서론
- MySQL 환경세팅/서버접속 에러 해결하기..
- 정처기 필기 기출 5개년 돌리기
- 스프링 프레임워크 - 다형성 이용하기, 디자인 패턴 이용하기
- 패스트캠퍼스 강의 - API 설계
주간 목표는 이정도였다.
개발 기본기 쌓기 중요!
자료구조, 알고리즘, 컴퓨터구조, 운영체제, 네트워크, 데이터베이스 등...
마침 1월에 접수가 있는 정보처리기사 필기를 준비하면서 자료구조 내용을 가져와보았다.
자료 구조
자료 구조의 정의
효율적인 프로그램을 작성할 때 가장 우선적인 고려사항은 저장 공간의 효율성과 실행시간의 신속성이다. 자료 구조는 프로그램에서 사용하기 위한 자료를 기억장치의 공간 내에 저장하는 방법과 저장된 그룹 내에 존재하 는 자료 간의 관계, 처리 방법 등을 연구 분석하는 것을 말한다.
- 자료 구조는 자료의 표현과 그것과 관련된 연산이다.
- 자료 구조는 일련의 자료들을 조직하고 구조화하는 것이다.
- 어떠한 자료 구조에서도 필요한 모든 연산들을 처리할 수 있다.
- 자료 구조에 따라 프로그램 실행시간이 달라진다.
자료 구조의 분류
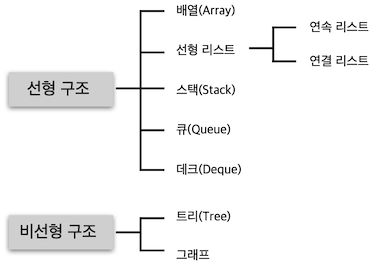
배열(Array)
배열은 동일한 자료형의 데이터들이 같은 크기로 나열되어 순서를 갖고 있는 집합이다.
- 배열은 정적인 자료 구조로 기억장소의 추가가 어렵고, 데이터 삭제 시 데이터가 저장되어 있던 기억장소는 빈 공간으로 남아있어 메모리의 낭비가 발생한다.
- 배열은 첨자를 이용하여 데이터에 접근한다.
- 배열은 데이터마다 동일한 이름의 변수를 사용하여 처리가 간편하다.
- 배열은 사용한 첨자의 개수에 따라 n차원 배열이라고 부른다.
선형 리스트(Linear List)
선형 리스트는 일정한 순서에 의해 나열된 자료 구조이다.
-
선형 리스트는 배열을 이용하는 연속 리스트와 포인터를 이용하는 연결 리스트로 구분된다.
-
연속 리스트(Contiguous List)
연속 리스트는 배열과 같이 연속되는 기억장소에 저장되는 자료 구조이다.연속 리스트는 기억장소를 연속적으로 배정받기 때문에 기억장소 이용 효율은 밀도가 1로서 가장 좋다. (기억장소를 빈 공간없이 꽉 차게 사용한다는 의미)
연속 리스트는 중간에 데이터를 삽입하기 위해서는 연속된 빈 공간이 있어야 하며, 삽입 및 삭제 시 자료의 이동이 필요하다.
-
연결 리스트(Linked List)
연결 리스트는 자료들을 반드시 연속적으로 배열시키지는 않고 임의의 기억공간에 기억시키되, 자료 항목의 순서에 따라 노드의 포인터 부분을 이용하여 서로 연결시킨 자료 구조이다.연결 리스트는 노드의 삽입 및 삭제 작업이 용이하다.
기억 공간이 연속적으로 놓여 있지 않아도 저장할 수 있다.
연결 리스트는 연결을 위한 링크(포인터) 부분이 필요하기 때문에 순차 리스트에 비해 기억 공간의 이용 효율이 좋지 않다.
연결 리스트는 연결을 위한 포인터를 찾는 시간이 필요하기 때문에 접근 속도가 느리다.
연결 리스트는 중간 노드 연결이 끊어지면 그 다음 노드를 찾기 힘들다.
스택(Stack)
스택은 리스트의 한쪽 끝으로만 자료의 삽입, 삭제 작업이 이루어지는 자료 구조이다.
-
스택은 가장 나중에 삽입된 자료가 가장 먼저 삭제되는 후입선출(LIFO) 방식으로 자료를 처리한다.
-
스택의 용도
재귀 호출, 후위 표기법, 서브루틴 호출, 인터럽트 처리, 깊이 우선 탐색 등과 같이 왔던 길을 되돌아 가는 경우에 사용된다. -
스택의 모든 기억 공간이 꽉 채워져 있는 상태에서 데이터가 삽입되면 오버플로가 발생하며, 더 이상 삭제할 데이터가 없는 상태에서 데이터를 삭제하면 언더플로가 발생한다.
-
TOP : 스택으로 할당된 기억 공간에 가장 마지막으로 삽입된 자료가 기억된 위치를 가리키는 요소
-
BOTTOM : 스택의 가장 밑바닥
ex) 스택의 삽입(Push) 알고리즘
If Top >= M THEN Overflow
// 스택 포인터가 스택의 크기보다 크면 더이상 자료 삽입 불가로 Overflow 처리
Else // 그렇지 않으면
Top = Top+1 // 스택 포인터 1 증가
X(Top) <- Item // Item이 가지고 있는 값을 스택의 Top 위치에 삽입ex) 자료의 삭제(Pop Up) 알고리즘
If Top = 0 Then
Underflow
Else
Item <- X(Top)
Top = Top-1스택에 기억되어 있는 자료를 삭제시킬 때는 제일 먼저 삭제할 자료가 있는지 없는지부터 확인해야 한다.
큐(Queue)
큐는 리스트의 한쪽에서는 삽입 작업이 이루어지고 다른 한쪽에서는 삭제 작업이 이루어지도록 구성한 자료 구조이다.
- 큐는 가장 먼저 삽입된 자료가 가장 먼저 삭제되는 선입선출(FIFO) 방식으로 처리한다.
- 큐는 시작과 끝을 표시하는 두 개의 포인터가 있다.
- 프런트 포인터 : 가장 먼저 삽입된 자료의 기억 공간을 가리키는 포인터로, 삭제 작업을 할 때 사용한다.
- 리어 포인터 : 가장 마지막에 삽입된 자료가 위치한 기억 공간을 가리키는 포인터로, 삽입 작업을 할 때 사용한다.
- 큐는 운영체제의 작업 스케줄링에 사용한다.
트리(Tree)
트리는 정점(노드)과 선분(가지)을 이용하여 사이클을 이루지 않도록 구성한 그래프의 특수한 형태이다.
- 하나의 기억 공간을 노드라고 하며, 노드와 노드를 연결하는 선을 링크라고 한다.
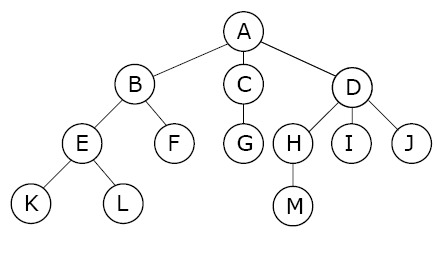
트리 관련 용어
-
노드(Node) : 트리의 기본 요소로서 자료 항목과 다른 항목에 대한 가지를 합친 것
-
근 노드 : 트리의 맨 위에 있는 노드
-
디그리(Degree, 차수) : 각 노드에서 뻗어 나온 가지의 수
ex) A=3 -
단말 노드(잎 노드) : 자식이 하나도 없는 노드. 즉, 디그리가 0인 노드
-
자식 노드 : 어떤 노드에 연결된 다음 레벨의 노드들
-
부모 노드 : 어떤 노드에 연결된 이전 레벨의 노드들
-
형제 노드 : 동일한 부모를 갖는 노드들
트리의 운행법
- Preorder 운행 : Root - Left - Right
- Inorder 운행 : Left - Root - Right
- Postorder 운행 : Left - Right - Root
- 트리의 운행법에 따라 수식의 표기법도 달라짐.
- 진위 표기법(Prefix)
- 중위 표기법(Infix)
- 후위 표기법(Postfix)
진위, 후위 표기법 같은 경우 스택을 이용해 처리하므로 중위 표기법의 경우 진위나 후위로 바꿔 처리해준다.
ex) X=A/B*(C+D)+E1.Prefix로 변환하기
- 1-1 연산 우선순위에 따라 괄호로 묶는다.
(X=((A/B)*(C+D))+E))- 1-2 연산자를 해당 괄호의 앞으로 옮긴다.
=(X+(*(/(AB)+(CD))E))- 1-3 필요없는 괄호 제거
=X+*/AB+CDE2.Postfix로 변환하기
- 2-1 연산 우선순위에 따라 괄호로 묶는다.
(X=((A/B)*(C+D))+E))- 2-2 연산자를 해당 괄호의 뒤로 옮긴다.
(X((AB)/(CD)+)*E)+)=- 2-3 필요없는 괄호 제거
XAB/CD+*E+=