1. Super()
DRF 내용이 심화될수록 심심치않게 super()의 등장을 볼 수 있었다.
이 super()란
Override에서처럼 부모의 동작을 가져와서 바꾸어 사용하는 것이 아닌
부모의 동작을 그대로 하면서, 다른 동작을 끼워넣고만 싶을 때 사용하는 것이다.
아래 코드를 보며 super()가 어떻게 동작하는지 이해해보자.
class Animal():
def __init__(self, name):
self.name = name
def walk(self):
print("걷는다")
def eat(self):
print("먹는다")
def greet(self):
print("{}이/가 인사한다.".format(self.name))
class Human(Animal): # Human 클래스(자식)는 Animal 클래스(부모)를 상속받는다.
def __init__(self, name, hand):
super().__init__(name) # 부모 클래스인 Animal 클래스의 __init__메소드(생성자)를 그대로 실행하고
self.hand = hand # 그 다음 이 구문을 실행함
# 즉, Human 클래스의 생성자는 self.name과 self.hand를 가진 인스턴스를 만들어준다
def wave(self):
print("{}를/을 흔들면서".format(self.hand))
def greet(self):
self.wave() # 자식 클래스(Human 기준으로 본인 클래스에 해당하므로 self)의 wave 메소드 실행 후
super().greet() # 부모 클래스의 greet 메소드 실행한다
person = Human("사람", "오른손")
# Human 클래스의 생성자를 지나가는 과정에서
# 1) 먼저 부모 클래스의 생성자를 통해 self.name에 '사람' 저장
# 2) 다음 본인 클래스의 self.hand에 '오른손' 저장
# 하여 Human 클래스의 인스턴스 person 생성
person.greet()
# person 인스턴스는 Human 클래스에서 생성되었으므로 Human 클래스의 greet 메소드로부터 시작
# 먼저 self.wave()를 실행하므로 방금 저장한 self.hand인 '오른손'이 인자 값으로 들어가 '오른손을 흔들면서' 가 먼저 리턴
# 이후 super().greet() 실행하며 부모 클래스의 greet 메소드로 올라가 방금 저장한 self.name인 '사람'이 인자 값으로 들어가 '사람이/가 인사한다' 리턴출력 화면
2. TDD / Clean Architecture
Test Driven Development
(원문: https://www.rapidvaluesolutions.com/test-driven-development-in-a-clean-code-architecture/)
많은 개발자들은 clean한 코드에 대한 열망을 가지고 있다. 하지만 clean한 코드를 위한 리팩토링은 상당한 시간을 소모할뿐더러 그 과정에서 프로젝트의 전반적인 속도를 지체시킬 수 있다. 따라서 우리는 코드의 간결성과 깔끔함을 보장하면서 버그도 잡아주는 test 시스템의 개발을 원해왔다.
Test Driven Development은 기본적으로 에러를 줄이고 소프트웨어를 설계할 때 유연성을 증가시키는 것을 그 기본 방향으로 두고 있다. 개발 시에 잘못될 위험은 최대한 줄이고 배포 속도는 증가시킨다. 거침없는 소프트웨어 개발에 매우 적합하다. 애자일 방법론과도 접점이 있어, 작은 testing cycles를 프로세스 진행 중에 계속 반복하는 것이 그 주된 목표이다. 하지만 이 TDD로 어떻게 개발 효율을 극대화할 것이냐에 대해서는 의문이 있을 수 있다.
하지만 TDD는 실제로 애자일하고도 유연한 개발 환경에 대한 이상적인 솔루션이다. 개발 과정의 효율을 증진시키며 작은 문제 요인들은 제거하며 많은 이익을 줄 수 있다. TDD가 줄 수 있는 이점은 아래와 같다.
Better acceptance: It helps developers see processes from the viewpoint of the customer. It improves your chances of delivering the kind of product the customer will want.
Fewer bugs: Although this requires more tests and a longer testing run you save time down the line because you have fewer glitches. The end product is more reliable when it reaches implementation.
Better returns: Bugs result in delays and in today’s fast-moving world even a small delay can be costly. TDD ensures more reliable operations and, eventually, higher revenues.
Identifying voids: TDD allows you to automatically test every line of coding within minutes. It issues timely alerts allowing you to get things changed and save time and money.
Time to market: Although slower in the early stages, TDD will be quicker overall. This will help you get new developments to market much more quickly.
Cleaner and tidier code: The code which comes out the other side will be much cleaner, tidier and better organized.
The Clean Code Architecture
TDD는 clean code architecture이라고 불리는 개발론에서도 매우 중요하다. 이를 이해하기 위해서는 Business Rule과 System Architecture에 대한 이해가 선행되는 것이 좋다.
Business Rule
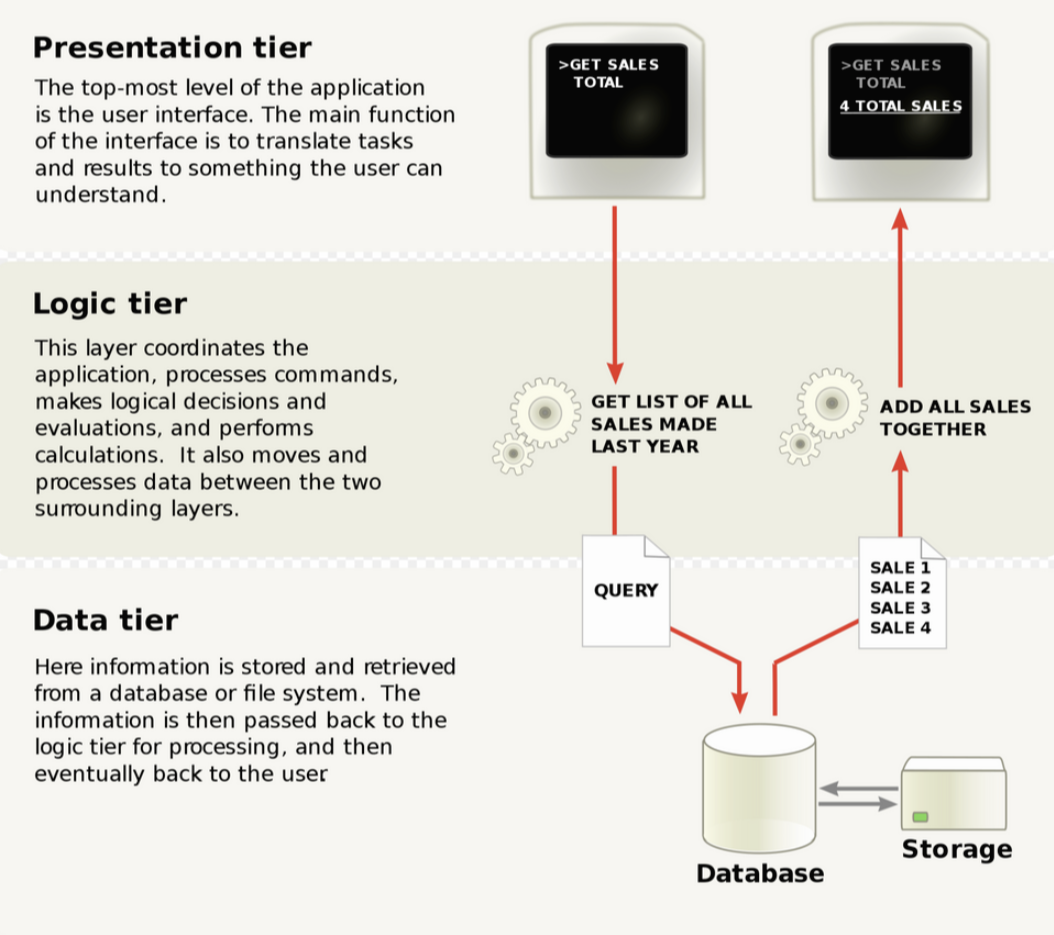
3-tier architecture에서의 Logic tier 부분. 컴퓨터 프로그램에서 실세계의 규칙에 따라 데이터를 생성/표시/저장/변경하는 부분을 일컫는다. (== domian logic)
아래 사진은 3-tier architeture에 대한 설명이다.
여기서 Business Rule(logic tier)은 유저의 입력(UI)과 DB 사이에서 발생한 정보 교환을 위해 특정 알고리즘이나 규칙이 정의된 tier를 이야기한다. 이는 고객의 요구에 따라 변경될 수 있으며, 그렇기 때문에 별도의 tier에 배치되어야 한다.
System Architecture
System Architecture란 시스템의 구조(structure), 행위(behaviour), 뷰(views)를 정의하는 개념 모델이다. 시스템의 목적을 달성하기 위해 각 컴포넌트가 어떻게 상호작용하고 정보는 어떻게 교환되는지 설명한다. 다양한 시스템 아키텍처가 존재하지만, 그들의 목적은 하나로 귀결된다. '관심사의 분리'가 그것이다. 소프트웨어를 계층으로 나누게 되면 관심사를 분리할 수 있는데, 이러한 목적을 가진 시스템 아키텍쳐는 다음과 같은 특징을 가진다.1) 프레임워크 독립적
System Architecture는 라이브러리 존재 여부나 프레임워크에 한정적이지 않아 도구로써 사용하는 것이 가능합니다.2) 테스트 용이
Business Rule은 UI, DB, Web Server 등 기타 외부 요인과 관계없이 테스트 가능합니다.3) UI 독립적
시스템의 다른 부분을 고려하지 않고 UI를 변경할 수 있습니다.4) Database 독립적
DB 또한 독립적으로 변경할 수 있으며 (SQL, Mongo, CouchDB 등), 이는 Buiness Rule에 얽매이지 않습니다.5) 외부 기능 독립적
Business Rule은 외부 상황(DB, UI)에 대해서 아무것도 모릅니다.
그리고 이러한 특징을 가지는 아키텍쳐에 대한 총 정리 느낌으로 Uncle Bob이 내세운 것이 바로
클린 아키텍쳐인 것이다.
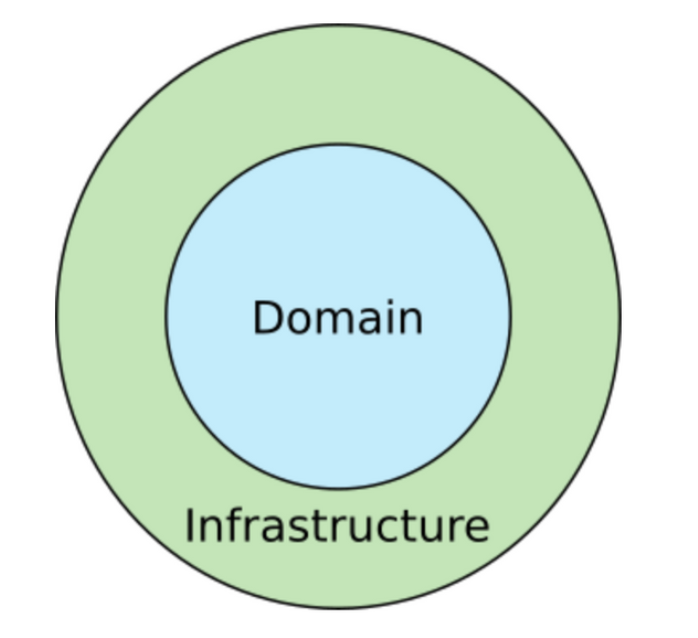
사진에서 Domain Layer는 Business Rule이 존재하는 영역이다. 잘 변하지 않는 안정된 영역으로, 비즈니스의 본질 부분이라고 볼 수도 있다. (ex. 번역 앱 : 번역, 쇼핑몰 앱: 판매)
Infrastructure Layer는 UI, DB, web APIs, Frameworks등이 존재하는 영역이다. 이는 Domain에 비하여 자주, 쉽게 바뀌는 영역이다. (ex. Business Rule인 대출 계산 방법에 비해 UI Button의 형태(UI)가 쉽게 바뀌는 것)
이렇게 레이어를 분리하고 경계를 두는 것, 그리하여 결국 '관심사를 분리'하는 규칙을 Uncle Bob은 의존성 규칙(Dependency Rule)이라 설명하였다.
의존성 규칙 (Dependency Rule)
"모든 소스 코드 의존성은 반드시 Outer에서 inner로, 즉 고수준 정책을 향해야 한다."
결국, 비즈니스 로직을 담당하는 코드들(해당 비즈니스의 본질에 해당하는 코드들)은
DB 또는 Web같이 구체적인 세부사항에 의존하지 않고 독립적으로 실행되어야 한다는 규칙이다.
생각해보면 inner cycle에 해당하는 domain영역의 로직은 outer cycle에 해당하는 infrastructur에 대해 아무것도 모른다. 이 말을 달리 하면 결국 UI, DB는 Business rule에 의존하지만 반대로 Business rule은 그렇지 않다는 것이 된다. (UI가 웹이건, 모바일이건 DB가 SQL이건 NoSQL이건 Business rule입장에서는 아무런 상관이 없다는 말) 이렇게 분리된 계층 구조 덕에 Infrastructure를 쉽게 변경할 수가 있게 되는 것이다.
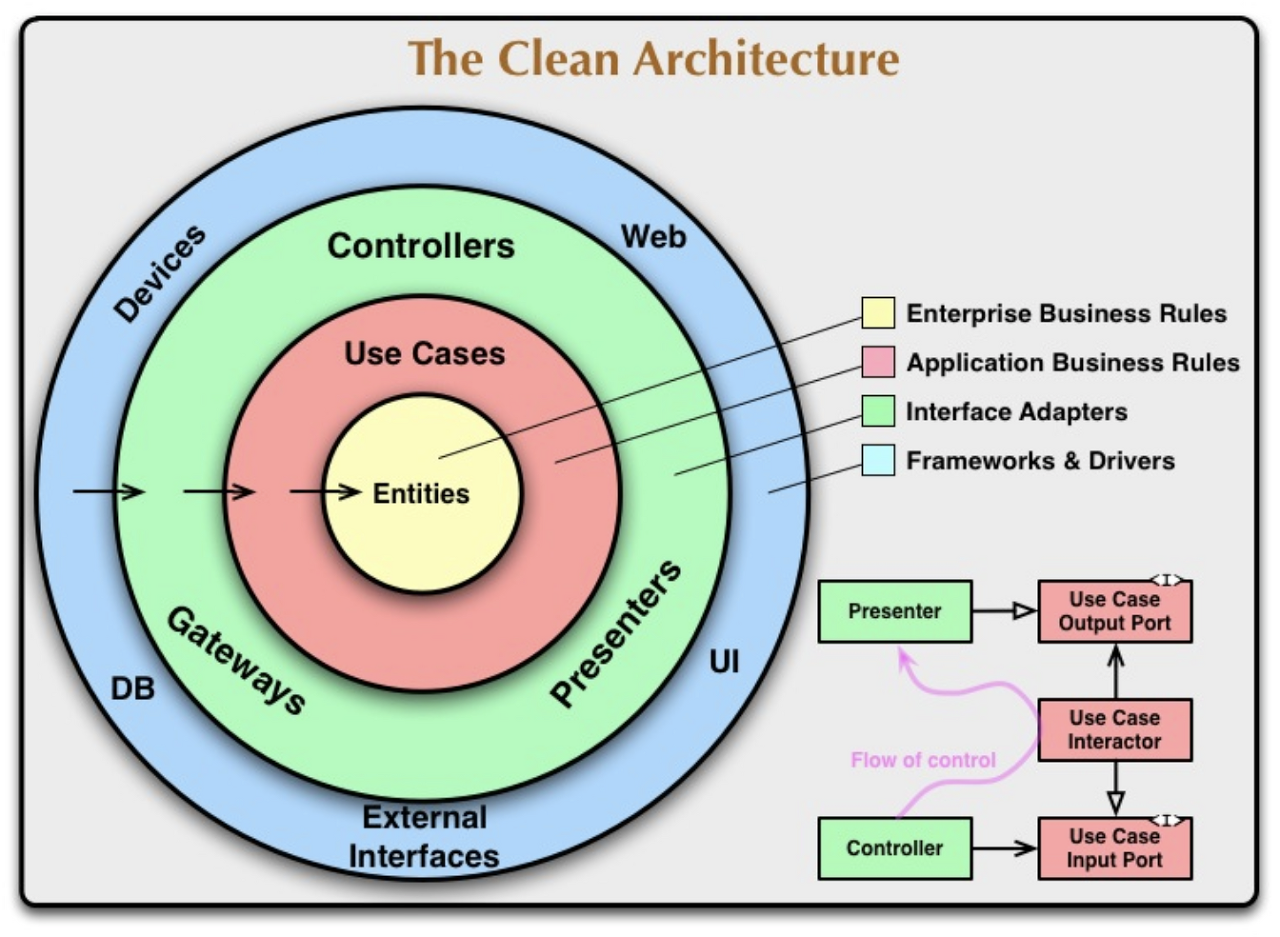
기존 그림의 Domain이 Entities, Use Cases로 세분화되었고
기존 그림의 Infrastructure는 External Interfaces - DB, Devices, Web, UI로 세분화되었다.
그리고 기존의 Domain과 Infrastructure를 경계 짓는 부분에 Controllers, Gateways, Presenters(Interface Adapter) 부분이 새로 생겼다.
이 그림 또한 Dependency Rule에 의거, outer에서 inner로의 의존성을 띄게 된다.
Entities
애플리케이션에서 핵심적인 기능인 Business rule을 담고 있다. 쉽게 말해, "대출 이자 10%"라는 규칙을 가진 은행의 "대출 이자 10%"가 바로 Entity에 속하는 것이다. 위에서 말했듯 이런 entity는 외부 상황(outer layer)에 대한 이해가 전혀 없어도 된다. 즉, 이 10%의 이자를 손으로 계산할지 컴퓨터로 계산할지 핸드폰으로 계산할지 전혀 신경쓰지 않아도 된다는 것이다.
Use Cases
특정 애플리케이션에 대한 Business rule이다. 이는 시스템이 어떻게 자동화될 것인지 정의하여 app의 행위를 결정한다. 다시 말해, 프로젝트 레벨의 business rule을 사용하여 use cases의 목적을 달성한다. 역시 outer layer에 대해서는 아는게 없고 entity 의존적이며 entity와 상호작용한다. 다음의 예시는 use cases를 위한 특정 애플리케이션에 대한 business rule의 목록이다.
Gather Info for New Loan Input: Name, Address, Birthdate, etc.
Output: Same info + credit score
Rules:
1. Validate name
2. Validate address, etc.
3. Get credit score
4. If credit score < 500 activate Denial
5. Else create Customer (entity) and activate Loan Estimation이 대출이 웹에서 이뤄지든 앱에서 이뤄지든 그리고 저장이 클라우드에 되든 sql에 되든 Use cases는 관심이 없다. 다만 이 계층에서는 outer layer에서 사용할 수 있는 abstract class나 interfaces를 정의하게 된다.
Infrastructure
모든 I/O components(UI, DB, Frameworks, Devices)가 있는 곳. domain과 달리 언제든 변화할 수 있어서 확실히 분리가 되어 있는 것.
Controllers - Presenters - Gateways (교차 경계 부분)
Controllers --> Use Cases(Business Rule) --> Presenter로 Flow of Control이 진행된다. 그런데 이렇게 보면 이상한 점이 분명 저수준에서 고수준으로(outer --> inner) 흘러야한다했는데 Use cases --> presenter라면 그 반대이다. 이 문제를 해결하기 위해 Dependency Inversion Principle(의존 관계 역전의 원칙)이 나온다. 지금껏 이야기했던 Dependency Rule은 사실 아래의 두 상황을 고려하여 지켜지는 것이다.
What data crosses the boundaries & Crossing Boundaries
의존성 규칙을 지키기 위해서는 단순하고, 고립된 형태의 데이터 구조를 사용해야 한다. DB 형식의 데이터구조나 framework에 종속적인 데이터 구조를 사용하게 될 경우 저수준의 데이터 형식을 고수준에서도 알아야하는, 의존성 규칙 위반이 가능하다.
그리고 때로 제어의 흐름이 위에서처럼 outer --> inner가 아닌 inner --> outer이라면, 이는 의존성 규칙에 위배되는 것이니 의존 관계 역전의 원칙을 이용하여 해결해야 한다. 즉, 고수준에서 저수준에 직접 참조하게 될 때에는 Interface를 하나 두어 저수준의 세부사항까지 알지 못해도, 혹은 저수준에 변동사항이 다소 생기더라도 참조할 수 있게 되는 것이다.
정리
- 클린 아키텍쳐는 의존성 규칙을 따름으로서 관심사를 분리 시키고
- 본질적으로 테스트하기 쉬운 시스템을 만들 수 있다(TDD)
- 같은 상황과 이유로 변경되는 class들은 components로 묶을 수 있다
- Business Rule은 Stable한 components로 변경되기 쉬운 외부의 Infrastructure components(UI, DB, web, frameworks)의 상황을 알지는 못한다. 이 두 레이어의 관계는 adapter 인터페이스를 통해 관리되며 adapter는 레이어간의 데이터를 편한 형태로 변환시켜주고 더 stable한 inner components로 의존성을 가지도록 한다.
references:
https://k-elon.tistory.com/38 (Business Rule, System Architecture)
https://programmers.co.kr/learn/courses/2/lessons/330 (super())
