자바 동시성 예약어에 대한 검색을 해보면 synchronized, volatile이라는 예약어와 volatile의 사용 시 문제점에 대한 해결책으로 사용할 수 있는 Atomic class를 설명해 주는 글들이 자주 보였다.
글들을 읽다 보니 어떻게 동작되는지 궁금해서 실험을 해보게 되었다.
synchronized
멀티 쓰레드 환경에서 동시 접근에 대한 안전성을 보장하기 위한 키워드. 객체나 메서드에 붙여 사용할 수 있다.
사용 방법
인스턴스 메서드에 적용
public class Counter {
private int count;
// 인스턴스 메서드에 적용
public synchronized void methodSynchronizedIncrement() {
try {
Thread.sleep(150);
count++;
getCountAndThreadName();
Thread.sleep(150);
} catch(InterruptedException e) {
throw new RuntimeException(e);
}
}
private void getCountAndThreadName() {
System.out.println("count : " + count + " (" + Thread.currentThread().getName() + ")");
}
}synchronized는 methodSynchronizedIncrement() 메서드에 적용되어 해당 메서드를 호출하는 쓰레드는 다른 쓰레드들이 완료될 때까지 기다리게 된다. 여기서는 count++ 앞뒤에 150ms 텀을 두어서 구현하였다.
메서드에 적용이 가능은 하지만 이렇게 사용한다면 해당 메서드의 로직 수행 시간 동안 락이 걸리게 되므로, 성능 저하 문제를 겪게 될 수도 있다.
코드 블록에 적용
public class Counter {
private int count;
// 코드 블록에 적용
public void codeblockSynchronizedIncrement() {
try {
Thread.sleep(150);
synchronized(this) {
count++;
getCountAndThreadName();
}
Thread.sleep(150);
} catch(InterruptedException e) {
throw new RuntimeException(e);
}
}
private void getCountAndThreadName() {
System.out.println("count : " + count + " (" + Thread.currentThread().getName() + ")");
}
}synchronized는 codeblockSynchronizedIncrement() 메서드 내부의 특정 코드 블록에 적용되어 해당 블록을 실행하는 쓰레드는 다른 쓰레드들이 완료될 때까지 기다리게 된다. 인스턴스 메서드 적용 항목과 마찬가지로 앞뒤에 150ms 텀을 두었다.
메서드에 적용할 경우 성능 저하 문제를 겪게 될 수도 있다고 하였다. 하지만 코드 블록에 적용할 경우 개선이 가능해진다. 위 소스를 보면 synchronized(this) 블록이 count++ 코드 블록을 감싸고 있다. 이 블록은 this 객체에 대한 모든 동기화를 제공하므로, 다른 인스턴스 메서드도 이 블록을 통해 동기화된다.
동작 확인
public class Sample {
public static void main(String[] args) {
Counter counter = new Counter();
long startTime = System.nanoTime();
Thread th1 = new Thread(() -> {
for(int i = 0; i < 100; i++) {
// 인스턴스 메서드에 적용
// counter.methodSynchronizedIncrement();
// 코드 블록에 적용
counter.codeblockSynchronizedIncrement();
}
});
th1.setName("Thread1");
Thread th2 = new Thread(() -> {
for(int i = 0; i < 100; i++) {
// counter.methodSynchronizedIncrement();
counter.codeblockSynchronizedIncrement();
}
});
th2.setName("Thread2");
Thread.State th1State = th1.getState();
Thread.State th2State = th2.getState();
// 첫 실행 시 State - NEW
System.out.println(th1.getName() + " state: " + th1State);
System.out.println(th2.getName() + " state: " + th2State);
th1.start();
th2.start();
// Thread1과 Thread2 모두 종료되기 전까지 출력
while (th1.getState() != Thread.State.TERMINATED || th2.getState() != Thread.State.TERMINATED) {
th1State = checkThread(th1, th1State);
th2State = checkThread(th2, th2State);
}
long endTime = System.nanoTime();
System.out.println("Execution time in nanoseconds: " + (endTime - startTime));
System.out.println("Execution time in seconds: " + (endTime - startTime)/(1000*1000*1000));
}
private static Thread.State checkThread(Thread th, Thread.State threadState) {
if (threadState != th.getState()) {
threadState = th.getState();
getThreadStateAndName(th);
}
else {
getBlockedThreadMessage(th);
}
return threadState;
}
private static void getThreadStateAndName(Thread th) {
System.out.println(th.getName() + " state: " + th.getState());
}
private static void getBlockedThreadMessage(Thread th1) {
System.out.println(th1.getName() + " is blocked");
}
}인스턴스 메서드 적용인 것과 코드 블록 적용인 것 둘 중 무엇을 실행해도 처음에 출력되는 것은 같다.
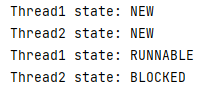
두 개의 쓰레드가 실행(NEW) 된 이후에 하나는 진행(RUNNABLE) 하고, 다른 하나는 이미 락에 걸렸기에 BLOCKED이 출력된다.
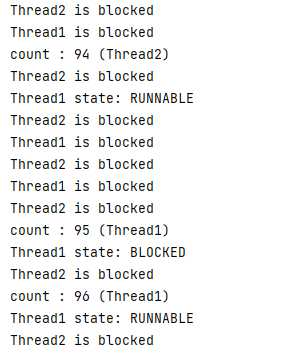
while 문이 실행되는 간격과 Thread의 진행 속도의 차이가 있기에 출력되어 보이는 것이 조금은 이상해 보인다.
자세히 본다면 count 94까지는 Thread2가 해당 synchronized를 점유하고 있었기에 while 문의 출력에서는 둘 다 blocked 되었다고 나오고 있다. 그러다가 Thread1 state: RUNNABLE이 되는 순간 그다음 count는 Thread1에서 진행되고 있는 것을 볼 수 있다.
이렇게 synchronized가 사용된다면 하나의 thread만 점유할 수 있다는 것을 확인할 수 있었다.
인스턴스 메서드와 코드 블록 성능 비교
long startTime = System.nanoTime();
...
long endTime = System.nanoTime();
System.out.println("Execution time in nanoseconds: " + (endTime - startTime));
System.out.println("Execution time in seconds: " + (endTime - startTime)/(1000*1000*1000));현재 시간의 ns를 출력해 주는 System.nanoTime()를 사용해서 비교해 보았다. 실행해 보기 전에 어떻게 진행될지 생각을 먼저 해보았는데 인스턴스 메서드의 경우에는 전체 적용이기에 300ms가 전부 적용되어 약 60초가 소요될 것이고, 코드 블록의 경우에는 count++에 앞서 150ms를 미리 진행하므로 약 30초를 기대했다.
여러 번 테스트하다 보니 100회는 길어서 10회인 결과를 나타내었다.
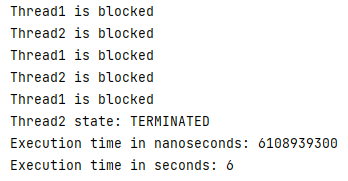
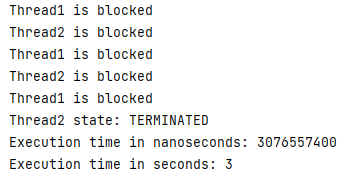
인스턴스 메서드에 적용 시 약 6.109초의 소요 시간이 있었고, 코드 블록에 적용 시에는 약 3.077초로 인스턴스 메서드의 절반인 예상에 부합하는 결과가 나왔다.
volatile
synchronized와는 다르게 변수 앞에 사용되며, CS 공부하면서 볼 수 있었던 CPU Caching과 관련이 있는 키워드다. Caching은 CPU와 Main Memory 간의 속도 차이로 인한 병목 현상을 완화하기 위한 방법이다. CPU가 Main Memory에 접근하기 전에 Cache를 앞서서 확인하는데, Cache에 원하는 데이터가 있다면 hit, 없다면 miss라고 한다.
volatile은 Java 변수를 Caching 하는 것이 아니라 바로 Main Memory에 올리겠다는 키워드다. 읽는 것뿐만 아니라 I/O 모두 Main Memory에 바로 하겠다는 것이다. 그럼으로써 쓰레드 간 공유 변수를 안전하게 읽고 쓰기가 가능해지며, 쓰레드 간의 가시성(visibility)을 보장한다.
사용 방법
public class VolatileSample {
// volatile 변수
private static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
count++;
}
}
});
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
count++;
}
}
});
thread1.start();
thread2.start();
// 두 개의 쓰레드가 모두 종료될 때까지 기다림
thread1.join();
thread2.join();
// 결과 출력
System.out.println("Count: " + count);
}
}count가 여러 스레드에서 동시에 접근할 수 있기 때문에, 스레드 간 동기화 문제를 방지하기 위해서 volatile로 선언을 하였다. 그리고 두 개의 쓰레드는 각각 count를 10000번 증가시키는 작업을 수행한다.
하지만 가시성 문제만 해결했을 뿐 동시에 연산 시에 문제가 일어나는 것(원자성 보장 못함)을 확인할 수 있다.
동작 확인
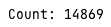
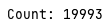
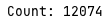
여러 번 시도를 해보았으나, 모두 다른 값의 count가 출력되었다.
매번 다른 값이 나오면 해결책은?
우선 동기화 기법을 생각할 수 있다. 앞서 보았던 synchronized 메서드 혹은 블록을 사용하는 것이다. synchronized를 사용한다면 하나의 쓰레드만 접근 가능하기에 다른 쓰레드가 값을 변경하는 것을 막을 수 있기 때문이다.
다른 방법으로는 Atomic Class(java.util.concurrent.atomic package)를 사용하는 것이다. Atomic은 다음 항목에 간략히 적어보았다.
언제 사용하면 좋을까
변수의 값을 읽는 작업과 쓰는 작업이 분리되어 있을 때
한 쓰레드에서 변수의 값을 쓰고, 다른 쓰레드에서 그 값을 읽는 경우에는 volatile을 사용하면 적절하다고 한다. 변수의 값을 쓴 후에는 반드시 Main Memory에 반영하고, 읽는 쓰레드는 항상 Main Memory에서 변수 값을 읽게 된다.
I/O 작업이 분리가 되어있다고 무조건 써야 한다는 것은 아니다. Main Memory에 바로 올리기에 CPU Cache보다 비용이 크다는 점이 문제가 될 수 있다. 그에 따른 성능을 감안해야 하기 때문이다.
Atomic Class
Atomic Class는 멀티 쓰레드 환경에서 안전하게 공유 변수에 대한 연산을 수행할 수 있도록 도와주는 클래스다. 그리고 동기화나 락을 사용하지 않고CAS(Compare-and-swap) 알고리즘을 채택했다.
CAS 알고리즘은 아래와 같은 방식으로 동작한다.
1. 쓰레드가 공유 변수의 현재의 값을 읽는다.
2. 가져온 값을 새로운 값으로 연산한다.
3. 공유 변수의 현재의 값이 이전에 읽었던(가져온) 값과 같은지 비교한다.
4. 현재의 값이 이전에 읽었던 값과 같다면 새로운 값을 쓴다. 다르다면 값을 쓰지 않고, 현재의 값을 받아와서 다시 연산 작업에 들어간다.
Java Atomic Class
AtomicInteger.class
public class AtomicInteger extends Number implements java.io.Serializable {
private static final long serialVersionUID = 6214790243416807050L;
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();
private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
private volatile int value;
...
public final boolean compareAndSet(int expectedValue, int newValue) {
return U.compareAndSetInt(this, VALUE, expectedValue, newValue);
}
...
}
public final class Unsafe {
private static native void registerNatives();
static {
registerNatives();
}
...
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset,
int expected,
int x);
...
}AtomicInteger의 값인 value를 보면 volatile이 적용되어 있다. volatile에서 부족한 원자성을 보장해 줄 만한 것은 CAS 알고리즘에 있다고 하였다. AtomicInteger에서 볼 수 있는 것 중에는 Unsafe class의 native method인 compareAndSetInt()를 호출하는 compareAndSet() 메서드가 있다.
Atomic Class를 가져다 쓰면 동시성 해결?
안타깝지만 주의해야 할 문제점이 있다고 한다.
1. 쓰레드1에서 Atomic 변수의 값을 읽은 상태로 있다.
2. 다른 쓰레드2가 같은 변수의 값을 변경한 후 다시 원래의 값으로 되돌린다. (Main Memory까지 쓴다는 것)
3. 다시 쓰레드1이 변수의 값을 다시 읽는 경우가 문제가 된다.
이 경우 쓰레드1은 변수의 값이 이전과 동일하다고 판단할 수 있지만, 사실은 중간에 값이 변경되었다가 다시 돌아온 것이기 때문이다. 이것을 보고 ABA 문제라고 한다. 이러한 ABA 문제는 일반적으로 스택이나 큐 등의 자료구조에서 발생할 수 있다고 한다.
위에 적은 것처럼 중간의 변경 사항이 무시된다면 데이터 무결성에도 문제가 될 것이며, ABA 문제 도중에 계속해서 쓰레드가 대기를 해버리는 데드락의 위험도 있다고 한다.
AtomicStampedReference나 AtomicMarkableReference와 같은 클래스를 사용한다면 변수의 값을 변경할 때마다 버전 관리를 할 수 있다. 버전 정보가 함께 저장되므로, 쓰레드가 변수 값을 읽은 후 다시 쓰기 전에 변수의 버전 정보를 다시 확인하여 ABA 문제를 방지할 수 있다. 하지만 ABA 문제를 해결해 줄 뿐 완벽한 동시성 문제 해결책은 아니었다.
synchronized부터 Atomic Class까지 찾아보면서 은총알은 없다는 말이 생각났다. 이러한 문제점들을 고심해 보면서 어떤 자료구조를 사용할지 생각해 봐야겠다.
