[SuperfluidClone] 2nd project - superfluid 클론: 프로젝트 회고록

SuperFluid 프로젝트 영상
Team get_refund
한 달 전 참여하고 싶은 프로젝트에 투표할 때만해도 어떤 웹페이지를 고르는 것이 현명할지에 대한 판단 기준을 설정하기 어려웠다. 결국 UI가 깔끔하고도 아름다워서 편리함과 심미성을 모두 만족시킬 수 있는 페이지들을 선택했는데, 1차 프로젝트가 남성 유저들이 주된 소비자층을 이루는 면도기 사이트였다면 이번 2차 프로젝트는 공교롭게도 여성들을 주로 타겟으로 하는 화장품 사이트를 맡게 되었다.
Frontend 김신영(PM), 박예진, 최운정
Backend 안솔, 황수미
2차 프로젝트는 이렇게 다섯명의 팀원이 '환불원정단' 팀이 되어 화기애애한 분위기 속에서 2주간 쉴틈없이 작업했다.
BackEnd
백엔드는 웹 페이지의 기능을 크게 세 개로 나누어 작업했다.
- 사용자의 정보를 다루는 User 앱 : SignUp, Login, MyPage
- 상품 정보를 다루는 Product 앱 : List(전체 상품/카테고리별 필터링한 상품 보여주기), Detail(상품 상세 페이지)
- 해당 사용자의 주문 상품을 다루는 Order 앱 : Cart(상품 장바구니에 담기, 담긴 상품 수 보여주기, 카트 내 YouMayAlsoLike에 추천상품 띄우기), Order(담은 상품 주문하기)
이 중 나는 User 앱과 Product 앱 중 List 부분을 작업했다.
적용 기술 & 사용한 협업 툴
- Language & Framwork: Python, Django Web framework
- Web Crawling: BeautifulSoup, Selenium
- Token: Bcrypt, JWT, KAKAO social login
- Database: MySQL, AWS RDS
- CORS(Cross Origin Resource Sharing) headers
- Co-op: Github, Slack, Trello
- Data Modeling: AqueryTool
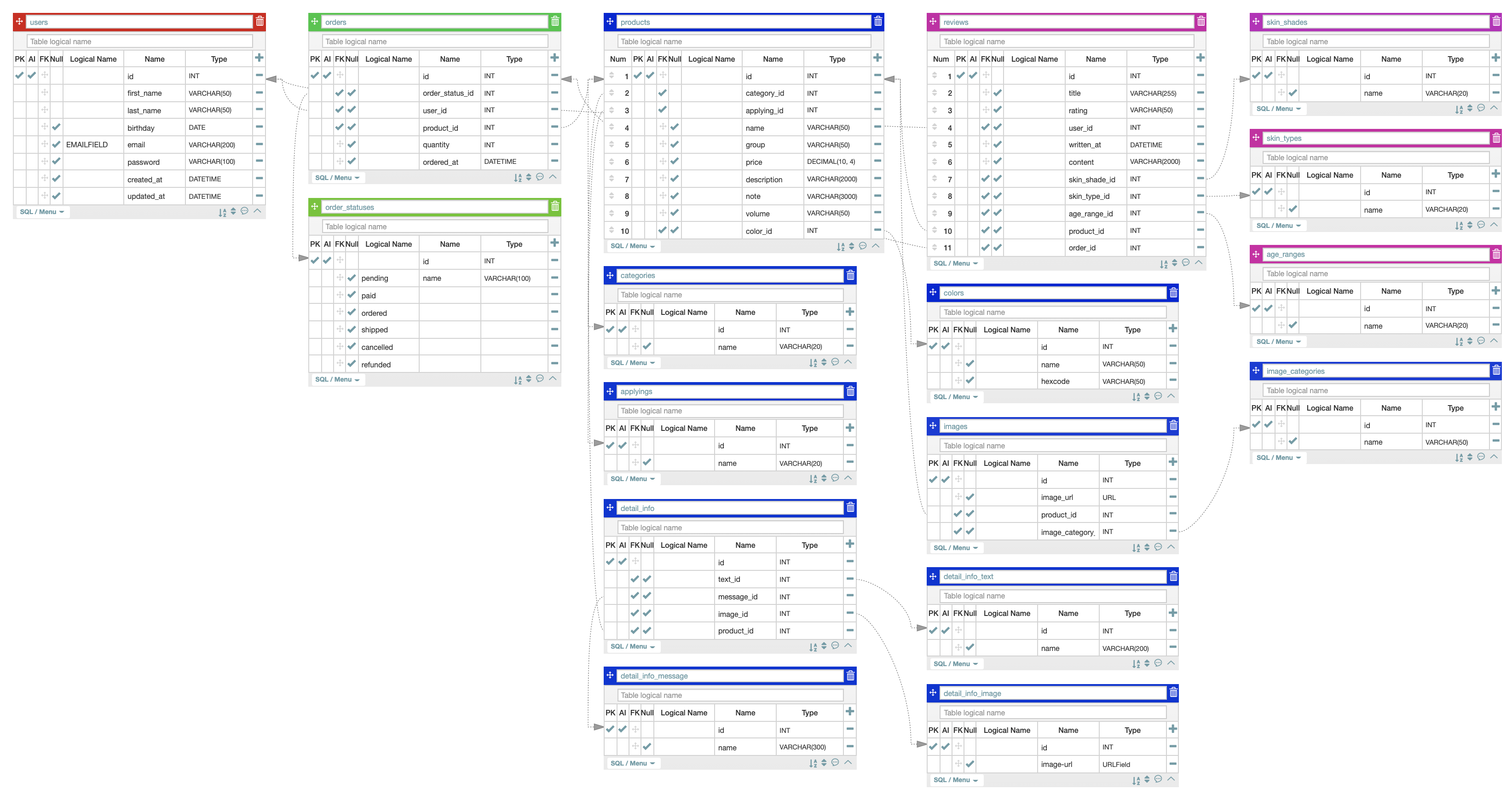
2차 프로젝트를 하며 가장 많이 성장한 점
Communication
프론트와의 소통의 중요성을 많이 느꼈다. Key값을 무엇으로 둘 것인지, 데이타를 보내줄 때 어떤 메소드를 사용할 것인지(ex. GET, POST), 어떤 형식(ex. list, dictionary, Tuple 등등) 으로 보내줄 것인지에 대한 논의를 거치지 않고 코드를 작성할 경우 프론트와 합을 맞추는 과정에서 작성한 코드에 대한 2차 수정이 불가피하다. 모든 작업을 프론트와 맞춰가면서 하기는 어렵겠으나, 어느 정도는 서로간에 선 논의가 이루어지면 작업이 한결 수월해진다는 것을 알았다. 특히 key 값을 맞출 때에는 영어 대소문자 하나로도 데이터 송/수신이 아예 이루어지지 않을 수 있기 때문에 섬세히 맞추어야 한다.
Git - rebase
1차 때 git을 다루며 git pull origin master + add - commit - push에 걸친 3단계 기본 스텝을 이해했다면 이번 2차 프로젝트에서는 REBASE라는 한층 더 지옥의 향이 짙은 기술을 알게 되었다. REBASE는 말그대로 Base를 바꾸는 일인데, Merge와 비슷해보이지만 개념적인 차이가 있어 이 둘의 차이점의 대조를 통해 이해하는 것이 좋다.
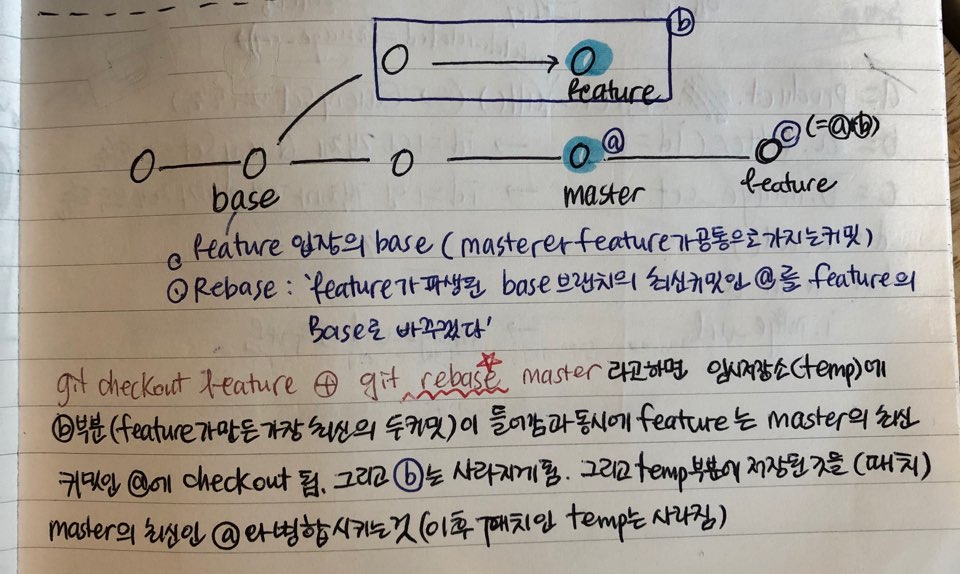
Merge가 새로운 Merge base를 만들며 branch를 통합하는 개념이라면, Rebase는 branch의 base(== 해당 branch를 생성하던 그 시점의 master branch의 base)를 옮긴다는 개념이다.
이 개념을 이해하기 위해 내가 손으로 적었던 노트는 아래와 같다.
rebase를 이해하기 위해 찾아본 많은 youtube 클립에서 리베이스를 할 경우 git log가 linear한 형태로 변하기 때문에 깔끔해진다는 설명들이 많았다. linear한 git log에 대한 이해는 다음 그림으로 할 수 있었다.
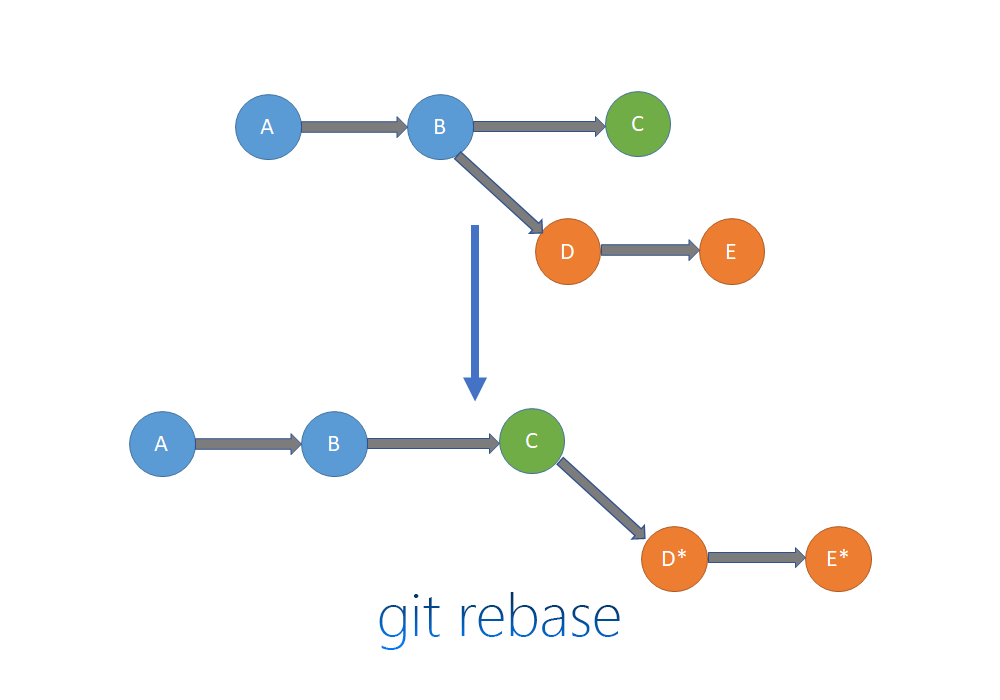
git rebase를 할 때의 각별한 주의점이라면
1) 내가 현재 작업중인 branch 확실히 파악 : 기능별로 브랜치를 생성하여 작업하겠다고 다짐했음에도 불구하고 하나의 작업을 하다가도 다른 앱의 작업이 생각나면 바로 해야할 것 같은 마음에 브랜치를 checkout하지 않고 바로 이동해서 작업을 하곤했다. (그 때는 몰랐다 이것이 얼마나 큰 불상사를 불러올 것인지...) 반드시, 하고자 하는 작업을 위해 생성한 the 브랜치에서만 그 작업을 해야 한다. 만일 중간에 다른 작업을 해야할 경우라면 git add와 git commit을 통해 로컬에 저장을 확실히 마친 후,
git checkout feature/[다른 브랜치명]명령어를 통해 해당 브랜치로 넘어가서 그 다른 작업을 시작하자.2)
git pull origin master: 이 명령어는 작업을 시작하기 전에 한 번, 그리고 rebase를 하기 직전에 한 번 이렇게 두 번 하는 것이 가장 좋을 것 같다. 내가 작업을 시작하기 전 누군가가 이미 코드를 작성했을 수 있기 때문에 작업 전에 로컬 마스터를 최신화하기 위한 한 번이 먼저 필요하다. 이후 최신화된 코드를 가지고 특정 브랜치에서 코드를 작성하는데, 내가 코드를 작성하는 동안 팀의 누군가가 또다른 코드를 업로드했을 수 있기 때문에, rebase 직전에도 한 번이 필요한 것이다. (사실 이 중 한 번만 해도 된다고 들었는데, 혹시 모르는 불안한 마음에 나는 그냥 두 번하는 것으로 정했다.)3) Rebase flow
1️⃣ 특정 앱 기능 구현을 위해 생성한 브랜치에서 코드를 작업한 후,git add와git commit을 통해 우선은 로컬에 저장을 완료한다. (commit까지 모두 마친 후git status를 통해 working tree clean을 반드시 확인)
2️⃣git checkout master를 통해 마스터 브랜치로 이동하여git pull origin master(리베이스 전 로컬 마스터 최신화) 이 과정에서 conflict이 발생할 경우 해결한다.
3️⃣ 자 우선, 다음은git checkout feature/[작업 중이었던 브랜치명]로 작업중이었던 브랜치로 이동한다. 그리고 여기서 주의 ⭐️ 원래라면 이제부터git merge master를 통해 로컬 마스터로 최신화시킨 코드를 브랜치로 당겨와서 conflict을 해결한 후git push origin master였겠지만, 리베이스는 그렇지 않다. 작업중인 브랜치로 이동한 후 바로git rebase -i master명령을 입력한다.
4️⃣ 이후 마주하는 화면이 중요하다. 이 때는 내가 해당 브랜치에 했던 commit 목록이 모두 보이게 된다. 가장 처음 base로 만든 커밋에는 pick을, 그 이후 작업하여 쌓인 commit들에는 s(squash를 의미 - 으깨어 합치겠다는 뜻) 를 써서 커밋 내역들을 모두 합친다. 이후 나올 때는 :wq
5️⃣ 이후 어떤 커밋 메시지로 이 rebase commit을 저장할 것인지 고르는 화면이 나오는데, 가장 최신의 커밋내용으로 보통 작성하게 된다. 역시 내용 저장 후 나올 때는 :wq
6️⃣ 그러면 successfully rebased라는 화면이 보통 나온다. 만일, conflict가 발생할 경우 automerge된 부분을 제외하고 해당 conflict가 발생한 곳(친절하게 어느 곳인지 다 적혀있다)에 가서 conflict를 해결한다.
7️⃣ conflict를 모두 해결한 후에는git push origin feature/[작업중인 브랜치명]을 입력하여 origin의 feature 브랜치로 리베이스를 완료한다. 하지만 이 때 역사가 꼬이면서 깃은 'rejected'라는 상태 메시지를 반환할 것이다. 당황하지 않고git push origin feature/[작업중인 브랜치명] --force로 강제 푸시한다.
7️⃣ 이후 github 웹으로 들어가면, commit 내역이 하나만 남은 깔끔한 PR 메시지를 확인할 수 있다.
여기까지가 내가 이번 프로젝트를 하며 수행했던 리베이스 과정이었다.
리베이스 개념을 도입하기 전 내 PR 메시지가 아래와 같았다면,
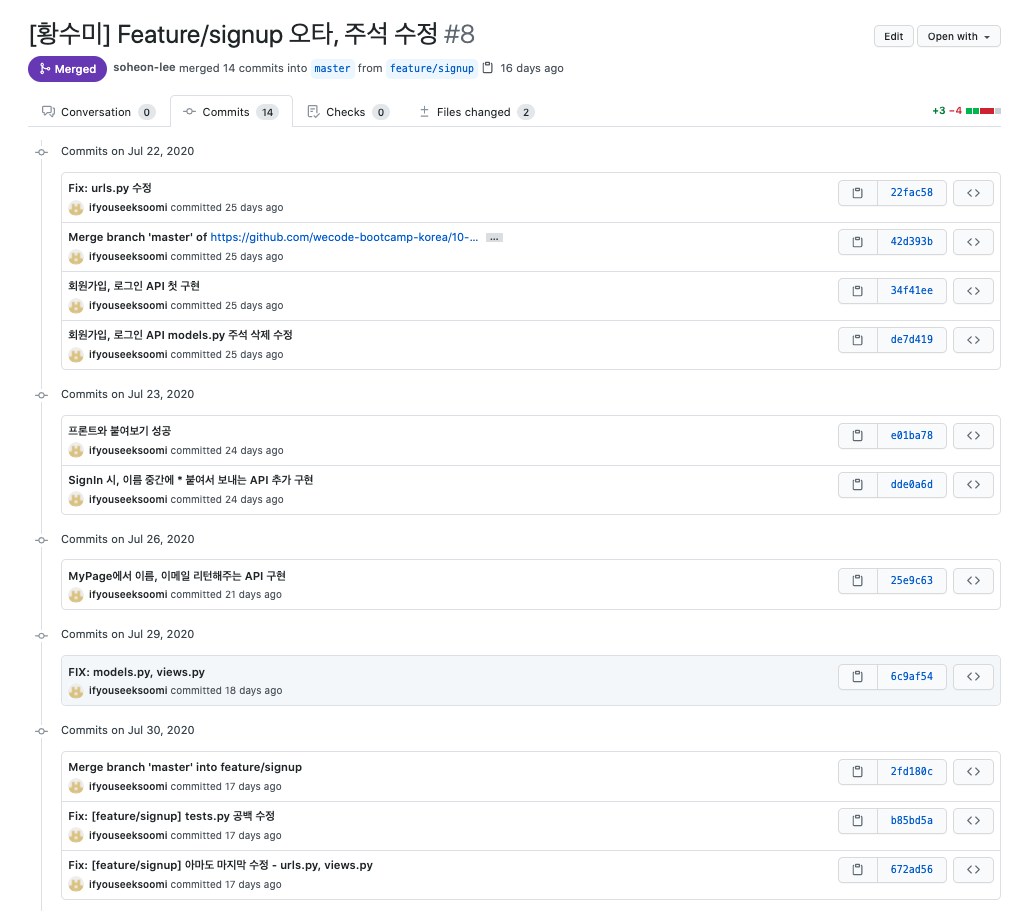
리베이스를 하니 실제로 PR 메시지가 깔끔하게 1 commit으로 보기 좋게 정리되는 것을 확인할 수 있었다. (더 많은 수정이 있었음에도 불구하고)
METHOD: RESTful API
GET method와 POST method의 확실한 차이를 이해했다. REST API의 중요성에 대한 세션을 들었고, RESTful하게 작성하기 위해 GET, POST, PUT, PATCH, DELETE 등을 사용한다는 것을 알고는 있었으나 실제로 적용해볼 기회는 없었다. 1차 프로젝트때도 구현했던 User앱 내 Signup, Signin은 실제 회원 정보를 받아 DB에 저장해야 하고(SignUp), 회원이 아이디(이메일)를 입력했을 때 실제 우리에게 저장된 회원이라면 토큰을 발급해줘야 하는(SignIn) 프로세스라 POST 메소드를 사용하는 것이 바람직하다. 여기까지는 알고 있었다.
MyPage뷰를 처음 구현해보며 알게된 새로운 사실은 한 클래스, 즉 하나의 API를 작성할 때도 정보를 보여주는 성격에 따라 각각 다른 메소드를 사용할 수 있다는 것이었다.
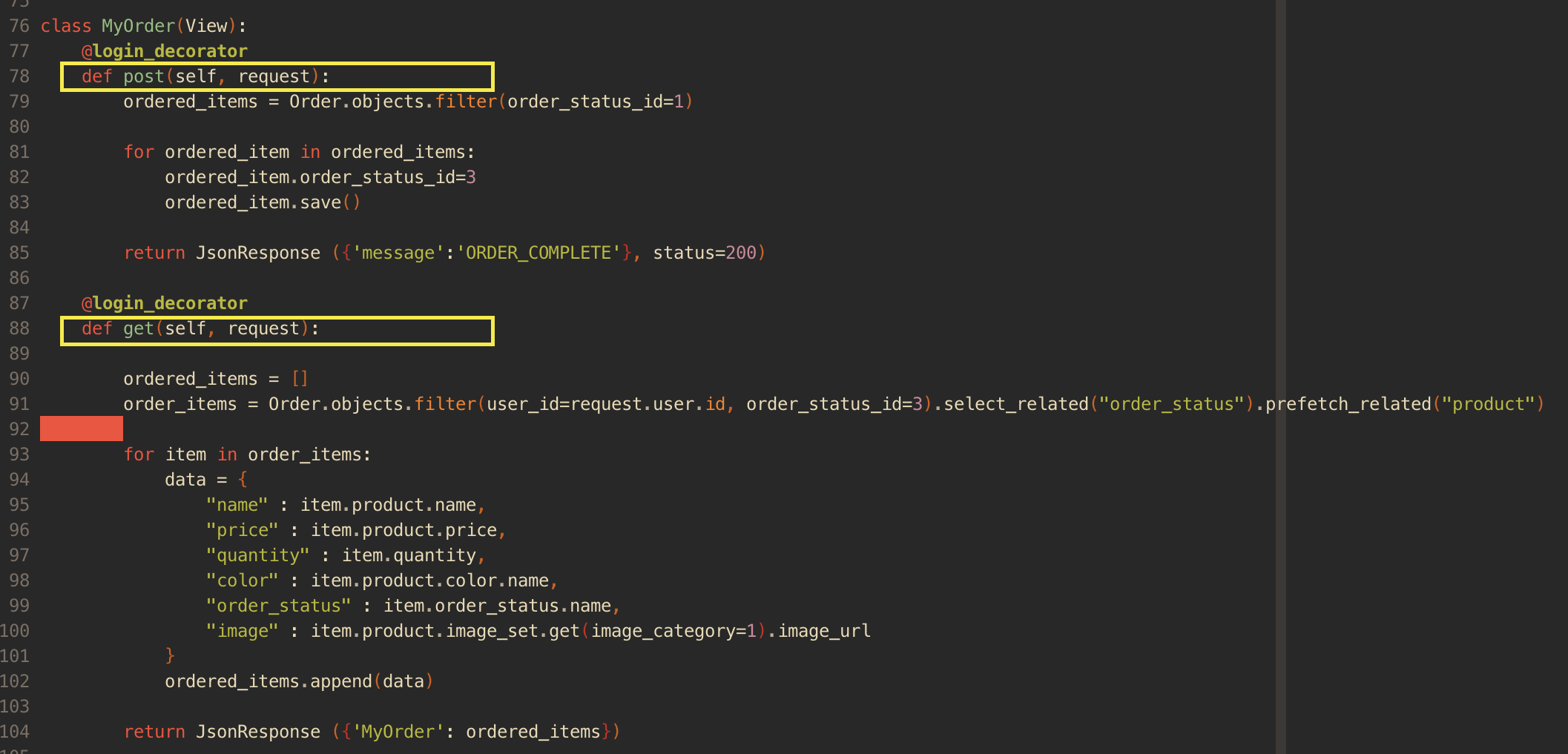
사용자가 카트에 상품을 담으면 해당 상품은 카트에 담긴, 즉 주문 상태가 'pending'으로 저장되도록 모델링을 했다. 이후 상품을 주문하기를 누르면 주문 상태가 'ordered'으로 저장되도록 바꾸어 저장하는 방식으로 카트에 담기기만 한 상품과 주문이 모두 완료된 상품을 구별하기로 했다. 따라서 나는 POST 메소드를 이용하여 먼저 상태를 'ordered'로 바꾸어 저장하고, 이후 주문 상품을 보여주기 위해 GET 메소드를 이용하여 주문 상품의 상태가 ordered인(order_status_id가 3인) 상품을 유저에게 보여주면 되었다.
돌아보니 간단한 방식이고 간단한 코드인데, 첫 구현이라 스스로 생각하는 것 자체가 너무 어려웠다. 함께 작업한 백엔드 팀원과 위코드 동료들의 도움이 없었으면 생각해내기 어려웠을 코드였다.
프로젝트를 마치며
잘한 점
-
실제로 혼자서 해결해보고자 많이 노력했다. '혼자할수있ability' 경험치를 쌓고 싶었다. 물론 너무도 어려운 과정이었고 나름 많이 고민했는데도 해결되지 않아 답답한 경우가 더 많았다. 하지만 고민했던 흔적들이 지금와서 돌아보니 조금 connect the dots 되는 느낌이 든다.
-
스탠드업 미팅에서 흐름을 놓치지 않기 위해 노력했다. 프론트와의 소통은 용어, 개념적인 어려움이 있어 물론 어려웠지만 그래도 한마디라도 하면서 이해하려고 했다. 1차 때 이 부분이 가장 어려웠는데, 이번에는 그래도 뭐라도 말해보려고 이해해보려고 끊임없이 노력했다. 백엔드 팀원과도 거의 매일 이야기하며 진행했는데 이해가 되지 않는 부분에 대해서 계속해서 질문하며 해보고자 노력했다.
-
RDS에 미리 DB서버를 구축하여 작업을 진행했다. 이 부분은 함께 작업한 백엔드 팀원의 제안이었는데, 미리 RDS 서버를 구축해두니 DB 사용에 있어서 merge되기 전의 DB임에도 서로 확인할 수 있어 편리했다.
-
모델링에 적극 참여했다. 모델링이 사실상 백엔드에서 가장 중요한 부분이라는 것을 1차 프로젝트를 통해 많이 느꼈기 때문에 일대다, 다대다, 일대일 관계를 완전히 이해하지 못한 상태라고하더라도 써보려고 노력했다. 같이 참여했음에도 잘 이해가 되지 않는 부분으로 고민하는 내게 같은 팀 백엔드 팀원이 "직접 종이에 테이블을 그려가며 이해해보라"며 해준 조언도 큰 도움이 되었다.
아쉬운 점
-
깃이 많이 꼬였다. 서버를 돌리며 프론트와 데이터를 맞춰보는 과정에서 디렉토리를 하나 복사해서 작업을 시작하게 되었다. 기능별로 브랜치를 생성해서 작업했기 때문에 한 브랜치에서 서버를 일단 돌리면 다른 브랜치로 넘어가 작업하는 것이 불가능했기 때문이다. (merge 전의 이야기이다.) 원래 작업하던 본 디렉토리(get_refund)를 고대로 카피하여 2nd 디렉토리(get_refund_mypage)를 만들었다. 여기서 실수가 났다. 디렉토리 두 개를 서버용, 작업용으로 완전히 분리하고 사용했어야 했는데 서버도 돌리다가 작업도 하고, 작업하다가도 서버도 돌리고 하는 식으로 디렉토리 기능별 분리에 실패해버렸다. 게다가 브랜치를 기능별로 많이 생성해 놓고는 역시 브랜치에서도 checkout을 확실히 하지 않고 작업한 탓에 디렉토리 별 구분도 되지 않는데 브랜치 별 구분도 어려운 상황까지 덮쳤다. 나중에는 프론트 쪽에서 "서버 띄워주세요"라고 했을 때, 해당 서버를 어디가야 에러 없이 띄울 수 있는지 그 지점을 찾는 것이 거의 불가능해졌다.
대체 이게 뭔일인가 싶어 당시 공책에 정리했던 내용은 아래와 같다.

이렇게까지 정리를 해봐도 다시 에러가 나고, 또 에러가 나고, 왜 나는거지? 왜 또 그러지? 의 상황이 반복되었다.
정말 너무너무 복잡하고 막막했는데 위코드 멘토님이 해답을 주셨다. 3rd directory(get_refund_third)를 만들어 origin으로 merge되었거나 push된 PR들을 모두 pull 받아서 3rd directory를 깨끗하게 재구성하는 방법이었다. 이 방법으로 가까스로 너무도 꼬여버린 실타래를 풀 수 있었다. (멘토님이 merge해주시지 않았다면 정말.. 어려웠을 것... ㅠㅠ 감사합니다.)
-
코드를 더 효율적으로 짜지 못한 것이 아쉽다. product에서 상품의 전체 리스트를 보여주는 뷰나, 필터링된 리스트를 보여주는 뷰를 보여주기 위해 DB hit를 46회나 하는 바람에(...) 속도가 매우 저하된 것을 보고 이건 뭔가 잘못되었다는 생각이 들었다. 원인은 둘 중 하나로 생각된다. for 문을 들어가기 전에 먼저 select_related와 prefetch_related를 이용하여 사용할 DB를 모두 긁어 놓은 후, for문에서는 딱 for 문만 작성해서 깔끔하게 DB를 긁어야했는데 그렇지 못해서 속도가 저하되었을 수 있다. 혹은 RDS를 미리 구축해 놓았는데 region 설정이 미국 동부로 되어있어서 거기서 오는 속도 저하가 있었을 수 있다. 멘토님들과 이야기한 결과 아마도 데이터 모델링을 할 때에 정보 자체를 원활하게 긁어오는 방향이 아니게 모델링을 해놓은 탓이 더 클 수 있다는 이야기를 들었다. 모델링이 모델링을 위한 모델링이 아니라 이후 DB에서 정보를 이용할 때에 효율적인 방향으로의 모델링이 되어야겠다는 생각을 해봤다.
--> <1차 수정> RDS에 DB 서버를 구축한 후 로컬로 돌렸을 때는 상품 전체 리스트 하나를 봐도 10초 정도의 로딩시간이 있었다. 하지만 지금 현재 서버를 아마존에 배포하니 속도가 빨라졌다!! 모델링보다도 RDS에 먼저 DB 서버를 구축하고 로컬로 서버를 띄운 것이 속도 저하의 이유였던 것으로 밝혀졌다.
- 1차 프로젝트 이후 꼭 해야겠다고 다짐했던 Unittest, 정규 표현식을 작성하지 못했다. 개인 프로젝트가 아니라 팀이 협업해서 하는 일이라 하고 싶었지만 "이걸 하다가 내가 API를 구현하지 못하면 어쩌지"라는 압박이 있어 시간 투자를 완전히 하지 못했다. 내일부터 시작되는 위코드 3개월차 일정에서 나는 Unittest와 정규표현식부터 공부해서 리팩토링하는 것을 목표로 삼았다. 잘 알고 넘어가야 하는 중요한 부분이므로 포스팅도 할 계획이다.
감사
팀원들에게, 그리고 특히나 함께 백엔드로서 참여한 안솔님에게 큰 감사를 표하고 싶다. 너무 많이 질문했는데도 많은 도움을 주었고 함께 가고자 노력해주어서 고마웠다. 그리고 다른 팀이었지만 사실상 객원 멤버처럼 참여해주신 많은 백엔드 동료분들께 정말 큰 감사를 보낸다. '함께해서 위코드'라는 말을 느낄 수 있던 소중한 시간이었다. 남은 1개월도 동료들과 함께 스터디하며 잘 정리해서 어느정도 완성도 있는 '혼자할수있ability'를 갖출 수 있으면 좋겠다.
기억에 남는 코드
이번에 작성했던 모든 코드가 기억에 남는다. 꽤 내용이 길어질 것 같아, 더 상세한 내용은 새로운 포스팅으로 올리도록 하겠다.
references:
https://cyberx.tistory.com/96 (git rebase 개념)
https://firework-ham.tistory.com/12 (git rebase 사진 참고)
