23.34m
아직 이분탐색이 낯설어서 그런가?
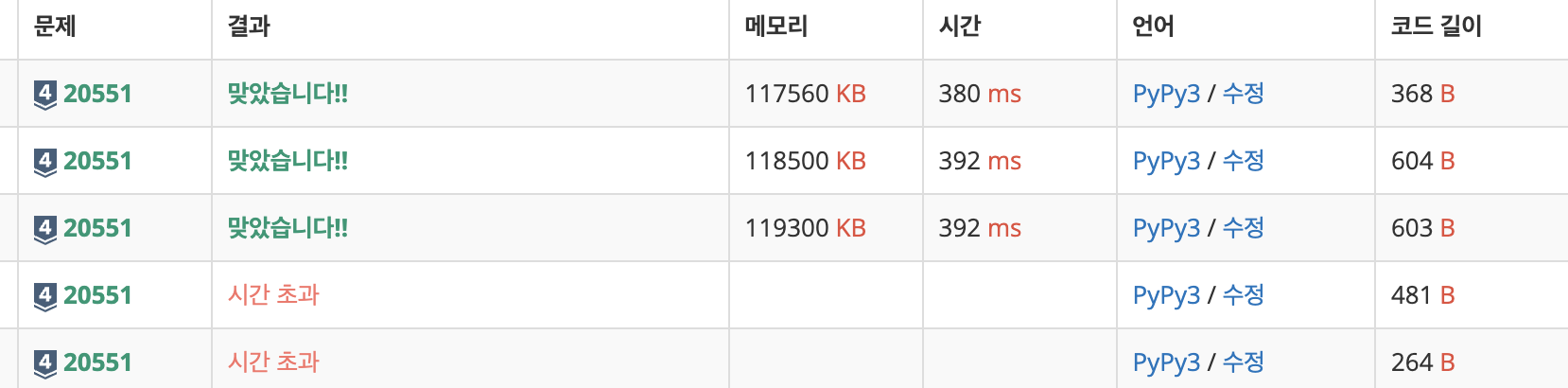
실버4인데도 웬만한 골드문제만큼 어려웠다.
틀린 답 1
틀릴걸 예상했지만 일단 실4니까 될 수도 있지 않을까 하고...
import sys
input = sys.stdin.readline
n, m = list(map(int, input().rstrip().split()))
nums = sorted([int(input().rstrip()) for _ in range(n)])
for d in [int(input().rstrip()) for _ in range(m)]:
try:
print(nums.index(d))
except:
print(-1)거의 브론즈급 문제로 풀어봤는데 당연히 시간초과
틀린 답 2
이번엔 이분탐색을 도입해서 풀었다.
import sys
input = sys.stdin.readline
n, m = list(map(int, input().rstrip().split()))
nums = sorted([int(input().rstrip()) for _ in range(n)])
def bin_search(target):
start = 0
end = n - 1
while start <= end:
mid = (start + end) // 2
if nums[mid] == target:
return mid
elif nums[mid] > target:
end -= 1
else:
start += 1
return -1
for _ in range(m):
print(bin_search(int(input().rstrip())))일단 이렇게 하면 시간초과도 시간초과지만, 가장 앞에있는 원소의 인덱스를 찾아야하는 문제의 의도와 벗어난다.
맞은 답
lower bound를 이용해서 풀었다.
Lower Bound?
이분탐색처럼 정렬된 리스트에
start = 0
end = len(list) - 1
로 두고,
while start <= end
mid = (start + end) // 2
그리고 list[mid] 값과 target을 비교해서 mid의 왼쪽과 오른쪽을 지워내는 형식은 비슷하다.
하지만 lower_bound의 경우 end 인덱스에 타겟이 들어가있어야한다.
즉, 찾고자하는 target의 내가 설정한 영역의 끝에 존재해야만 최초로 등장한 인덱스라고 할 수 있다.
답
import sys
input = sys.stdin.readline
n, m = list(map(int, input().rstrip().split()))
nums = sorted([int(input().rstrip()) for _ in range(n)])
def lower_bound(target):
start = 0
end = n - 1
while start <= end:
mid = (start + end) // 2
if nums[mid] < target:
start = mid + 1
elif nums[mid] > target:
end = mid - 1
elif nums[mid] == target:
if end == mid: break
end = mid
if nums[end] == target:
return end
else:
return -1
for _ in range(m):
print(lower_bound(int(input().rstrip())))Upper bound
문제랑은 관련이 없지만, lower_bound를 봤으니 upper_bound도..!
lower_bound랑 다르게, upper_bound는 내가 찾고자하는 target보다 큰 최초의 값!의 인덱스를 알아내는 방법이다.
응용하면 같은 값을 가지는 원소의 마지막 인덱스를 빠르게 찾을 수 있을 것 같다.
구현
def upper_bound(target):
start = 0
end = n - 1
while start <= end:
mid = (start + end) // 2
if nums[mid] <= target:
start = mid + 1
else:
end = mid - 1
return end여긴 파이썬이다
지금 언어는 파이썬이다
이런거 구현 안하려고 자스에서 넘어온거였다.
그리구 파이썬답게 이분탐색 역시 이미 구현되어있었다.
bisect
파이썬에는 이분탐색을 지원하는 모듈이 있다.
심지어 lower_bound, upper_bound도 지원한다.
그거슨 바로 bisect_left(lower)와 bisect_right(일반 & upper)
해당 모듈로 문제를 다시 풀어보면 아래와 같다.
import sys
from bisect import bisect_left
input = sys.stdin.readline
n, m = list(map(int, input().rstrip().split()))
nums = sorted([int(input().rstrip()) for _ in range(n)])
d = 0
for _ in range(m):
d = int(input().rstrip())
idx = bisect_left(nums, d)
if idx >= n:
print(-1)
elif d == nums[idx]:
print(idx)
else:
print(-1)직접 구현해 쓰는 것보다 성능이 좋다^6.. 왤까?ㅎ