Write policy
캐시 히트를 read hit과 write hit으로 분류할 수 있음.
read hit은 접근할 데이터가 캐시에 존재하는 경우.
write hit은 접근할 데이터의 주소가 캐시에 존재하는 경우.
On write hit
write through
CPU가 주기억장치 또는 디스크로 데이터를 기입하고자 할 때 캐시와 메모리 둘다 write. 메모리에 접근하고, 메모리에 write할 때 cpu는 대기하므로 속도 느림. 하지만 캐시와 메모리의 데이터 항상 일치. write buffer를 이용하여 성능 개선 가능. 캐시와 write buffer에 write 후 buffer가 가득 차면 메모리에 write.
write back
캐시에만 write 후 캐시에서 해당 데이터가 속한 블록이 교체되어 나갈때 메모리에 write. 속도는 빠르지만, 캐시와 메모리의 데이터 간에 inconsistency 존재.
On write miss
write allocation
캐시 라인(캐시 블록)이 메모리로부터 캐시에 올라오고 캐시에만 write.
자주 접근 되는 데이터의 경우 적용.
write back과 write allocation은 캐시만 업데이트 하는 방식이므로 연속적인 write 작업에 효율적이므로 일반적으로 write back과 함께 사용.
ex) 함수 호출에 앞서 함수 인자들을 스택에 push할 때.
write around(=no write allocation)
메모리로부터 캐시 라인을 캐시에 가져오지 않고 메모리에만 직접 write. 자주 접근 되지 않는 데이터에 적용.
주로 write through 방식과 함께 사용. write through와 write around 모두 메모리에 직접 접근하므로 연속적인 write 작업에는 비효율적임.
ex)I/O buffer에 write할 때.
no write allocation: a write miss does not allocate the block to the cache
Cache mapping
캐시에는 메모리 주소와 해당 메모리 주소의 데이터 존재.
direct mapping
tag, index(line offset), byte offset으로 구성된 32bit 주소값 이용.
index는 캐시 블록의 주소. byte offset은 캐시 라인(캐시 블록) 내에서 데이터 위치.
일반적으로 캐시 블록은 multiple bytes/words 포함.
tag는 같은 index에 해당하는 데이터들을 구분하기 위한 용도.
참고로 1 word 크기는 4bytes(MIPS).
ex) word addr=18인 경우, binary addr= 10 010(18)
index=010, tag=10을 이용해서 접근. 메모리의 Mem[10010] 데이터를 해당 위치에 저장.
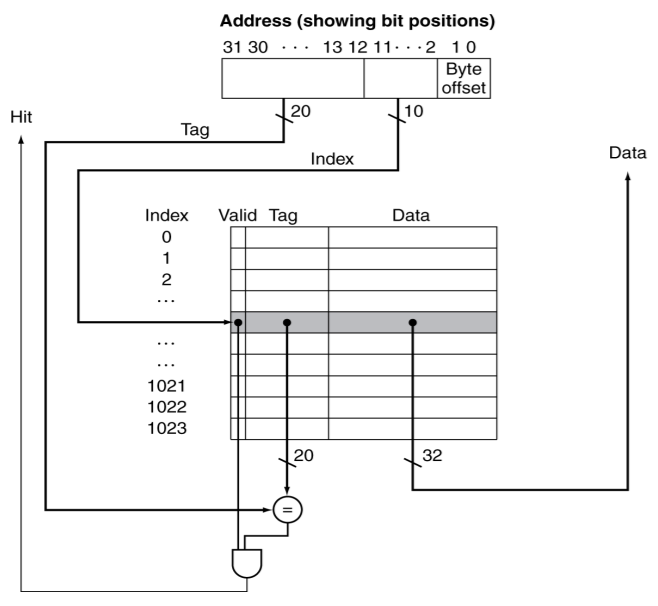
위 그림에서 캐시 블록은 1 word(4bytes)를 포함한다고 가정.
index는 0~1024이므로 10bits.
캐시 블록 내의 데이터 시작 주소를 나타내기 위해 2bits 사용.
나머지 20(32-10-2)bits 찾는 블록이 맞는지 구분하기 위한 tag 비트.
n-way set associative mapping
index 개념을 빼고, set 개념 적용.
각 set은 n개의 entry 보유. tag, set, word offset 이용.
ex) set 개수가 2인 경우, (block number) modulo (캐시의 set 개수=2)에 해당하는 set에 데이터 저장. 데이터 조회 시에 해당하는 set만 탐색.
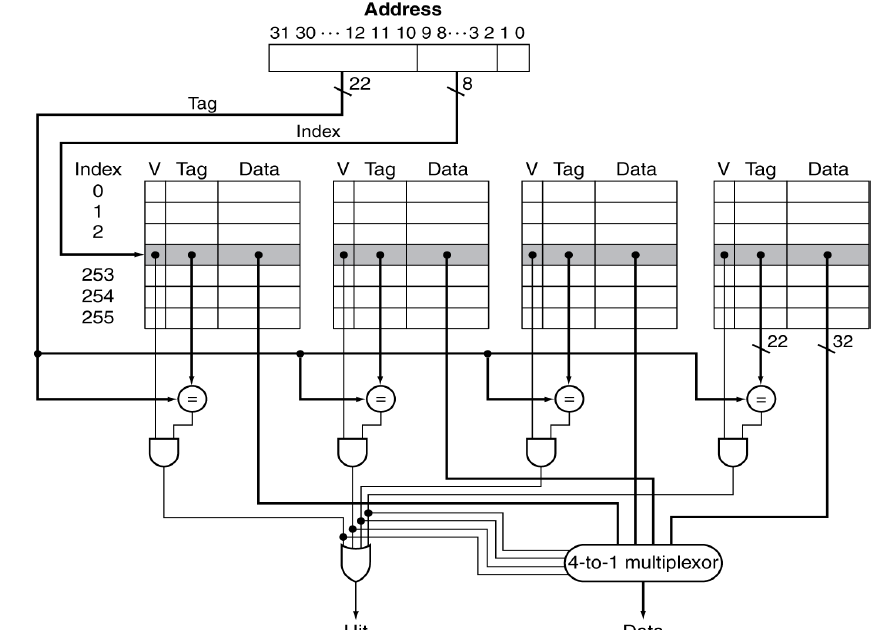
위 이미지는 4-way set에 해당하며 이때 set의 개수는 256이다.
fully associative mapping
block은 cache의 모든 entry에 저장될 수 있음. 단, 데이터 읽기 시 캐시 내의 모든 데이터를 탐색해야함.
Summary

8개의 entry를 각 형식에 맞춰 나타낸 모습.
Average memory access time
AMAT = Hit time + Miss rate * Miss penalty
