Prologue
어디선가 '이런 게 있다' 정도만 알았지 실제로 어떻게 구현하고 어디에 쓰이나 생각해본 적이 없다. 그래서 자료구조를 공부하면서 어떻게 쓰일지 생각해보는 겸사겸사 시리즈. 두 번째로 hash table
Problem of linear data structure
대표적인 linear data structure는 array와 linekd list가 있다. 이 자료구조들은 data가 어디에 있는지 모르면 입력, 삭제, 검색하는데 시간복잡도가 이라는 말이다. binary search로 찾아도 시간복잡도는 이다. 일반적으로 백만단위를 훌쩍 넘어가는 데이터를 조회해야 하는데 처리해야 하는 요청이 만단위가 되면 가장 마지막 요청은 그만큼 느리게 처리된다는 의미이다. 이건 심각한 문제다. 논문 검색하는데 결과를 1분만에 볼 수 있으면 그 서비스를 쓰고 싶은 사람들은 없을 거다. 사람들은 로 data에 접근할 수 있는 방법을 원했다.
Hash table
머리 좋은 사람들은 data를 저장할 때 저장하는 순서대로 인덱스를 부여하는 방법 대신 사용자가 인덱스를 부여하는 규칙을 만들면 data에 접근하는데 드는 시간을 로 줄일 수 있겠다고 생각했다. 이 인덱스를 붙이는 규칙을 hashing, hashing으로 생성한 인덱스를 hash value, 여기에 접근하는 입력값은 key, hash value가 가리키는 메모리에 저장된 data를 value라고 부른다.
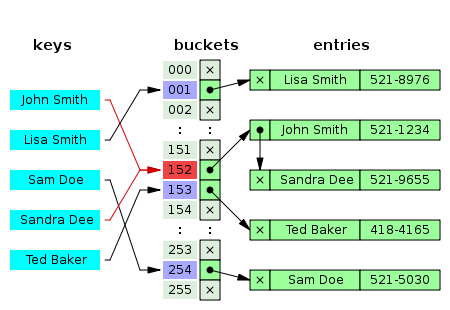
Hashing
앞서 언급한 것처럼 key값을 받아서 hash value를 계산하는 방법이다. 이것을 해주는 함수를 hash function이라고 부른다. hash function을 설계하는데 3가지 조건이 있다.
- 빠른 연산
우리의 목적은 data에 효율적으로 접근하는 구조를 만드는 것이다.hash function에서 실행시간을 까먹을 필요는 없다. - 균등 부여
이렇게 만든hash value는hash table전반에 걸쳐서 부여해야 한다. 몇 가지hash value에data가 몰리면hash table을 쓰는 의미가 없어진다. - 충돌 방지
array나linekd list가 인덱스를 부여하는 것처럼 모든key값을 서로 다른hash value로 부여할 수 없다. 중복을 피하는 적당한 방법을 찾아야 한다.
Implementation
Avoiding collision
먼저 충돌방지를 위해 key, value를 가지는 Data 클래스를 linked list로 감싸서 저장하고 hash value가 같은 data가 들어오면 마지막 Node의 pointer를 새로 들어오는 linked list를 가리키게 할거다.
class Data:
def __init__(self, key, value):
self.key = key
self.value = value
class Node:
def __init__(self, data=None, pointer=None):
self.data = data
self.pointer = pointerHash table
HashTable클래스는 table_size만큼의 공간을 가지고 각 공간에 value를 저장하기로 한다.
class HashTable:
def __init__(self, table_size):
self.table_size = table_size
self.hash_table = [None] * table_sizeHash function
hash function은 내 마음대로 만들었다. key의 모든 문자를 ASCII로 바꿔서 table_size와 나눈 나머지를 더하고 다시 한 번 table_size와 나눈 나머지를 hash value로 쓸 거다. 물론 내 마음대로 만들어서 이건 아주 불완전하고 중복값이 많이 나올 거다.
class HashTable:
... code ...
def get_hash_value(key: str) -> int:
hash_value = 0
for i in key:
hash_value = ord(i) % table_size
hash_value %= table_size
return hash_value
def add_key_value(self, key: str, value) -> cls:
hash_value = self.get_hash_value(key)
if self.hash_table[hash_value] is None:
self.hash_table[hash_value] = Node(Data(key, value), None)
else:
node = self.hash_table[hash_value]
while node.pointer:
node = node.pointer
node.pointer = Node(Data(key, value), None)
Epilogue
-
파이썬에서는
hash table을 따로dictionary자료형으로 제공하고 있다. -
구현하다 보니까 문득 든 생각인데
DB나pandas가 내부적으로 몇 가지hash table을 이어서 구현한 게 아닌가 싶다.
