
썸네일 출처 : educative.io
머신러닝 이론이 막바지에 이르러간다.
물론 더 생각나면 재깍재깍 추가하자...
-
Q. 머신러닝에서 Bias 와 Variance 가 무엇이라고 생각하나요?
A. Bias 은 예측값과 정답의 차이의 정도이고 Variance 은 예측값끼리의 차이의 정도입니다. -
Q. 머신러닝에서 Bias 와 Variance 가 어떤 의미를 가진다고 생각하나요?
A. Bias 와 Variance 을 더해 에러를 측정하기 때문에 하나라도 너무 높으면 안 됩니다. 즉 trade off 관계이고, 이를 알아야 모델이 underfit 인지 overfit 인지 알 수 있습니다.
-Q. Bias 와 Variance 가 과적합과 무슨 상관인지 얘기해보세요.
A. Bias 가 높으면 아직 모델이 학습 제대로 안 된 과소적합 상태입니다. Variance 가 높으면 모델이 과하게 학습된 과적합 상태입니다.
Bias and Variance

사실 위의 그림이 전부다.
Error 을 측정할때 Bias 와 Variance 둘을 합쳐 더한다.
이때 Bias 은 수식 그대로 해석하면 된다.
실제의 평균값에서의 차를 더해 제곱한 것
그리고 Variance 은 예측값들의 평균값에서 예측값을 뺀 값의 평균을 제곱한 것.
여기에 의미를 더하자면 Bias 은 Accuracy 의 개념, Variance 은 Precision 의 개념이다. Bias 가 좋으면 실제 답과 유사한 것이고, Variance 가 좋으면 유추한 값들이 서로 큰 차이를 내고 있지 않은 것이다.
예측값과 정답이 가까우면 bias 가 적은 거고, 예측값끼리 가까우면 variance 가 적은 것.
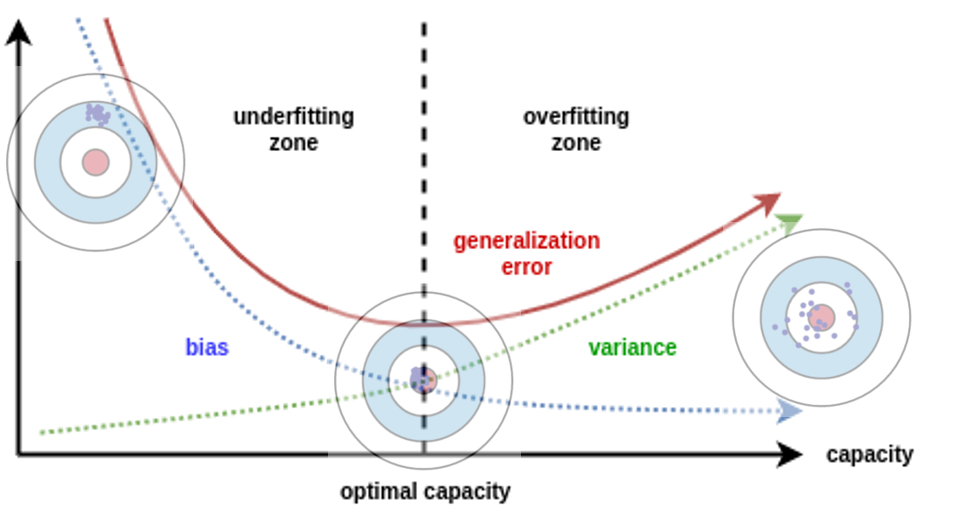
사진 출처:
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
이것이 머신러닝에 중요한 이유는 둘의 trade off 관계를 잘 파악해 모델 학습을 중지시키는 타이밍을 잡아야 하기 때문이다. 위의 그림에서 파악할 수 있듯이 과적합과 과소적합의 문제이다.
Bias 가 높으면 모델 학습이 제대로 되지 않았고 예측값으로는 초기값과 크게 다르지 않은 값들을 낼 것이다. 따라서 variance 은 낮다. 하지만 과소적합이고 모델 학습이 부족한 상태이기 때문에 더 학습을 해야한다.
Variance 가 높으면 모델 학습이 과하게 되었고 예측값들이 서로 너무 다른 것이다. 정답과 유사하겠지만 과적합된 상태이고 새로운 데이터가 들어오면 조금이라도 다르면 예측값이 크게 빗나갈 수 있다. 따라서 이 상태까지 모델을 학습시키면 안 된다.
그 중간 지점인 optimal capacity 를 찾는 것이 좋다. 이 부분이 medium bias 과 medium variety 를 보이며 트레인 세트와 테스트 세트 모두에서 준수한 예측을 낼 수 있다.
정리:
Bias 은 예측값과 정답의 차이 정도, Variance 은 예측값끼리의 차이 정도. 과소적합이 High bias 이고 과적합은 High variance 이다.
< 참고 >
https://gaussian37.github.io/machine-learning-concept-bias_and_variance/
