📌 서론
어차피 모든 문법을 기억하고 사용할 수는 없다.
그러니, 이 포스팅에서 공식 문서에 잘 작성되어 있는 설명을 그저 한국어로 다시 옮겨 적을 필요는 없을 것이다. PostgreSQL에서 제공하는 데이터 타입의 종류를 톺아보고, 다른 DBMS와 구별되는 특징들은 눈 여겨보는 정도면 족하다 !
프로젝트를 진행하면서 필요한 정보에 대한 자세한 내용은 아래 링크를 참고하자.
📌 숫자 타입
smallint (2byte): 작은 범위의 정수int (4byte): 일반적으로 사용하는 정수bigint (8byte): 큰 범위의 정수
decimal (variable): 사용자 지정 정밀도, 정확nemeric (variable): 사용자 지정 정밀도, 정확
real (4byte): 가변 정밀도, 부정확double precision (8byte): 가변 정밀도, 부정확
smallserial (2byte): 작은 자동 증가 정수serial (4byte): 자동 증가 정수bigserial (8byte): 큰 자동 증가 정수
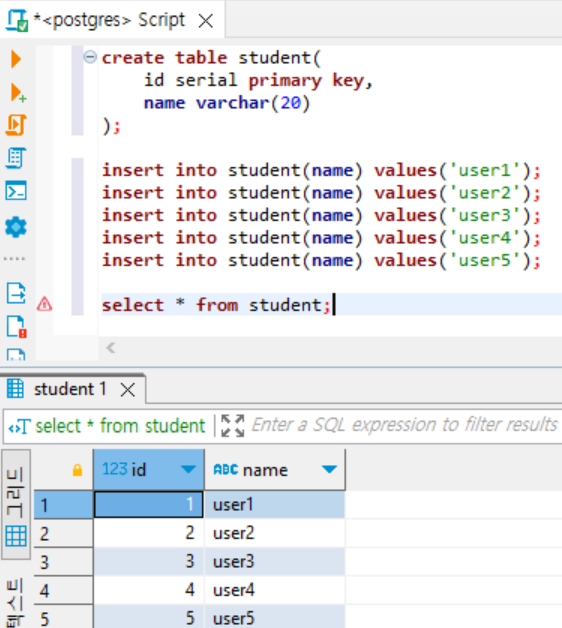
이 중에도 serial 은 처음 알게 된 자료형인데, pk에 사용하면 좋을 것 같다!
다음과 같이 student 테이블에 id 값을 직접 넣지 않더라도 자동으로 증가되는 것을 확인할 수 있다.
📌 화폐 타입
money (8byte): 통화 금액
📌 문자 타입
varchar(n): 제한이 있는 가변 길이 문자열char(n): 고정 길이 문자열 (공백 padding)text: 제한이 없는 가변 길이 문자열
varchar(n)와 char(n)은 모두 문자열의 길이가 최대 n인 문자열을 저장할 수 있으며,
n보다 길이가 긴 문자열을 저장하려고 시도하면 초과된 문자가 모두 공백이 아닌 한 오류가 발생하고, 문자열은 최대 길이 n으로 잘린다.
char(n) 은 n보다 문자열의 길이가 짧다면 부족한만큼 공백으로 채운다.
💡 TIP
몇몇 다른 DBMS에서는, char(n)이 성능상 이점을 가지고 있지만,
varchar(n), char(n), text 이 세가지 유형은 성능 차이가 없다.
실제로, PostgreSQL에서 char(n)은 추가적인 작업* 때문에 3가지 타입 중 가장 느리다.
따라서 대부분의 상황에서 varchar(n) 혹은 text를 사용하는 것이 더욱 효과적이다.
[참고 링크]
📌 바이너리 데이터 타입
bytea: 가변 길이 이진 문자열
📌 Date / Time 타입
어차피 모든 문법을 기억하고 사용할 수는 없다.
그러니, 이 포스팅에서 공식 문서에 잘 작성되어 있는 설명을 그저 한국어로 바꿔서 다시 적을 필요는 없을 것이다.
PostgreSQL에서 제공하는 데이터 타입의 종류를 톺아보고, 다른 DBMS와 구별되는 특징들은 눈 여겨보는 정도면 족하다 !
프로젝트를 진행하면서 필요한 정보에 대한 자세한 내용은 아래 링크를 참고하자.
[ 참고 링크 ]
timestamp[ (p) ] (8byte): 날짜와 시간timestamp[ (p) ] with time zone (8byte): 날짜와 시간 (시간대 포함)
date (4byte): 날짜
time[ (p) ] (8byte): 시간time[ (p) ] with time zone (12byte): 시간 (시간대 포함)
interval [ fields ] [ (p) ] (16byte): 날짜 / 시간값에 다른 날짜 / 시간을 더하거나 빼서 범위를 체크하는 기능을 제공하는 타입
📍 p (정밀도 값) : 필드에 유지되는 소수의 자릿 수를 지정하는 옵션
📌 Boolean 타입
boolean (1byte): true / false
boolean 은 ...
true 상태에 대해 다음 문자열 표현을 허용한다.
→ true / yes / on / 1
false 상태에 대해 다음 문자열 표현을 허용한다.
→ false / no / off / 0
이러한 문자열의 고유한 접두사 (ex: t / f / n / y)도 허용된다.
선행 또는 후행 공백은 무시되며, 대소문자는 중요하지 않다.
📌 열거(Enumerated) 타입
✅ 열거(Enumerated) 타입 선언
열거 타입은 CREATE TYPE 명령어를 통해 생성 된다.
CREATE TYPE mood AS ENUM('sad', 'ok', 'happy');✅ 열거(Enumerated) 타입의 사용
열거 타입은 일단 생성되면, 다른 타입과 마찬가지로 테이블 및 함수 정의에서 사용할 수 있다.
CREATE TABLE person (
name text,
current_mood mood
);
INSERT INTO person VALUES ('Moe', 'happy');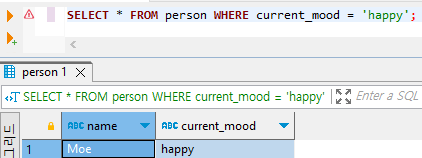
✅ 열거(Enumerated) 타입 값의 순서
열거 타입의 값 순서는 열거 타입을 생성할 때, 값이 나열된 순서이다.
즉, 다음과 같이 mood가 선언된 경우 첫번째 값은 sad, 두번째 값은 ok, 세번째 값은 happy이다.
CREATE TYPE mood AS ENUM('sad', 'ok', 'happy');즉, 모든 비교 연산자와 집계 함수에서 열거 타입을 사용할 수 있다.
// 예시를 위한 더미 데이터 삽입
INSERT INTO person VALUES ('Larry', 'sad');
INSERT INTO person VALUES ('Curly', 'ok');
// 비교 연산에서 열거 타입을 사용할 수 있다.
// sad는 첫번째 값이므로, mood가 ok(두번째 값), happy(세번째 값)인 person을 조회한다.
SELECT * FROM person WHERE current_mood > 'sad';
// 집계 함수 ORDER BY에서 열거 타입을 사용할 수 있다.
SELECT * FROM person WHERE current_mood > 'sad' ORDER BY current_mood;
// MIN(current_mode)는 sad이다.
SELECT name
FROM person
WHERE current_mood = (SELECT MIN(current_mood) FROM person);✅ 타입 안정성 제공
각각의 열거 타입은 별개이며 다른 열거 타입과 비교할 수 없다.
// 열거 타입 happiness 생성
CREATE TYPE happiness AS ENUM ('happy', 'very happy', 'ecstatic');
// 열거 타입 happiness를 사용하여 holidays 테이블 생성
CREATE TABLE holidays (
num_weeks integer,
happiness happiness
);
INSERT INTO holidays(num_weeks,happiness) VALUES (4, 'happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (6, 'very happy');
INSERT INTO holidays(num_weeks,happiness) VALUES (8, 'ecstatic');
// 에러 발생 !! -> happiness 열거 타입에 'sad' 값은 존재하지 않으므로
INSERT INTO holidays(num_weeks,happiness) VALUES (2, 'sad');
// 에러 발생 !! -> where 조건절에서 mood 열거 타입과 happiness 열거 타입을 비교할 수 없으므로
SELECT person.name, holidays.num_weeks FROM person, holidays
WHERE person.current_mood = holidays.happiness;
