How Google’s PageRank Algorithm Works – A Mathematical Exploration
Googling — the act of searching the Internet using the Google search engine — has become deeply ingrained in many world languages. Depending on our interests, we “Google” daily to find information on virtually anything: from recipes, music, celebrities, and cars to scientific research and the latest world events. With just a few clicks, global information is at our fingertips. But have you ever wondered how Google actually works? How does it rank search results?
At first glance, one might think Google places the most-visited sites at the top. However, that’s not how search ranking functions. What makes Google unique is its use of the PageRank algorithm, which ranks web pages by importance based on hyperlinks. The algorithm was developed by Larry Page and Sergey Brin at Stanford University in 1996. While Stanford retained the patent, Google secured exclusive licensing rights. The name “PageRank” comes both from the concept of a “web page” and from co-creator Larry Page.
The core idea is simple: important pages are those that many other pages link to. Moreover, links from highly important pages carry more weight. In mathematical terms, PageRank assigns each page a value between 0 and 1, representing the probability that a random web surfer will land on that page by continuously clicking links.
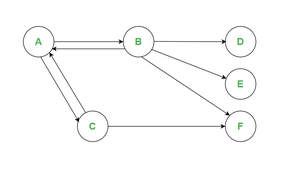
PageRank can be viewed as a directed graph, where vertices are web pages and edges are hyperlinks. The larger the circle (vertex), the more important the page. To illustrate, consider a simplified set of four pages: A, B, C and D.
Initially, each page is assigned an equal value of 0.25. The PageRank of page A, denoted PR(A), is calculated using the formula:
PR(A) = PR(B)/L(B) + PR(C)/L(C) + PR(D)/L(D)
where L(V) is the number of outgoing links from page V. Substituting values, we get:
PR(A) = 0.25/2 + 0.25/1 + 0.25/3 = 0.458
Thus, there is a 45.8% probability that a random surfer will arrive at page A.
In more advanced versions of the algorithm, additional factors are considered. One of the most important is the damping factor (d), usually set at 0.85, which represents the probability that a user continues clicking rather than stopping. With the damping factor included, the formula becomes:
PR(A) = (1 – d)/N + d × (PR(B)/L(B) + PR(C)/L(C) + PR(D)/L(D))
where N is the total number of pages (in this case, 4).
If a page has no outgoing links, it is treated as if it links to all pages in the set. Similarly, if a page has no incoming links, a small value is added to it in each iteration (via the damping factor) to ensure it still has influence.
Mathematically, PageRank can be modeled as a random walk on a Markov chain, where edges represent transitions from one state (web page) to another. Over many iterations, the PageRank value reflects the long-term probability of reaching a particular page.
Of course, search engine optimization has also led to manipulation attempts, such as companies selling high-ranking backlinks. To counter this, Google penalizes paid or unnatural links when detected. Despite these challenges, PageRank has historically provided much more accurate results than competing algorithms, helping Google rise above other search engines. Today, PageRank is still in use, but as just one component of Google’s far more complex ranking system.
Behind every algorithm lies a mathematical foundation requiring a strong grasp of mathematics and programming. Fortunately, such skills can now be acquired through online tutoring (online instrukcije). One of the first platforms in Europe specializing in this approach is eMatematika (Croatia), a web-based service for tutoring in mathematics, physics and computer science (instrukcije iz matematike, fizike i informatike). Its instructors — many of whom are former national competition finalists — make complex concepts like PageRank accessible and understandable, enabling students to apply this knowledge in their own development.
