- updated Aug.17.21: 간결하고 조건문을 없애는 방향으로 코드 정리.
Prologue
CNN을 공부할 때 사람이 사물을 지각하는 방법과 그럭저럭 비슷하게 구현해서 놀랐다. CNN은 Convolution layer, Relu layer, Pooling layer, Fully connected layer로 구성되어 있는데 이 중 Convolution layer만 집중적으로 이야기 해볼 거다.
How we see things
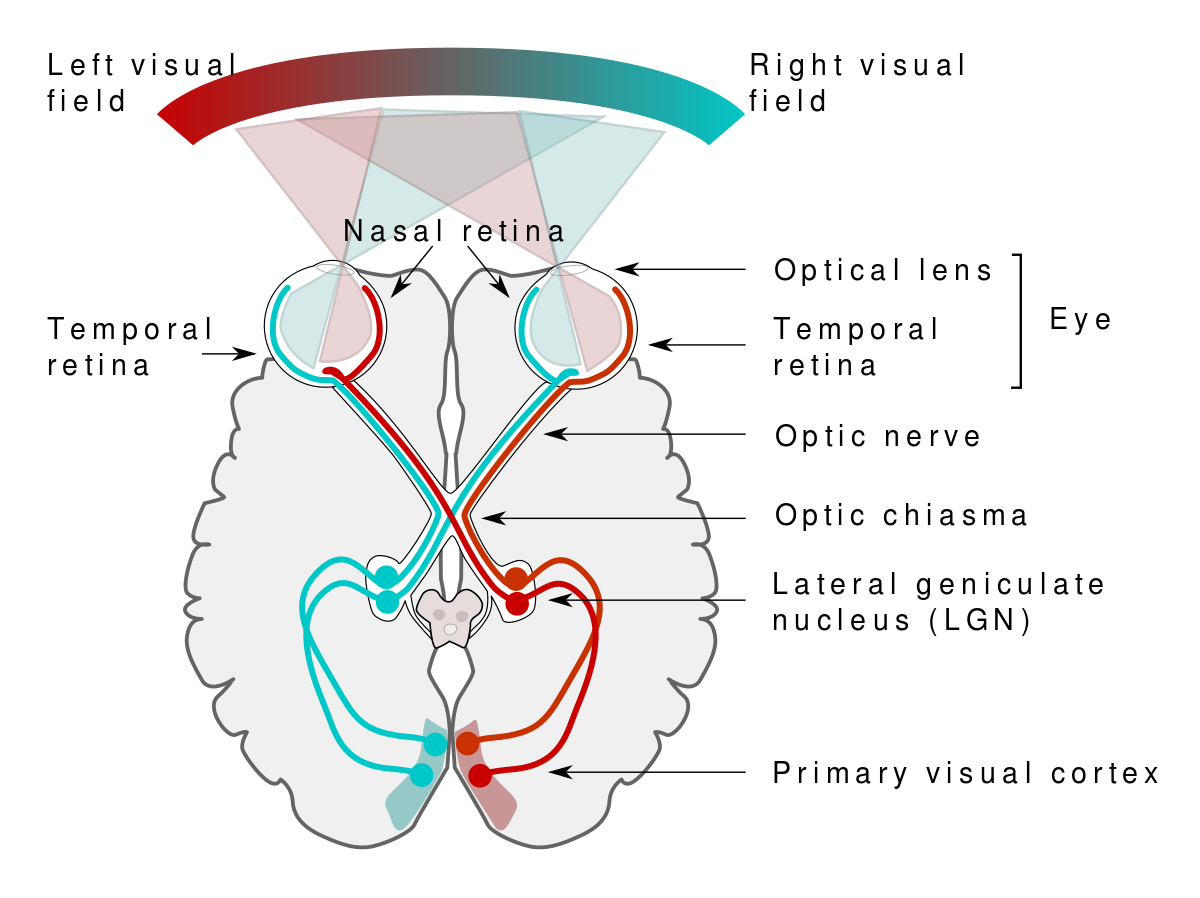
위 이미지에서 보듯이 안구에서 들어오는 시각정보를 시각피질로 보내서 분석한다. 시각피질에는 v1에서 v8에 이르기까지 다양한 정보를 분석하는 영역이 있고 아직 우리는 각 영역이 어떤 일을 더 할 수 있는지 구체적으로 모른다. 다만 밝혀진 사실은 v1 영역에서 점, 선의 시작과 끝점 같은 저차원 정보를 분석해서 v2로 넘기고 v2에서는 선, 선의 기울기를 분석해서 v3로 넘긴다. v8영역에 가까울수록 깊이, 원근감, 전경과 배경의 분리 같은 고차원 정보를 뇌의 전반으로 뿌린다는 점이다. 안구와 시각피질이 하는 역할을 Convolution layer가 한다. 그래서 CNN의 거의 모든 것이라 할 수 있다.
Almost everything of CNN
이렇게 말할 수 있는 이유는 kernel을 가지기 때문이다. kernel은 아래 이미지처럼 이미지 위를 미끄러지듯이 움직이면서 Frobenius product한다. 이렇게 kernel 하나가 한 이미지에 대해 연산이 끝나면 2차원 feature map을 만든다.
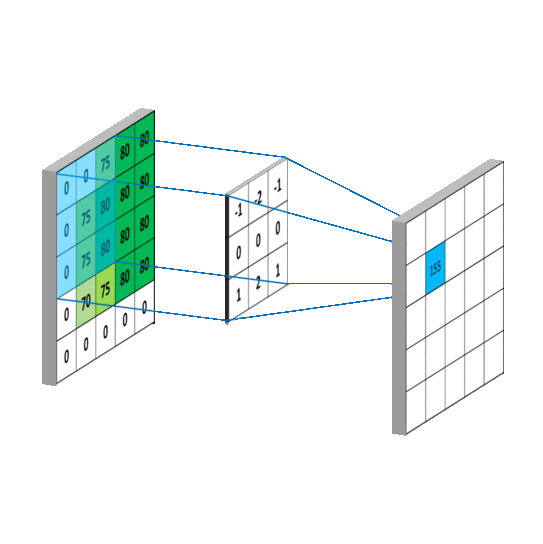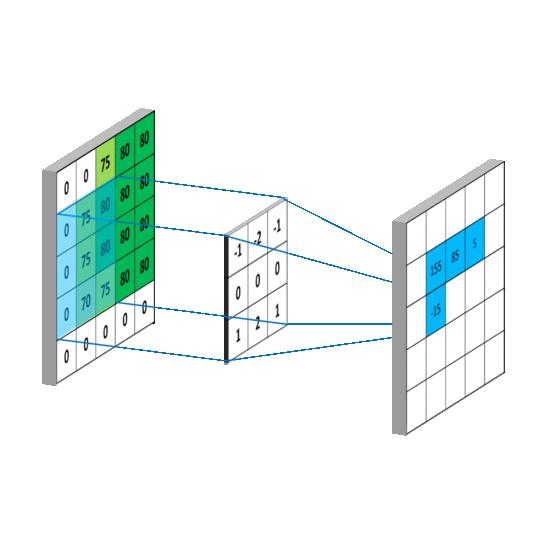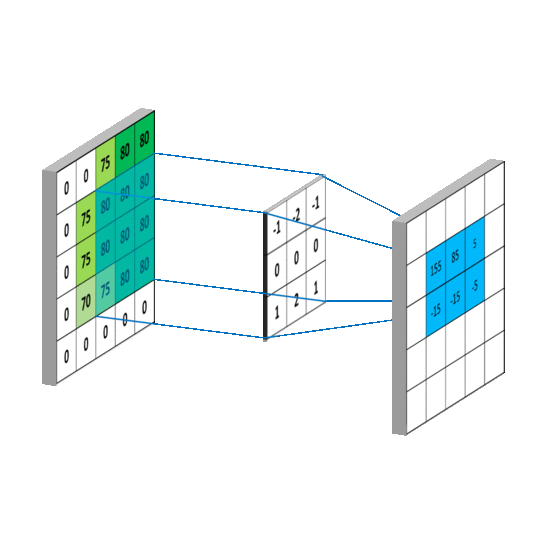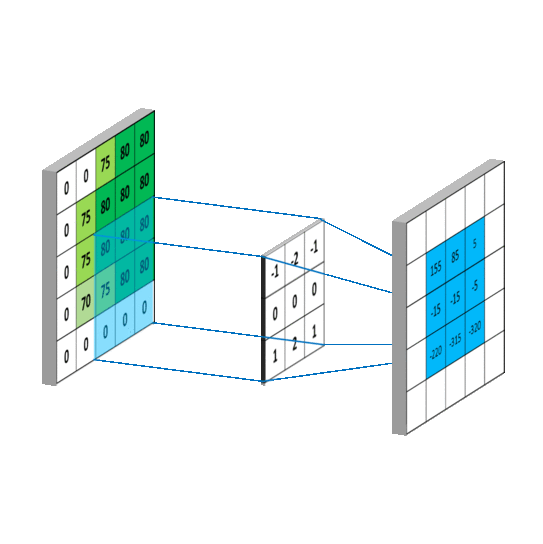
이렇게 연산하는데 가질 수 있는 이점은 2가지다.
- 모델의 복잡도를 줄일 수 있다.
- 공간정보를 유지할 수 있다.
먼저 1번. (32, 32, 3)크기의 이미지 행렬을 FC layer로 학습한다고 해보자. 노드 10개를 가진 히든 레이어 1개짜리 네트웍이라고 해도 대략 3만 개만큼 필요하다. 요즘 인터넷 상에 돌아다니는 이미지는 이 예시보다 적어도 10배는 큰데 이런 이미지를 학습하려면 연산량이 많아서 속도가 느릴 뿐만 아니라 과적합을 맞닥뜨릴 가능성이 크다.
2번. FC layer는 입력단에서 row vector로 늘여뜨려서 학습하는데 이렇게는 공간정보를 유지할 수가 없다.
이런 이유로 kernel이 중요하다.
conv layer를 디자인할 때 kernel과 관련해서 size, channel, depth, stride, padding을 정한다.
- size: kernel의 크기. 기본적으로 정사각형을 많이 쓴다.
- channel: kernel의 채널. 입력 데이터의 채널과 같다.
- depth: kernel의 갯수.
- stride: kernel의 픽셀단위 이동거리. 이미지의 왼쪽 윗모서리부터 오른쪽 아랫모서리까지 차례대로 움직인다.
- padding: 입력 데이터를 그냥 convolve하면 feature map은 쪼그라들고 만다. 그러면 모델을 깊게 쌓을 수 없다. 입력 데이터와 크기를 같게 하고 싶을 때 padding을 적당히 조절해야 한다.
예를 들어 (32, 32, 3)크기의 이미지를 1픽셀 만큼 padding하고 1픽셀 만큼 움직이는 (3, 3, 3)크기의 kernel 10개로 convolve한다고 하면 (32, 32, 10)크기의 feature map이 나온다. 특히 이 예시에서 각각의 feature map이 만큼의 가중치를 가지고 있어서 dense layer에서는 3만여개가 필요했던 것과 비교하면 100배 효율적이다. 즉 각 feature map은 서로 다른 kernel을 사용하고 있으므로 서로 다른 가중치를 가지고 같은 featur map 상에서는 같은 가중치를 공유하고 있다.

Psudo code
이 쯤하면 conv layer에 대해 할 수 있는 말은 다 한 것 같다. 구현하기 전에 psudo code를 작성해볼 거다.
0. kernel size, padding, stride 정해주면
1. 이미지 크기 받아서 변수에 저장(높이, 너비, 채널)
2. feature_map_size: (image - kernel_size + 2 * padding) / stride + 1
if feature_map_size != 정수:
예외처리
3. padding 여부 체크
if padding != 0:
이미지 주위를 padding크기만큼 0으로 둘러싸기.
else:
padded image = 입력이미지
4. 커널(가중치) 초기화
5. 반복(이미지 크기만큼): stride 만큼 도약하면서
an_entry_of_feature_map = 합(이미지 영역 x 커널)Implementation
def test(x, kernel_size: set, strides: set, padding: set) -> None:
'''
args
x: 4 dimention input_tensor (n, h, w, c)
kernel_size: tuple (h, w). it desides size of kernel
strides: tuple (h, w). it moves kernel. h is top to bottom and w is left to right
padding: tuple (h, w) h is padding 0 on upper and bottom side of the image
and w does on right and left side of the image
return
None
'''
_, h, w, _ = x.shape
kh, kw = kernel_size
sh, sw = strides
ph, pw = padding
assert (h - kh + 2 * ph) % sh == 0, 'Hight is not working'
assert (w - kw + 2 * pw) % sw == 0, 'Width is not working'
print('Good to go')
def get_padding(x, padding: set):
'''
args
x: 4 dimention input_tensor (n, h, w, c)
padding: tuple (h, w) h is padding 0 on upper and bottom side of the image
and w does on right and left side of the image
return
4 dimentional ndarray (n, h, w, c)
'''
h, w = padding
print(f'padding height: {h}, padding width: {w}')
return np.pad(x, ((0, 0), (h, h), (w, w), (0, 0)), constant_values=0)
def get_kernel(c, kernel_size: set, filters: int=1):
'''
args
c: channel of input image
kernel_size: tuple (h, w). it desides size of kernel
filters: int. channel of output image
return
4 dimentional ndarray (n, h, w, c)
'''
h, w = kernel_size
print(f'kernel height: {h}, kernel_widht: {w}')
return np.random.randn(filters, h, w, c)
def conv2d(x, filters: int, kernel_size: set, strides: set=(1, 1), padding: set=(0, 0)):
'''
args
x: 4 dimention input_tensor (n, h, w, c)
filters: int. channel of output image
kernel_size: tuple (h, w). it desides size of kernel
strides: tuple (h, w). it moves kernel. h moves it top to bottom and w does left to right
padding: tuple (h, w) h is padding 0 on upper and bottom side of the image
and w does on right and left side of the image
return
4 dimentional ndarray (n, h, w, c)
'''
test(x, kernel_size, strides, padding)
img = get_padding(x, padding)
N, H, W, C = img.shape
kernel = get_kernel(C, kernel_size, filters)
_, kh, kw, _ = kernel.shape
out_h = int((H - kh) / strides[0] + 1)
out_w = int((W - kw) / strides[1] + 1)
out = np.zeros((N, out_h, out_w, filters))
hight = H - kh + 1
width = W - kw + 1
for k in range(len(kernel)):
for n in range(len(img)):
for h in range(0, hight, strides[0]):
for w in range(0, width, strides[1]):
out[n][h][w][k] = np.sum(img[n, h:h+kh, w:w+kw, :] * kernel[k])
return out되긴 되지만 cpu라서 그런가 컴퓨터가 오래되서 그런가 느리다.
Epilogue
코드문으로 보다시피 커널 하나가 4차원 행렬(N, H, W, C)을 채워야 해서 기본적으로 반복문이 4개씩 쓰인다(). 보다 효율적으로 컴퓨팅 리소스를 쓰려고 머리 좋은 사람들이 만들어 놓은 매소드가 im2col인데 이건 다음에 알아보자.
