUTION_PARAMS
Job 실행 시 사용된 파라미터 정보를 저장하는 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| JOB_EXECUTION_ID | BIGINT | Job Execution ID (FK) |
| PARAMETER_NAME | VARCHAR(100) | 파라미터 이름 |
| PARAMETER_TYPE | VARCHAR(100) | 파라미터 타입 |
| PARAMETER_VALUE | VARCHAR(2500) | 파라미터 값 |
| IDENTIFYING | CHAR(1) | 식별 파라미터 여부 |
-- 예시 데이터
INSERT INTO BATCH_JOB_EXECUTION_PARAMS VALUES
(1, 'date', 'STRING', '2025-01-01', 'Y'),
(1, 'version', 'LONG', '1', 'N');3-4. BATCH_JOB_EXECUTION_CONTEXT
Job 실행 중 공유되는 데이터를 저장하는 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| JOB_EXECUTION_ID | BIGINT | Job Execution ID (PK, FK) |
| SHORT_CONTEXT | VARCHAR(2500) | 짧은 컨텍스트 데이터 |
| SERIALIZED_CONTEXT | TEXT | 직렬화된 컨텍스트 데이터 |
사용 용도
- Step 간 데이터 공유
- 재시작 시 상태 복원
- 커스텀 메타데이터 저장
// ExecutionContext 사용 예시
@Bean
public Step step1(JobRepository jobRepository) {
return new StepBuilder("step1", jobRepository)
.tasklet((contribution, chunkContext) -> {
ExecutionContext jobContext = chunkContext.getStepContext()
.getStepExecution().getJobExecution().getExecutionContext();
jobContext.put("processedCount", 1000);
return RepeatStatus.FINISHED;
})
.build();
}4. Step 관련 테이블
Step 관련 테이블은 각 Step의 실행 상태와 처리 통계를 관리합니다.
4-1. BATCH_STEP_EXECUTION
Step의 실행 기록을 저장하는 핵심 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| STEP_EXECUTION_ID | BIGINT | Step Execution의 고유 ID (PK) |
| VERSION | BIGINT | 낙관적 락을 위한 버전 |
| STEP_NAME | VARCHAR(100) | Step 이름 |
| JOB_EXECUTION_ID | BIGINT | Job Execution ID (FK) |
| CREATE_TIME | DATETIME | 실행 생성 시간 |
| START_TIME | DATETIME | 실행 시작 시간 |
| END_TIME | DATETIME | 실행 종료 시간 |
| STATUS | VARCHAR(10) | 실행 상태 |
| COMMIT_COUNT | BIGINT | 커밋 횟수 |
| READ_COUNT | BIGINT | 읽은 아이템 수 |
| FILTER_COUNT | BIGINT | 필터된 아이템 수 |
| WRITE_COUNT | BIGINT | 쓴 아이템 수 |
| READ_SKIP_COUNT | BIGINT | 읽기 스킵 수 |
| WRITE_SKIP_COUNT | BIGINT | 쓰기 스킵 수 |
| PROCESS_SKIP_COUNT | BIGINT | 처리 스킵 수 |
| ROLLBACK_COUNT | BIGINT | 롤백 횟수 |
| EXIT_CODE | VARCHAR(2500) | 종료 코드 |
| EXIT_MESSAGE | VARCHAR(2500) | 종료 메시지 |
| LAST_UPDATED | DATETIME | 마지막 업데이트 시간 |
처리 통계의 의미
- READ_COUNT: ItemReader가 읽은 총 아이템 수
- WRITE_COUNT: ItemWriter가 쓴 총 아이템 수
- FILTER_COUNT: ItemProcessor에서 null을 반환한 아이템 수
- SKIP_COUNT: 예외 발생으로 스킵된 아이템 수
- COMMIT_COUNT: 트랜잭션 커밋 횟수
-- 예시 데이터
INSERT INTO BATCH_STEP_EXECUTION VALUES
(1, 1, 'processDataStep', 1, '2025-01-01 09:00:01', '2025-01-01 09:00:02',
'2025-01-01 09:03:45', 'COMPLETED', 100, 10000, 50, 9950, 0, 0, 0, 0,
'COMPLETED', '', '2025-01-01 09:03:45');4-2. BATCH_STEP_EXECUTION_CONTEXT
Step 실행 중 로컬 데이터를 저장하는 테이블입니다.
| 컬럼명 | 타입 | 설명 |
|---|---|---|
| STEP_EXECUTION_ID | BIGINT | Step Execution ID (PK, FK) |
| SHORT_CONTEXT | VARCHAR(2500) | 짧은 컨텍스트 데이터 |
| SERIALIZED_CONTEXT | TEXT | 직렬화된 컨텍스트 데이터 |
주요 용도
- 재시작 지원: 실패 지점부터 재시작하기 위한 상태 정보
- 청크 단위 처리: 현재 처리 중인 청크 정보
- 커스텀 상태: 개발자가 정의한 Step별 상태 정보
// StepExecutionContext 사용 예시
public class CustomItemReader implements ItemReader<String> {
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
ExecutionContext context = stepExecution.getExecutionContext();
// 이전 실행에서 중단된 지점 복원
this.currentIndex = context.getInt("current.index", 0);
}
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution) {
ExecutionContext context = stepExecution.getExecutionContext();
// 현재 진행 상황 저장
context.putInt("current.index", this.currentIndex);
return ExitStatus.COMPLETED;
}
}다이어그램

왜? 라는 질문이 사라질 때까지