
해당 포스트는 리브로웍스, 『(명쾌한 설명과 풍부한 그림으로 배우는) TCP/IP: 쉽게, 더 쉽게』, 제이펍(2016)을 참고하여 작성하였습니다.
라우팅과 인터넷 계층
인터넷 계층 의 역할은 송신지 컴퓨터의 데이터를 수신지 컴퓨터까지 전달하는 것이에요. 인터넷에서 수신지 컴퓨터를 정확하게 찾아내기 위해서는 고유 식별자가 필요한데, 이 때 사용되는 식별자가 바로 IP 어드레스 에요.
IP 어드레스 는 우리가 흔히 생각하는 우편번호와는 다르게 지리적인 위치와 상관없이 네트워크 단위로 할당돼요. 따라서 IP 어드레스를 보면 그 컴퓨터가 있는 지역이 아닌, 속해있는 네트워크를 알아 낼 수 있고 소속된 네트워크의 규모도 짐작할 수 있죠.
데이터가 IP 어드레스를 통해 수신지에 전달되기 위해서는 라우터(Router) 라는 네트워크 장비가 필요해요. 라우터는 하나의 네트워크가 또 다른 네트워크와 연결되어 있다는 것과 같이 네트워크 간의 연결 정보를 관리해요. IP 어드레스를 보면 소속된 네트워크가 어디인지 알 수 있는데, 해당 네트워크에 연결된 라우터를 추적해 그 장비가 목표로 한 수신지 컴퓨터를 찾게 되고 송신지에서부터 수신지까지 연결되는 통신 경로를 만들 수 있어요.
단, 앞서 설명했다싶이 IP 어드레스는 지리적인 위치나 거리와 아무런 관련이 없기 때문에, 물리적으로는 가까운 거리에 있어도 네트워크 간의 연결 구조상 통신 경로가 멀리 우회해서 간다거나, 반대로 네트워크 간의 연결 구조는 가까워도 실제로는 되게 멀리 떨어져 있을 수도 있어요.
인터넷 계층의 역할
인터넷 계층 은 네트워크 인터페이스 계층과 협력해서 다른 컴퓨터에게 데이터를 전달해요. 하드웨어와 관련된 부분은 네트워크 인터페이스 계층이 담당하고, 인터넷 계층은 IP 어드레스 라고 하는 식별자 정보를 통해 데이터를 전달할 수 있는 체계를 제공하죠.
데이터가 목적지까지 전달되기 위해서는 라우터 라는 네트워크 장비가 필요해요. 라우터는 네트워크와 네트워크를 연결하는 역할을 하는데, 하나의 라우터가 데이터를 목적지까지 전달하기 위해 다음 네트워크의 경로를 찾으면, 그 경로상에 있는 라우터에게 데이터 전달을 위임하게 돼요. 이 과정이 최종적으로 데이터가 목적지에 전달되기까지 연쇄적으로 반복되는데, 이렇게 라우터가 목적지의 경로를 찾아 나가는 과정을 라우팅(Routing) 이라고 해요.
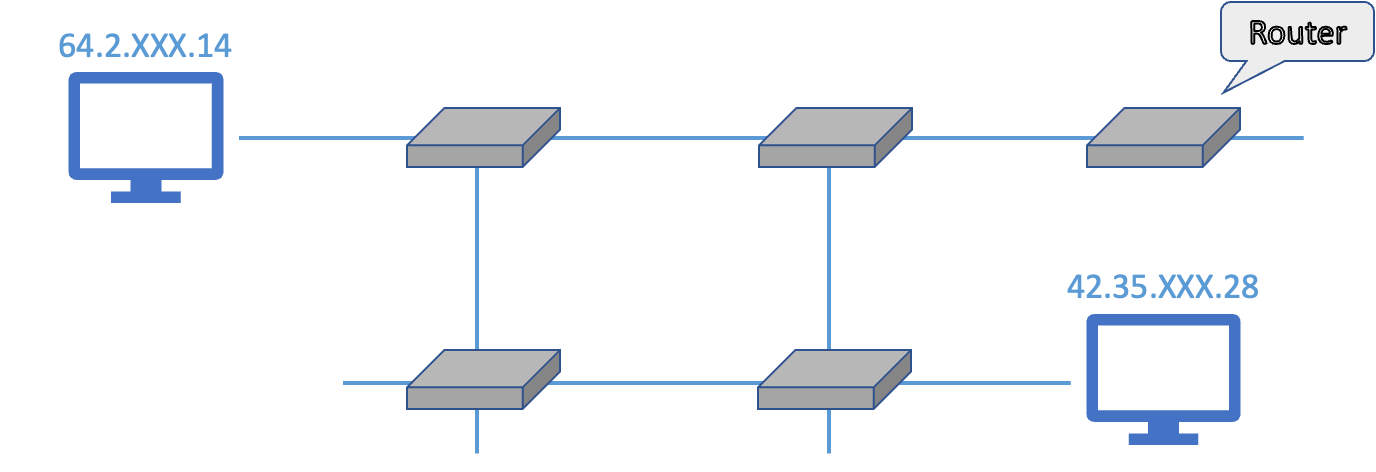
데이터 전송이 시작되면, 라우터는 연결된 여러 다른 라우터들 중 어느 쪽에 데이터를 보내야 목적지에 도달할지 판단해요. 만약 자신이 속한 네트워크에 목적지 컴퓨터가 속해 있다면, 그 컴퓨터에게 데이터를 전달합니다.
IP 어드레스와 관련해서는 관련된 여러 기술들이 있는데요. 인터넷 보급이 확산되면서 사용 가능한 IP 어드레스가 점점 줄어듦에 따라, IP 어드레스 고갈 방안으로 프라이빗 어드레스(Private address) 와 퍼블릭 어드레스(Public address) 를 구분하는 기법을 사용해요. 한편, 근본적인 방법으로는 IPv4 보다 주소 체계가 확장된 IPv6 의 도입이 가속화되고 있죠. 이 외에도 IP 어드레스와 관련된 기술로는 숫자로 된 IP 어드레스를 알아보기 쉽도록 도메인명과 연결해주는 DNS 가 있어요.
IPv4와 IPv6
IPv4(Internet Porotocol Version 4) 는 현재까지 컴퓨터의 어드레스를 지정할 때 가장 많이 사용되는 인터넷 계층의 프로토콜이에요. IPv4는 32비트의 IP 어드레스를 통해 네트워크에 연결된 컴퓨터를 식벽해요. 이 32비트의 문자열은 알아보기 쉽게 8비트 씩 쪼개서 4개의 단위로 끊은 후 0부터 255까지의 10진수로 변환해서 표기하고 있어요.

IPv4 패킷의 IP 헤더(IP Header) 에는 송신지와 수신지의 IP 어드레스 외에도 다른 프로토콜의 헤더들처럼 패킷 길이와 같은 다양한 정보들이 있어요.
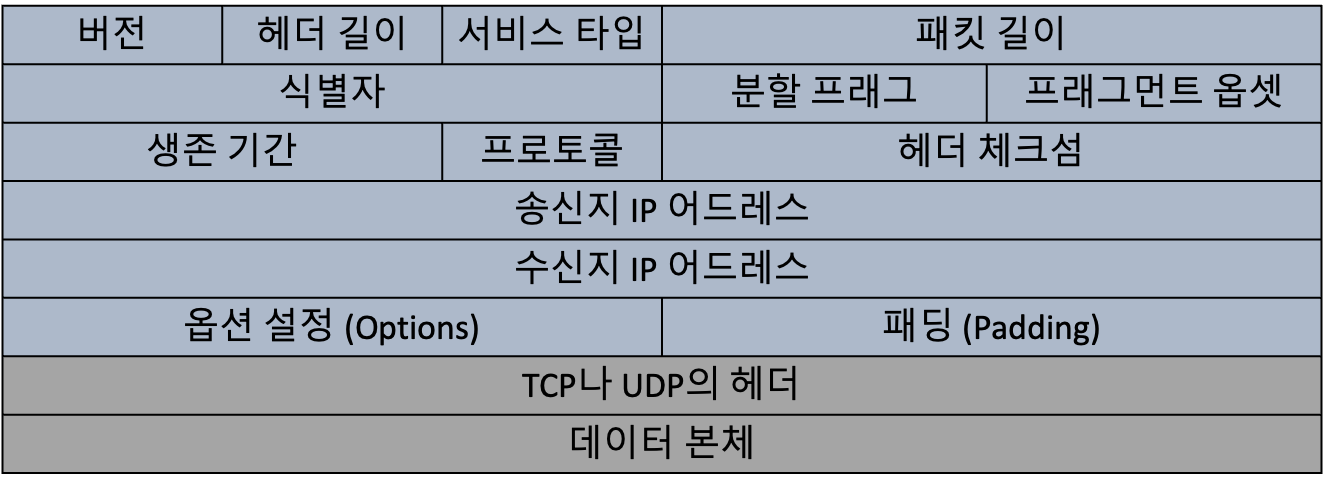
만약 수신지로 지정된 컴퓨터가 실제로 존재하지 않거나 통신 경로를 찾지 못해 패킷이 제대로 전달되지 않았다면,네트워크 안을 계속 떠돌게 되고 그럼 네트워크가 혼잡해지겠죠. 이런 문제를 방지하기 위해 IP 패킷에도 유통기한이란게 있답니다. IPv4 헤더에는 생존 기간(TTL, Time To Live) 을 설정할 수 있고, 만약 생존 기간을 초과한 패킷이 네트워크상에서 발견된다면 그 패킷을 소멸시키도록 규정하고 있어요. 이 TTL은 라우터를 이동할 때마다 길이가 줄어든답니다.
한 번에 전송할 수 있는 데이터 크기를 MTU(Maximum Transmission Unit) 라고 하는데, 이 값은 통신 경로의 상태에 따라 달라져요. 라우터는 경로 상태가 좋지 않으면 이 MTU 값에 따라 패킷을 분할해서 전송하는 기능이 있어요. 하지만 이러한 역할 때문에 라우터의 작업 속도가 느려지거나 패킷 중 일부가 유실될 수도 있는데, 이 때문에 데이터 송신 전에 통신 경로 전체의 MTU를 분석해 처음부터 MTU보다 작은 패킷을 만들도록 설정하기도 해요.
식별자: 같은 데이터인지 식별하기 위한 16비트 숫자 값
분할 플래그: 분할 허가 플래그와 이후 남은 분할 부분이 더 있는지 표시하기 위한 플래그
프래그먼트 옵셋: 원래 데이터에서의 위치 값을 표현하는 13비트 숫자 값
IPv4에서는 위의 헤더 값들을 이용해 분할 처리해요. 같은 데이터에서 나온 패킷들은 같은 식별자를 가지기 때문에 다른 패킷들과 섞여서 전달되어도, 송신 후에 분할된 데이터 조각들은 복원할 수 있죠.
인터넷이 급격하게 성장함에 따라 IPv4의 32비트 어드레스로는 그 수가 모자라기 시작했어요. 때문에 최근들어 128비트 어드레스로 만들어진 IPv6 의 보급이 가속화되고 있죠. IPv6 어드레스의 길이는 128비트이고, 8개의 단위로 분리해 사용하고 있어요.

이미 대부분의 OS나 인터넷 관련 통신 업자들은 이 새로운 버전의 지원 준비를 마쳤어요. 또 기존 IPv4의 생명을 연장할 수 있는 기술들도 개발되고 있어서 당분간은 IPv4 와 IPv6 를 병행해서 사용할 것으로 보입니다.
IPv4와 IPv6 병행 기법
듀얼 스택(Dual stack): 하나의 장비에 두 종류의 어드레스를 할당한 후, 둘 다 사용 가능하도록 한다.
터널링(Tunneling): IPv4 네트워크를 지나갈 때는 IPv4 패킷 안에 IPv6 패킷을 채워서 보낸다.
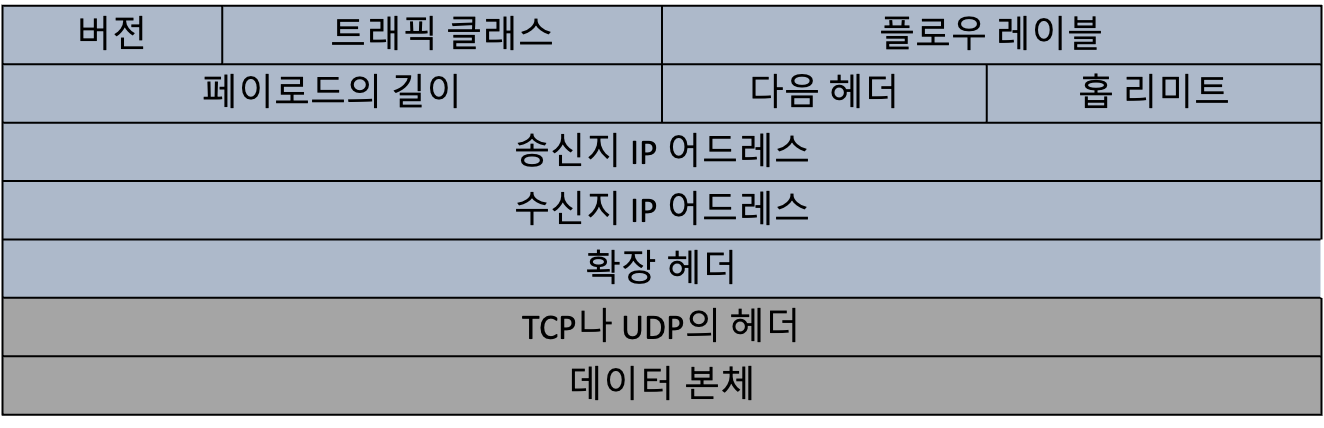
위의 헤더에서 트래픽 클래스, 페이로드 길이, 그리고 홉 리미트는 각각 패킷의 우선순위, 데이터 부분의 길이, 그리고 IPv4의 생존 기간과 같은 역할을 해요. IPv6는 라우터에서 데이터를 분할하지 않기 때문에, 분할 관련된 헤더 필드는 옵션으로 되어있어요. 이 옵션은 확장 헤더에서 지정할 수 있어요.
IP 어드레스의 활용
IP 어드레스는 네트워크 부 와 호스트 부 , 두 가지로 나눠요. 여기서 말하는 호스트는 네트워크에 연결된 컴퓨터 또는 장비를 얘기해요. 라우터는 송신지 IP 어드레스의 네트워크 부를 통해 데이터의 목적지가 네트워크 안에 있는지 아닌지 판단해요.
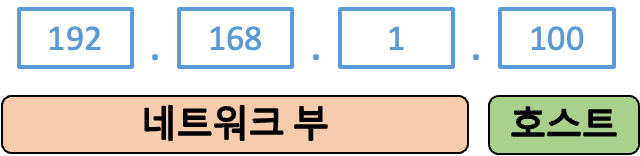
'네트워크'라는 용어는 사실 여러 컴퓨터가 연결되어 데이터를 주고 받을 수 있는 것을 뜻하기에 굉장히 광활한 개념이에요. 하지만 여기서 네트워크 부의 '네트워크'는 'IP 어드레스의 네트워크 부가 같은 컴퓨터들의 그룹' 정도의 좁은 의미로 이해하면 돼요. 그래서 네트워크 부가 다르다는 말은 좁은 의미의 네트워크가 다르다는 의미가 되고, 라우터와 같은 장비를 통하지 않고서는 각 네트워크가 서로 연결되지 않았다고 생각하면 됩니다.
네트워크 부와 호스트 부의 길이는 어드레스 클래스(Address class) 에 따라 그길이가 달라져요. 비트 맨 앞 부분의 배열에 따라 클래스 종류가 구분 돼요. 이 중, 클래스 D는 멀티캐스트로 사용되는 특수한 어드레스에요.
클래스 A: 네트워크 부 8비트, 호스트 부 24비트 ('0' 으로 시작)
클래스 B: 네트워크 부 16비트, 호스트 부 16비트 ('1', '0' 으로 시작)
클래스 C: 네트워크 부 24비트, 호스트 부 8비트 ('1', '1', '0' 으로 시작
클래스 D: 네트워크 부 32비트 ('1', '1', '1', '0' 으로 시작)
클래스 A의 어드레스는 한 개의 네트워크당 약 1677만 대의 호스트 어드레스를 할당할 수 있어요. 그런데 사실 이렇게나 많은 호스트가 하나의 네트워크에 연결될 일은 거의 없기 때문에 어드레스 낭비가 심한 편이죠. 좀 더 효율적으로 어드레스를 할당하기 위해 네트워크를 좀 더 세분화할 수 있는데, 이 때 사용하는 것이 서브넷 마스크 에요.
서브넷 마스크를 사용하면 길이가 정해진 어드레스 클래스를 비트 단위로 유연하게 늘려서 쓰는 것이 가능해요. 네트워크 부를 1비트 단위로 변경할 수 있게 되는거죠. 서브넷 마스크는 IP 어드레스에 추가되는 정보라 32비트 길이만큼의 정보가 더 필요해요.

서브넷 마스크를 사용하면 네트워크를 더 세분화하여 서브 네트워크, 즉 서브넷 을 만 들 수 있어요. 서브넷을 적절히 사용하여 네트워크를 구성하면 부서나 지사, 지역 단위에 맞게 유연하고 효과적인 운영이 가능해요.

하지만 이런 서브넷 마스크에도 한계는 있어요. 서브넷 마스크는 어드레스 클래스에서 미리 정해진 네트워크 부의 길이를 더 늘일 수는 있지만 줄일 수는 없어요. 그래서 호스트 길이가 짧게 만들어진 클래스 C와 같은 경우, 남은 8비트 내에서 서브넷 부와 호스트 부로 나누게 되기에, 실제로 할당할 수 있는 호스트 대수는 급격히 줄어들어요. 때문에 호스트 부가 긴 클래스 A나 B의 어드레스를 세분화할 때, 서브넷을 도입하는 것이 일반적이에요.
IP 어드레스는 사용 범위에 따라 프라이빗 IP 어드레스와 퍼블릭 IP 어드레스로 나뉘어요. 프라이빗 IP 어드레스 는 가정이나 사내에서 자유롭게 사용할 수 있는 어드레스에요. 인터넷이나 다른 네트워크에 연결되지 않기 때문에, 주소가 충돌하지만 않으면 다른 네트워크에서 사용 중인 어드레스를 사용할 수도 있어요. 다만, 프라이빗 IP 어드레스는 인터넷에 연결되어도 접근이 안되기에 NAT(Network Address Translation) 와 같은 어드레스 변환 기술을 사용해 퍼블릭 IP 어드레스로 변환해줘야돼요.
프라이빗 IP 어드레스로 사용 가능한 범위
클래스 A: 10.0.0.0 ~ 10.255.255.255
클래스 B: 172.16.0.0 ~ 172.31.255.255
클래스 C: 192.168.0.0 ~ 192.168.255.255
퍼블릭 IP 어드레스 는 인터넷 안에서 중복되면 안 되기 때문에 ICANN(Internet Corporation for Assigned Names ans Numbers)이나 KRNIC(Korea Network Information Center)와 같은 단체가 관리하고 있어요. 때문에 퍼블릭 IP 어드레스가 필요하면 각 단체에 신청을 해서 할당 받으면 돼요. 이 퍼블릭 IP는 인터넷 레지스트리를 통해 인터넷 서비스 제공자들에게 할당되고 기업이나 가정은 인터넷 서비스 제공자가 확보한 IP 어드레스를 빌려 쓰면 돼요.
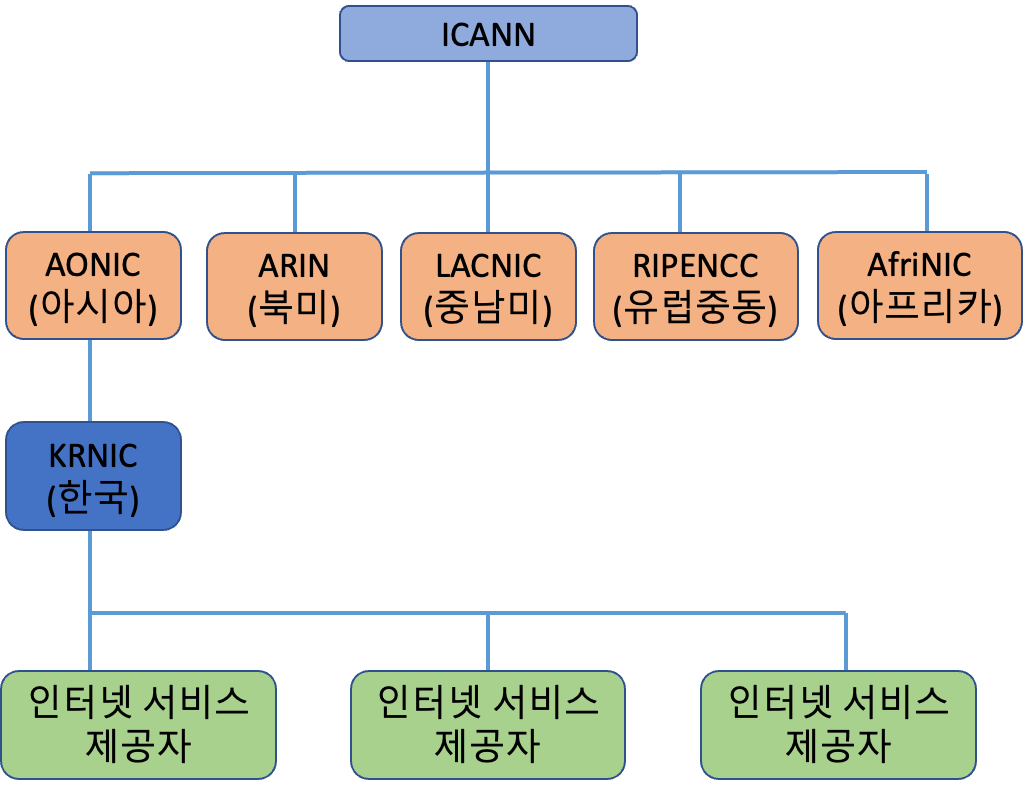
라우팅이란?
인터넷에서 데이터가 목적지가지 제대로 도착하려면 라우터가 자신과 연결된 다른 라우터를 찾아나가면서 목적지까지 연결된 경로를 찾을 수 있어야 돼요. 이런 과정을 라우팅(Routing) 이라고 하고, 이 때 찾은 최적의 경로를 사용해 통신을 하게 돼요. 만약 통신 경로 상에서 문제가 생긴다면 차선책의 경로를 이용해 통신을 재개해요.
이런 통신 견로를 찾기 위해서는 네트워크상의 각 라우터가 어떤 다른 라우터와 연결되어있는지에 대한 정보를 알아야 해요. 이 때 라우팅 프로토콜이 사용돼요. 라우팅 프로토콜의 대표적인 예는 BGP, OSPF, RIP 등이 있어요.
인터넷 서비스 제공자가 사용하는 큰 규모의 네트워크에서는 몇 가지 네트워크를 하나로 묶은 자율 시스켐(AS, Automnomous System) 이라는 단위로 관리해요. AS를 이용하면 네트워크상의 경로를 하나하나 묶어 다니면서 이동하지 않고, 큰 덩어리의 AS의 접속 경로 단위로 이동하기 때문에 멀리 있는 컴퓨터와도 훨씬 빠른 속도로 통신할 수 있어요.

라우터와 라우팅 프로토콜
라우터 의 역할은 네트워크 간의 패킷을 전달하는 것이에요. 라우터가 연결하고 있는 각 네트워크에서 사용하는 IP 어드레스는 각각 하나씩 필요해요. 그렇기 때문에 연결한 네트워크 개수만큼의 IP 어드레스를 가지게 되죠.
이 때, 목적지로 가기 위한 경로는 라우터 내부에 저장하고 있는 라우팅 테이블 을 보고 판단해요. 라우팅 테이블에는 목적지 호스트가 속한 네트워크 정보와 그 네트워크로 도달하기 위해 경유해야 하는 라우터의 정보가 들어있어요.
정적 라우팅: 네트워크 관리자가 직접 수작업으로 라우팅 테이블을 설정하는 방식
동적 라우팅: 라우팅 프로토콜을 사용하여 자동적으로 경로 정보를 수집한 후 라우팅 테이블을 설정하는 방식
대부분의 경우 일일히 정적 라우팅을 설정하는 것이 까다롭기 때문에, 동적 라우팅을 이용해요.
만약 라우팅 테이블에 목적지 정보가 없다면, 더 많은 정보를 지닌 기본 라우터 혹은 디폴트 라우터 에게 물어보게 돼요. 이 디폴트 라우터 정보는 각 라우터마다 정적으로 설정되어 있답니다.
동적 라우팅 알고리즘
거리 벡터형: RIP(Rrouting Information Protocol) 프로토콜이 사용하는 방식으로, 목적지까지의 거리를 살펴보고 짧은 경로를 선택하는 방식이다. 이 때 거리는 경유하는 라우터의 수(홉, Hop)의 수로 센다. 비교적 구성이 간단한 LAN 네트워크에 적합하다.
링크 상태형: OSPF(Open Shortest Path First) 프로토콜이 사용하는 방식으로 네트워크의 통신 상태 정보를 맵으로 관리하면서 상태가 가장 좋은 경로를 선택하는 방식이다. 복잡하고 변화가 잦은 네트워크에 적합하다.
이들 위에 자율 시스템 AS 간의 통신에서 사용되는 경로 벡터형 알고리즘도 있어요.
AS 안에서는 주로 링크 상태형인 OSPF 를 사용해요. 다만, 링크 상태형은 네트워크 규모가 커지면 맵 정보를 처리하는 부하가 커지기 때문에, 네트워크를 몇 개의 영역으로 분할해서 각 영역별로 맵을 따로 만드는 방식을 사용해요.
AS끼리는 경로 벡터형인 BGP(Border Gateway Protocol) 가 사용돼요. 경로 벡터형은 거리 뿐만 아니라 경로 도중에 경유하는 AS 정보까지 포함해서 경로 정보를 만들어요.
네트워크 오류를 통보하는 ICMP
ICMP(Internet Control Message Protocol) 프로토콜은 데이터 전송 중에 문제가 생기면 장애 상황을 통보하기 위해 사용돼요. ICMP 프로토콜은 상항에 따라서 다른 타입의 메시지를 사용해요. 그럼 송신 측에서 이 메시지를 보고 어떠한 처리를 해야할지 파악하죠.
타입 0: 에코 응답. 수신 측 장비가 존재한다고 확인해 줄 때 사용한다.
타입 3: 데이터가 도착하지 않았다.
타입 4: 회선 상태가 혼잡하다.
타입 5: 경로 상태가 최적이 아니다.
타입 8: 에코 요청. 수신 측 장비가 존재하는지 확인할 때 사용한다.
타입 9: 라우터가 보내는 응답으로, 네트워크에 새로 연결된 장비에게 사용 가능한 라우터 정보를 알려주기 위해 사용한다. (Router Advertisement)
타입 10: 장비가 보내는 요청으로, 네트워크에 새로 연결되었을 때 라우터를 찾기 위해 사용한다. (Router Solicitation)
타입 11: 생존 기간이 지난 패킷을 삭제했음을 알려 준다.
ICMP 패킷은 IP 헤더에 타입이나 코드와 같은 ICMP 메시지를 덧붙인 형태에요.

어드레스 변환
앞서 네트워크 어드레스 변환(NAT) 기술을 통해 프라이빗 IP 어드레스와 퍼블릭 IP 어드레스 간의 변환을 가능하게 해준다고 했죠. 이 NAT 기술은 이 외에도 IPv4와 IPv6간의 변환에도 응용돼요.
데이터를 송신할 때는, 송신지의 프라이빗 IP 어드레스를 라우터의 퍼블릭 IP 어드레스로 바꿔 보내요. 마찬가지로 수신할 때는 라우터의 퍼블릭 IP 어드레스를 송신지의 프라이빗 IP 어드레스로 바꿔 보내죠.
하지만 NAT는 단순히 IP 어드레스를 변환할 뿐이기 때문에 몇몇 상황에서는 제약이 생길 수도 있어요. 만약 내부의 여러 호스트가 같은 포트 번호를 사용한다면, 라우터는 요청에 대한 응답을 어느 호스트에 보내야하는지 포트 번호만 가지고는 판단하지 못해요. 또, 외부에서 일방적으로 보내는 데이터는 NAT 범위 안에 있는 호스트로 전달되지도 않죠.
이와 같이 NAT의 포트 번호 충돌을 막기 위해 만들어진게 네트워크 어드레스 포트 변환(NAPT, Network Address Port Translation) 방식이에요. 이는 IP 어드레스와 프토 번호를 함께 변환시키죠. NAPT를 이용하면, 내부 네트워크에서 같은 포트 번호를 사용하는 여러 호스트들을 외부와 통신할 때 포트 번호가 충돌되지 않도록 변환해주죠. 이러면 각 호스트를 구별할 수 있게 돼요.
또 앞서 언급한 사용자의 요청 없이 외부에서 일방적으로 들어오는 요청을 받는 방법도 몇 가지 있어요.
메시지의 자동 확인: SNS 등에서는 자동으로 메시지 도착 알림이 되는데, 이러한 서비스는 대부분 내부에서 메시지 도착 여부를 정기적으로 확인 요청하는 방법으로 구현됩니다.
포트 포워딩: 라우터의 특정 포트 번호로 통신이 들어오면 내부의 특정 서버에 전달되도록 설정할 수 있다. LAN 안에 웹 서버나 FTP 서버를 운영하면서 외부로 이 서비스를 공개해야 할 때 사용한다.
도메인명
DNS(Domain Name System) 와 도메인명 은 서로 다른 컴퓨터를 구분하는 식별자인 IP 어드레스와 호스트명을 관리하기 위해 만들어졌어요. 사전에 컴퓨터나 라우터에 DNS 서버의 IP 어드레스가 등록되어 있다면, 도메인명에 대응하는 IP 어드레스 정보를 DNS 서버에 물어볼 수 있죠.
도메인명은 계층 구조 형태를 마침표로 구분하여 표현해요. 가장 뒤에 오는 'com'이나 'org'와 같은 도메인이 상위 도메인이고, 최상위 도메인 혹은 탑 레벨 도메인이라고도 불러요. 그 밑의 도메인은 2단계 도메인 혹은 서브 도메인이라고 불리죠.
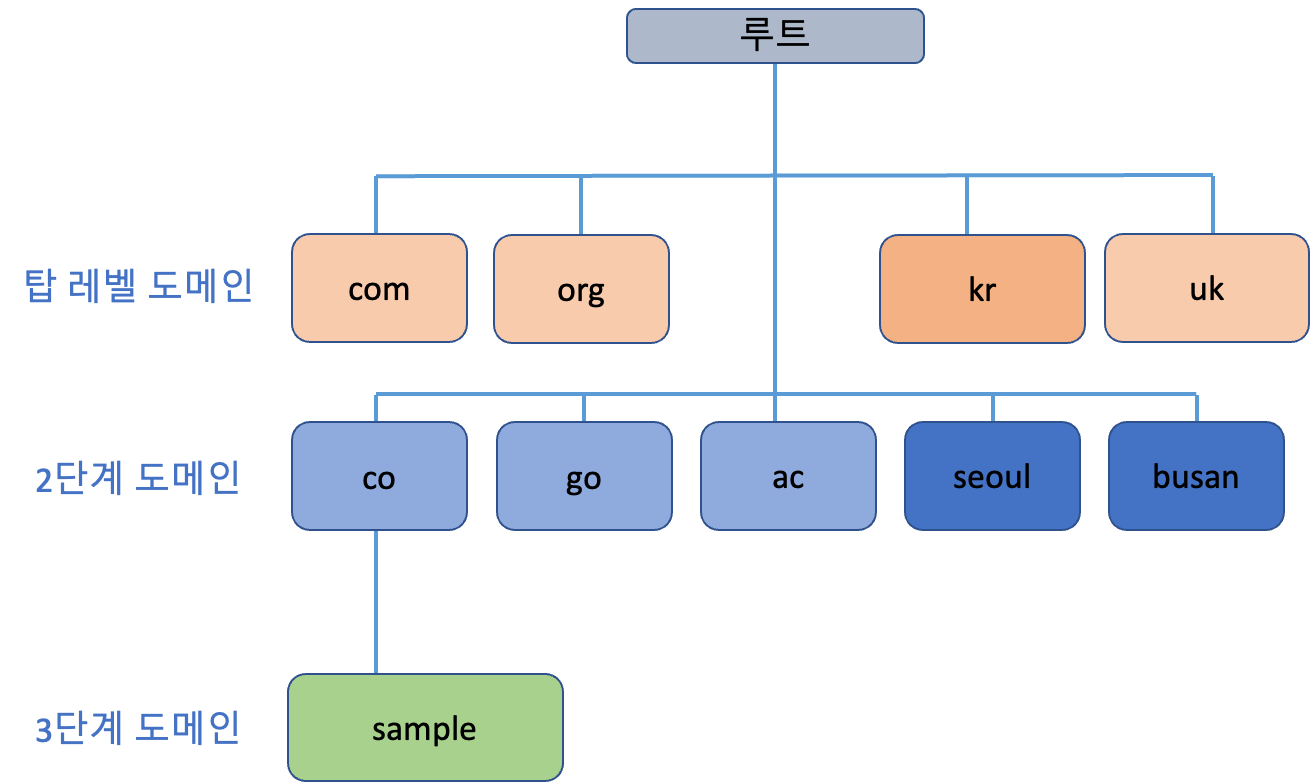
DNS 서버는 자신이 담당하는 영역에 대한 도메인명을 관리하게 되는데, 이렇게 도메인명을 직접 관리하는 서버를 DNS 콘텐츠 서버 라고 불러요. 각 DNS 서버는 도메인 계층 중 일부 영역을 담당하고 그 영역에 속한 도메인명을 관리하죠.
DNS 서버는 크게 도메인명을 관리하는 콘텐츠 서버(Content server)와 질의에 응답하기 위한 캐시 서버(Caching server)로 나뉘어요. 도메인 캐시 서버 는 루트 네임 서버부터 순차적으로 질의하게 되고, IP 어드레스를 찾아 응답해요. 한번 질의한 내용은 캐시로 보관되기 때문에, 이후 질의가 같다면 콘텐츠 서버까지 가지 않고 바로 IP 어드레스를 알려줘요.
도메인명은 ICANN에서 관리하기 때문에, 사용하고 싶은 도메인이 있다면 등록 기관에 신청해야만 인터넷에서 사용할 수 있어요. 도메인을 DNS 서버에 등록하게 되면, 그 정보를 리소스 레코드(Resource record) 라고 부르며 리소스 레코드가 등록된 파일을 존 파일(Zone file) 이라고 부르게 됩니다.
SOA 레코드: 해당 도메인명을 관리하는 DNS 서버를 기술함
NS 레코드: 프라이머리(Primary), 세컨더리(Secondary) DNS 서버를 기술함
A 레코드: 호스트명과 IP 어드레스를 연결함
CNAME 레코드: A 레코드에서 지정된 호스트에 별명을 부여함
MX 레코드: XXX@도메인명과 같은 형식의 메일 어드레스와 메일 서버를 연결함
IP 어드레스를 자동으로 할당하는 DHCP
TCP/IP가 제대로 동작하기 위해서는 네트워크에 속한 각 호스트의 IP 어드레스가 중복되지 않아야 해요.하지만 이를 중복되지 않게 관리하는 작업을 사람이 직접 하면 상당히 번거롭고 힘들겠죠. 이것을 자동으로 해주는게 DHCP(Dynamic Host Configuration Protocol) 이에요. 이 방식을 통해 호스트가 네트워크에 연결되면 IP 어드레스와 서브넷 마스크 등의 정보가 자동으로 설정돼요.
네트워크에 호스트가 처음 연결되면 IP 어드레스를 할당받지 못 한 상태이기에 특정 호스트와 통신하는 것은 사실상 불가능해요. 그래서 신규 호스트는 네트워크의 모든 호스트에게 브로드캐스트 방식으로 DHCP 발견 메시지를 보내요. 그럼 DHCP 서버가 자동으로 사용 가능한 IP 어드레스를 할당해준답니다.
ipconfig 명령과 ping 명령
ipconfig 명령을 사용하면 컴퓨터에 할당된 IP 어드레스나 서브넷 마스크 같은 정보를 확인할 수 있어요. (맥OS나 리눅스에서는 ifconfig 를 사용합니다.)
$ ifconfig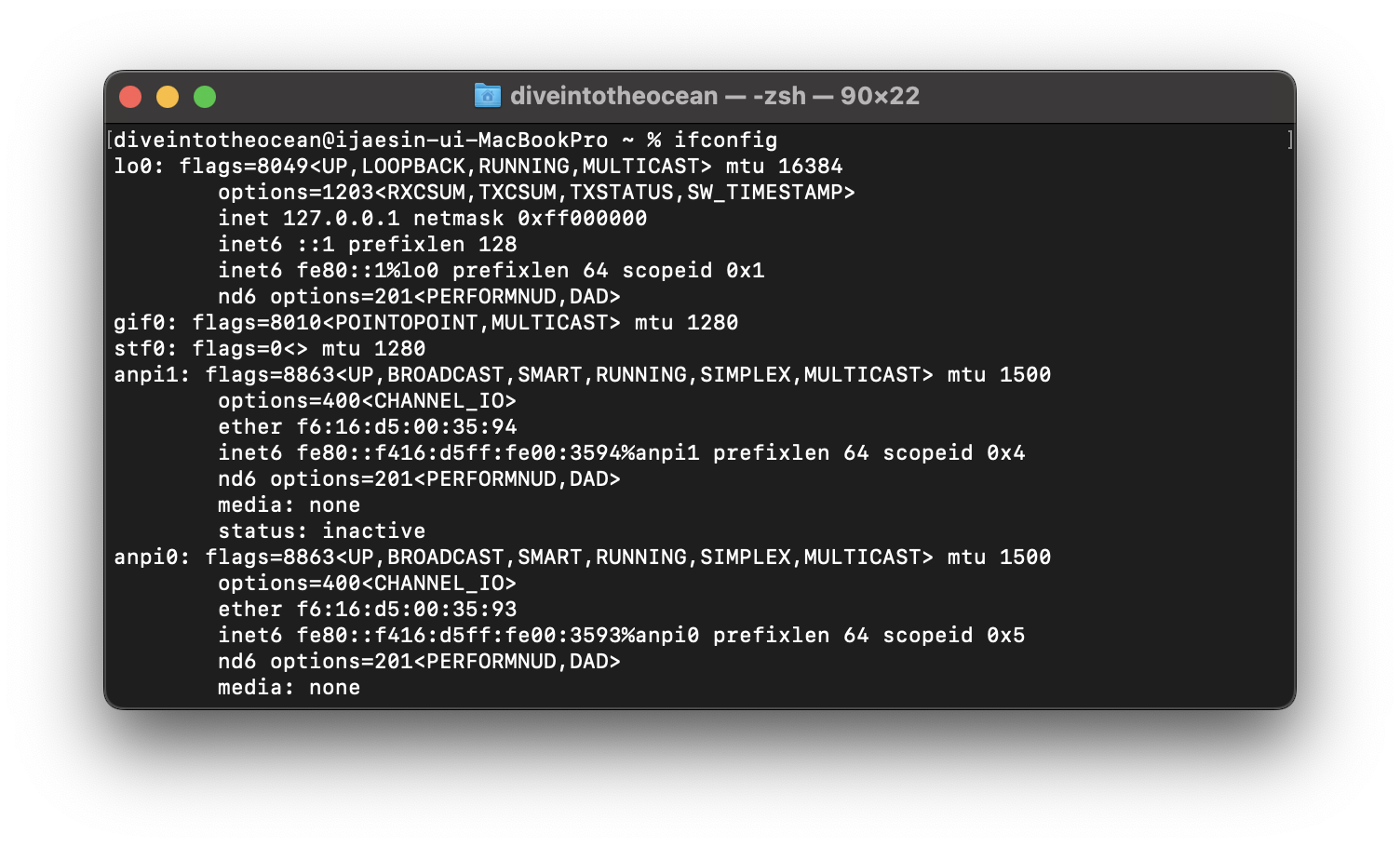
ping 은 지정한 IP 어드레스로 ICMP 타입 8번 메시지를 보내는 명령이에요. 이는 에코를 요청하는 것으로, 송신자가 수신자에게 메시지를 보낸 후 수신자가 자신이 받은 메시지를 다시 송신자에게 되돌려 보내라는 의미에요. 그리고 에코 용청을 받은 수신자는 에코 응답인 ICMP 타입 0번 메시지를 보내죠. 이렇게 에코 요청과 응답이 오가면 상대방이 통신 가능한 상태라는 것을 확인할 수 있어요.
tracert 명령으로 통신 경로 확인하기
인터넷에서는 라우터와 라우터의 연결을 따라 데이터가 전달되는데, 그 경로를 표시할 수 있는 것이 tracert 명령이에요. tracert 명령을 실행하려면 'tracert 도메인명' 혹은 'tracert IP 어드레스'와 같이 입력하면 돼요. (맥OS나 리눅스에서는 1traceroute1 를 사용합니다.)
$ traceroute www.google.co.kr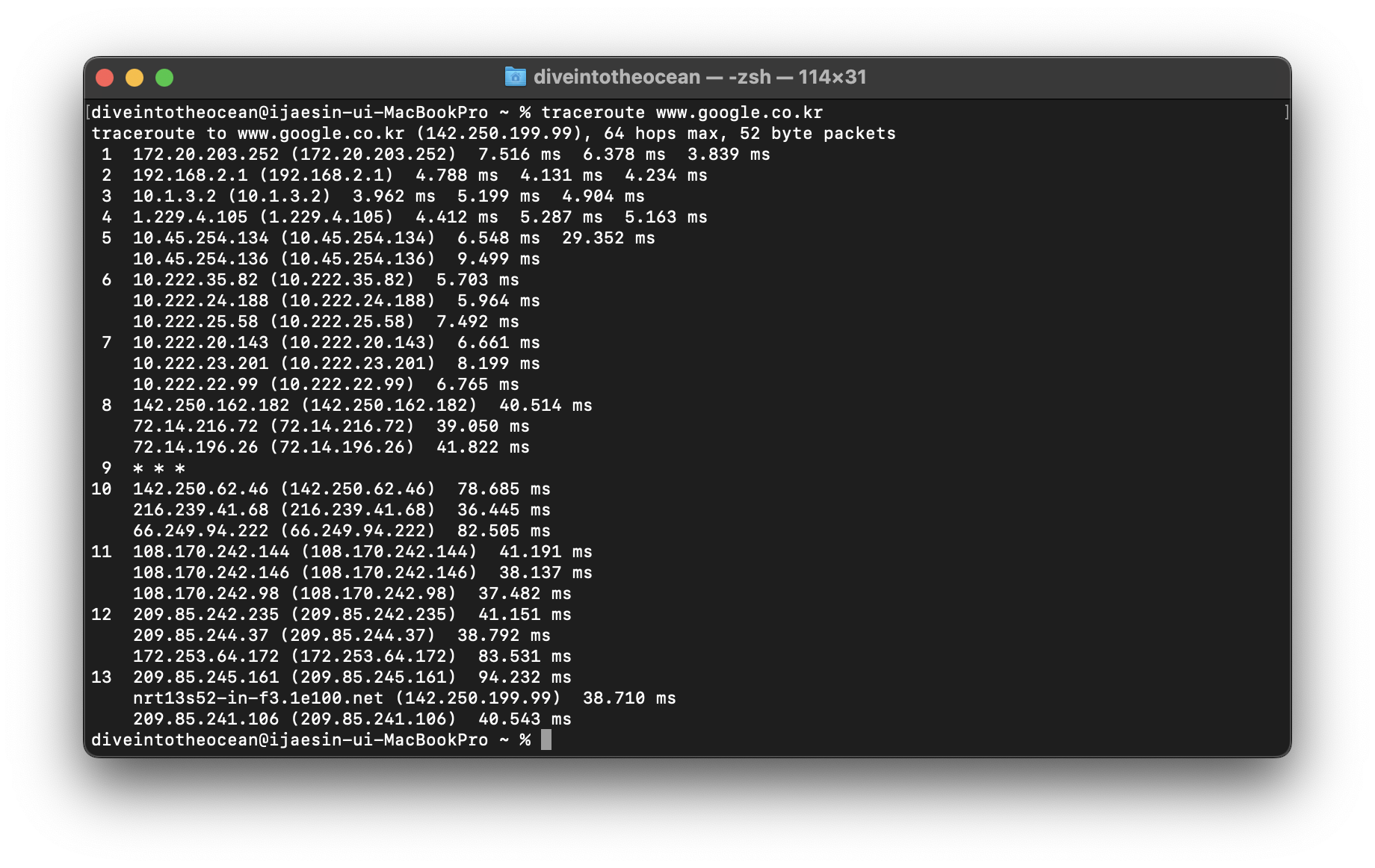
nslookup 명령으로 IP 어드레스 알아내기
DNS 서버에게 IP 어드레스를 물어보는 작업은 1nslookup1 명령을 통해 실행 가능해요. nslookup 명령을 실행하려면 'nslookup 도메인명' 형태로 입력하면 돼요.
$ nslookup www.google.co.kr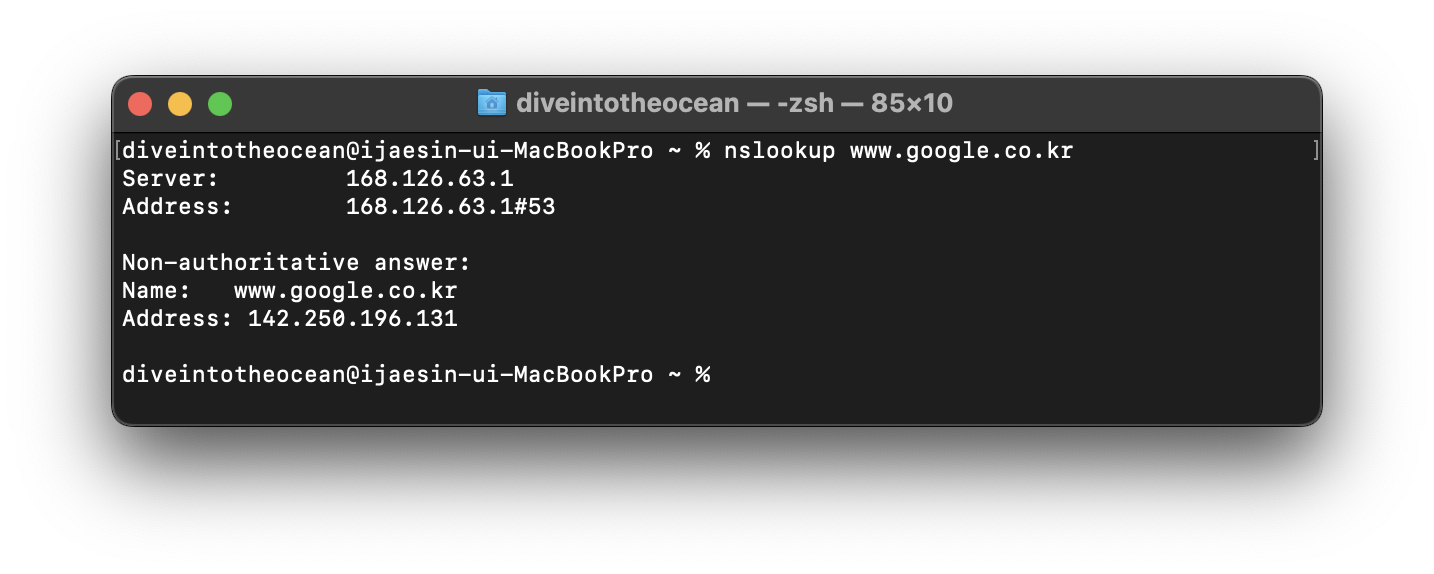
위와 같은 방법을 정방향 조회라고 해요. 반대로 IP 어드레스를 주고 도메인명을 알아낼 수도 있으며, 이를 역방향 조회라고 불러요. 역방향 조회는 'nslookup IP 어드레스'를 입력하면 된답니다.
하드웨어와 네트워크 인터페이스 계층
네트워크 인터페이스 계층 은 TCP/IP 계층 모델 중 가장 아래에 있어요. 간혹 네트워크 어댑터와 같이 하드웨어와 맞닿은 부분 혹은 하드웨어까지 포함하기도 해요. 네트워크 인터페이스 계층은 LAN과 같은 하드웨어들을 제어하면서 인접한 다른 통신 기기까지 데이터를 전달하는 역할을 해요.
네트워크 인터페이스 계층은 인접한 기기까지만 데이터를 전달하는데 집중하도록 만들어졌어요. 이후 최종 목적지까지 데이터가 도달하도록 하는 역할은 인터넷 계층이 할 일이죠.
네트워크 인터페이스 계층의 역할
네트워크 인터페이스 계층 은 네트워크의 하드웨어(네트워크 어댑터, LAN 케이블, 광 케이블 등)를 제어하는 부분이에요. 이는 상위의 계층들이 하드웨어 동작에 신경쓰지 않고 동작할 수 있도록 해주죠. OCI 참조 모델에서는 프로토콜과 같이 소프트웨어와 관련된 부분을 데이터 링크 계층, 하드웨어와 관련된 부분을 물리 계층이라고 표현하기도 해요.
네트워크 인터페이스 계층의 프로토콜 중에는 전화 회선을 통해 원격지와 접속하는 PPP , 동축 케이블 또는 UTP 케이블을 사용하는 이더넷 , 그리고 IP 어드레스 정보를 이용하여 목적지의 MAC 어드레스 를 알아내는 ARP 프로토콜 등이 있어요.
MAC 어드레스
네트워크 어댑터에는 MAC(Media Access Control) 어드레스 라 부르는 식별 번호가 부여되어 있어요. 이 번호는 제조 단계부터 붙여지는 것으로, 전 세계의 네트워크 장비들이 서로 구분될 수 있도록 할당돼요. MAC 어드레스는 제조사 식별 번호 24비트와 제조사에서 정의한 식별 번호 24비트로 이루어져 있고, 16진수 12글자로 표기돼요.
네트워크 인터페이스 계층이 보내는 데이터를 프레임(Frame) 이라고 부르는데, 이 프레임 안에 송신지와 수신지의 MAC 어드레스 정보가 들어가요.
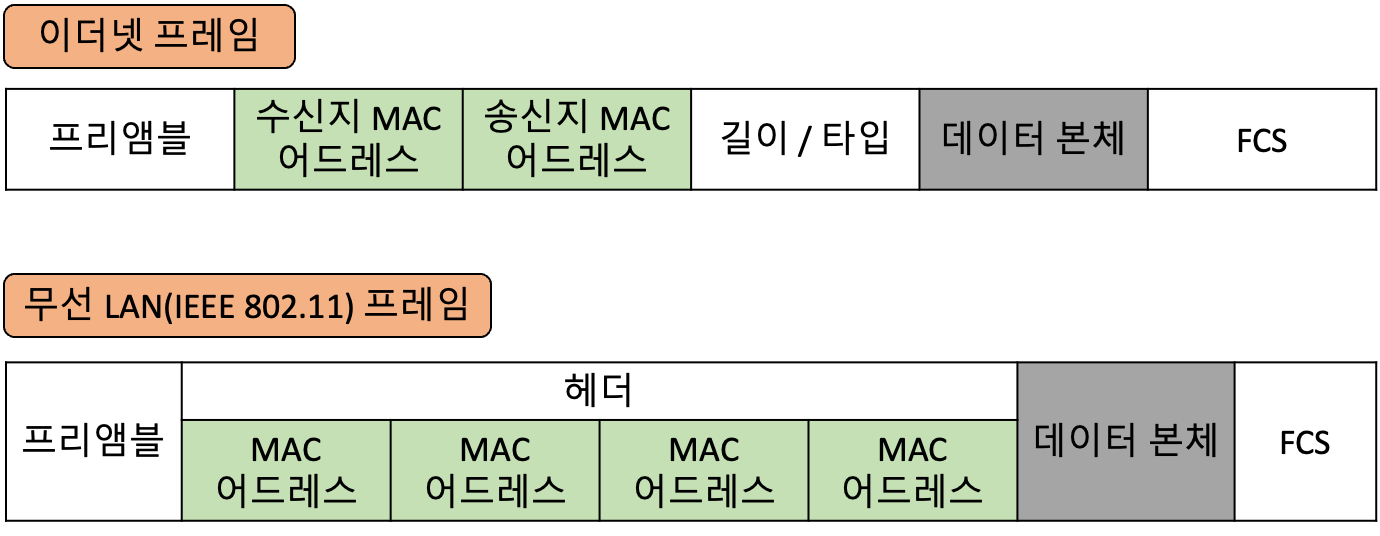
MAC 어드레스는 데이터를 전달할 목적지를 가리킨다는 점에서 IP 어드레스와 유사해요. 다른점이 있다면, IP 어드레스는 최종 목적지가 한 번 설정되면 전송 과중 정웨 변하지 않지만, MAC 어드레스는 통신 경로상 바로 다음 장비의 어드레스로 매번 교체돼요.
이더넷
유선 LAN은 통신 장비끼리 케이블로 연결할 때, 이더넷(Ethernet) 이라는 규격을 사용해요. 통신 속도나 접속 방식에 따라서 다양한 세부 규격이 존재해요.
주요 이더넷 규격
10BASE-T: 트위스트 페어 케이블을 사용하고 10Mbps로 통신한다.
100BASE-TX: 트위스트 페어 케이블을 사용하고 100Mbps로 통신한다.
1000BASE-T: 트위스트 페어 케이블을 사용하고 1000Mbps로 통신한다.
1000BASE-X: 광섬유 케이블을 사용하고 LX, SX, FX 등의 규격이 있다. 이들 규격은 케이블 종류나 전송 거리에 차이가 있다.
수신 측의 네트워크 어댑터는 전압의 높낮이가 변하는 신호를 받아 디지털 신호로 복호화해요. 이 때 어디부터가 신호의 시작인지 기준점을 두기위해, 프리앰블(Preamble) 이라는 패턴을 두어요. 프리앰블은 '10101010...'이 7바이트 이어지고 마지막에 '...10101011'이 나와요. 이는 길이가 상당히 긴 편이기 때문에 통신 중 앞부분의 데이터를 잃더라도 '1010'이 일정 횟수 반복되다 마지막이 '101011'로 끝나면 프렘이의 시작이라고 인식하게 돼있어요.
네트워크 허브
유선 LAN에서는 네트워크 허브 라는 장비에 케이블을 연결해서 네트워크를 구성해요. 네트워크 허브에는 리피터 허브 , L2 스위치(스위칭 허브) , L3 스위치 등이 있어요.
L2 스위치: OSI 참조 모델의 데이터 링크 계층을 의미하고, TCP/IP 모델에서는 네트워크 인터페이스 계층에 해당한다.
L3 스위치: OSI 참조 모델 중 네트워크 계층에 해당하고, TCP/IP 모델에서는 인터넷 계층의 기능까지 수행할 수 있는 네트워크 장비다.
L2 스위치 는 가장 많이 사용되는 네트워크 중계 기기에요. L2 스위치는 포트에 연결된 각 호스트의 MAC 어드레스를 기억해두었다가 통신 대상하고만 데이터를 전달하기 때문에 통신 과정에서 다른 호스트가 보내는 패킷과의 충돌을 피할 수 있어요. 덕분에 통신이 보다 효율적이죠.
브로드캐스트 도메인(Broadcast domain)이란 수신지의 주소가 브로드캐스트 어드레스일 때 데이터가 전달되는 범위에요. 그래서 L2 스위치로 네트워크를 구성한다면 네트워크 전체가 브로드캐스트 도메인이 되는 거죠. 만약 네트워크에 연결된 호스트가 많은 상태에서, 브로드캐스트 통신이 자주 사용되면 네트워크 내의 대량 패킷이 발생해 네트워 크가 혼잡해지기도 해요.
L3 스위치 의 대표적인 기능은 VLAN(Virtual LAN) 이에요. 이 기능은 LAN을 가상적인 네트워크들로 분할해서 통신 효율을 높이기 위해 사용해요. VLAN을 이용하면 같은 장비의 포트에 연결되어도, VLAN 별로 다른 IP 어드레스를 가지는 서로 다른 네트워크처럼 구성할 수 있어요. 이 때 VLAN 내의 통신 방식은 L2 스위치와 같죠. VLAN을 구성하면 브로드캐스트 패킷을 VLAN 내의 호스트 범위로만 제한하여 전달할 수 있어요.
무선 LAN
무선 LAN은 전파를 통신 매개체로 사용하며 정식 규격명은 IEEE 802.11 이에요. 무선 LAN은 CSMA/CA(Carrie Sense Multiple Access with Collision Avoidance) 방식을 이용해, 다른 통신 장비가 전파를 발신하는지 확인하고 통신을 시작해요.
주요 LAN 규격
IEEE 802.11: 기본이 되는 규격, 프레임의 구성 형태 등을 정의하고 있음
IEEE 802.11a: 5Hz 대역을 사용하며, 최대 54Mbps까지 통신 가능
IEEE 802.11b: 2.4GHz 대역을 사용하며, 최대 11Mbps까지 통신 가능
IEEE 802.11g: 2.4GHz 대역을 사용하며, OFDM 방식으로 최대 54Mbps까지 통신 가능
IEEE 802.11n: 여러 개의 안테나를 사용하여 최대 600Mbps까지 통신 가능
무선 LAN에서 통신할 때 주고받는 데이터도 프레임이라고 불러요. 유선과 다른 점이라면, MAC 어드레스 필드가 4개나 돼요. 이는 무선 LAN끼리 통신하는 경우나 무선 LAN 뒤에 유선 LAN이 연결되는 경우 등, 상황에 따라 MAC 어드레스에 할당되는 방식이 달라져요.

ARP
ARP(Address Resolution Protocol) 프로토콜은 이더넷이나 무선 LAN으로 데이터를 보낼 때, 수신 측의 MAC 어드레스를 알 수 있게 해줘요. 이 때 송신 측에서는 수신지 장비의 IP 어드레스를 알아야 해요. 송신 측 장비가 요청 패킷에 수신 측의 IP 어드레스를 설정하여 네트워크 전체에 브로드캐스트하게되면, 요청을 받은 호스트들 중에서 수신지의 IP 어드레스와 일치하는 장비가 자신의 MAC 어드레스를 응답 패킷에 담아 응답해요.
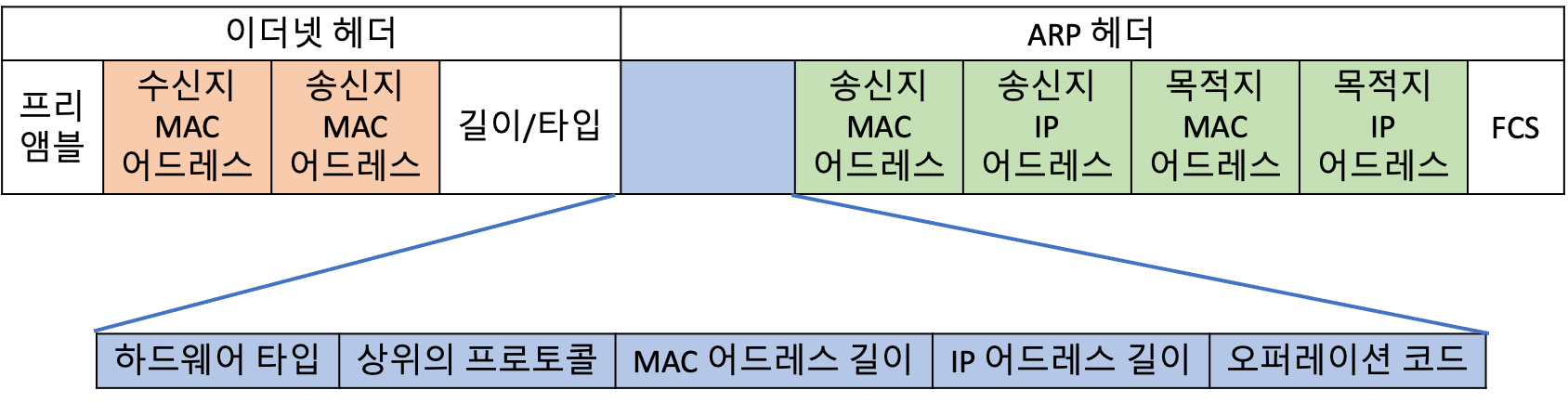
ARP 헤더에는 MAC 어드레스를 물어보는 송신지의 어드레스 정보와 MAC 어드레스를 알 수 없는 목적지의 어드레스를 담을 수 있어요. 오퍼레이션 코드가 1인 경우 요청을 의미하고, 2인 경우 응답을 의미해요.
프록시(Proxy) ARP 는 호스트 대신 라우터가 ARP에 대해 응답하는 기능이에요. 서브넷 마스크 값이 다른 호스트가 있을 때, 통상적인 ARP 요청은 같은 네트워크 내에 있는 호스트들에게는 브로드캐스팅되지만, 서브넷 마스크가 다른 호스트에는 전달되지 않아요. 따라서 프록시 ARP 기능을 사용해서 라우터가 자신의 MAC 어드레스를 대신 응답하여 데이터를 중계할 수 있게 만들어줘요.
arp 명령으로 MAC 어드레스 알아내기
IP 어드레스만 알고 MAC 어드레스를 모를 때는 ARP 를 사용하면 돼요. 원활한 네트워크와 시간 효율을 위해, 한번 확인한 MAC 어드레스는 요청한 컴퓨터에서 일정 기간 보관하여 캐시 기능을 하게 되어 있어요. 만약 캐시에 보관된 MAC 어드레스의 목록을 확인하고 싶다면 arp 명령으로 확인할 수 있어요.
$ arp -a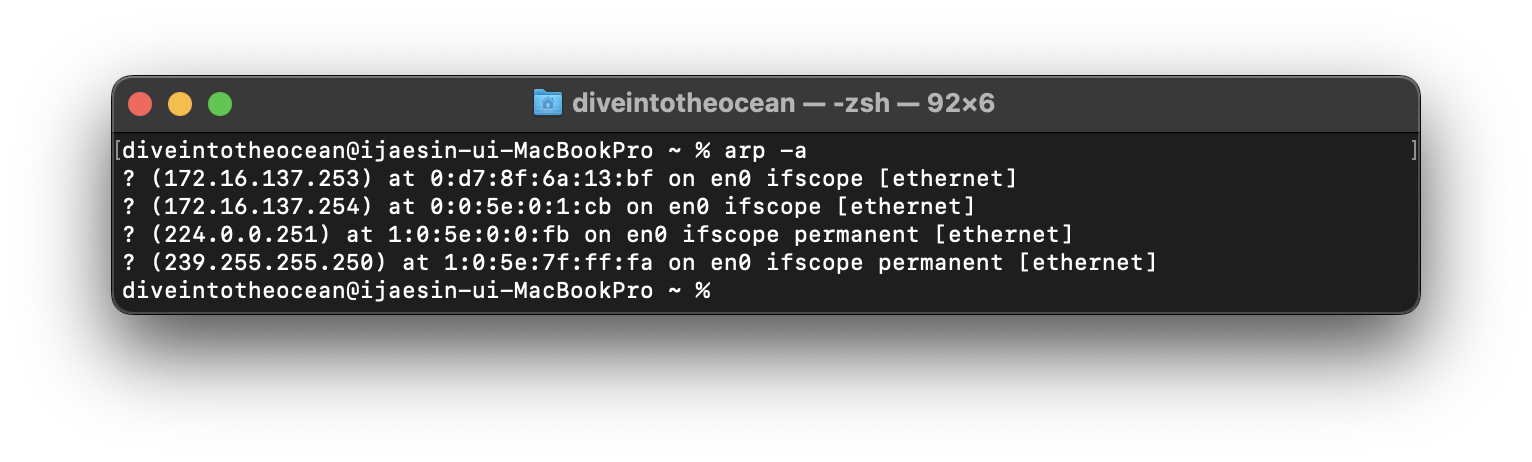
보안
앞서 설명했던 TCP/IP 기술은 기본적으로 데이터를 원본으로 전송하기 때문에 사실 보안 이 그렇게 좋지 않아요. 그래서 통신 과정의 보안 을 강화하기 위해 각종 암호화 기법과 프로토콜들이 존재하죠. 예를 들어, 웹 서비스의 경우 HTTPS를 사용하죠. HTTPS 는 HTTP에 SSL/TLS 라는 암호화 통신 프로토콜을 적용하여, HTTP로 주고받을 모든 통신 내용을 암호화하여 정보가 유출되지 않도록 해요.
위 처럼 통신 프로토콜로 방어할 수도 있지만, 사실 모든 프로토콜 하나하나에 대비하기란 역부족이에요. 그럴 때는 VPN 같은 방법도 생각해볼 수 있죠. VPN은 통신 거점 간의 통신을 통째로 암호화하는 방식이므로 에플리케이션 별 보안 대책을 일일이 세울 필요가 없어요. 하지만 이 방법은 통신 거점 사이의 구간만 보호할 수 있기에, 그 밖의 구간은 주의가 필요해요. 이렇게 보안 프로토콜은 보호하는 범위와 영역이 다르기 때문에, 취약점이 잘 드러나지 않게 잘 조합해서 사용해야 해요.
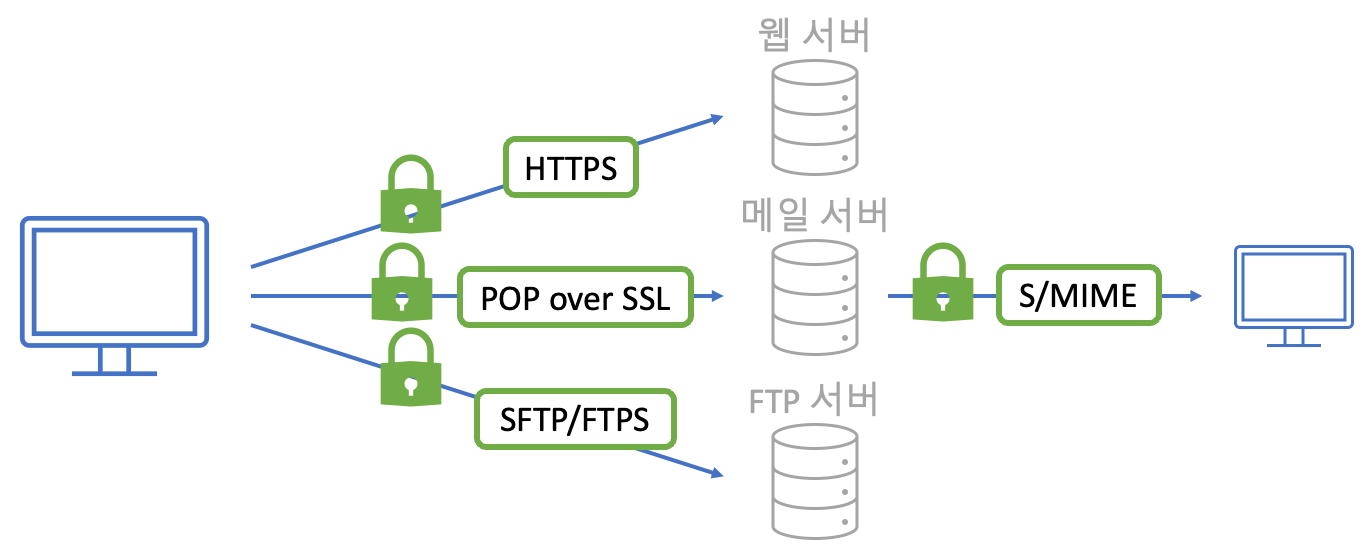
네트워크 보안
네트워크상에는 다양한 보안 위협들이 존재해요. 정보 유출 이나, 사용자 신분 사칭 , 데이터 위변조 등이 있죠.
이 중, 정보 유출에 대한 방어책으로는 데이터 암호화가 있어요. 암호화된 데이터는 제 3자에게 넘어가더라도 그 내용을 식벽하기 힘들죠. 암호화를 위해서는 키(Key) 를 사용하는데, 키의 관리 방식에 따라 공유 키 암호화 와 공개 키 암호화 두 가지 방법으로 나뉘어요. 두 방식 각자의 장단점이 있고, 두 개를 함께 조합해서 사용하기도 하죠. 이 외에도, 신분 사칭을 막아야 할 때는 전자 인증서 를 사용해요. 데이터 위변조를 방지할 때는 전자 서명 을 사용하죠.
공유 키와 공개 키
암호화는 데이터를 이해하기 어렵게 만드는 과정이고, 이는 보안을 위한 가장 기본적인 기술이에요. 이 때, 단순히 데이터를 암호화하기만 하는 것이 아니라, 암호화된 내용을 다시 원상태로 복호화할 수도 있어야겠죠. 그리고 키(key)가 바로 암호화와 복호화가 가능하도록 도와주죠. 공유 키 암호화 방식에서는 하나의 키로 암호화도 하고 복호화도 해요.
공유 키 암호화 방식은 처리 방식이 간단하고 암호화와 복호화 속도가 빠르다는 장점이 있어요. 대신 키를 안전하게 공유하는 방법이 다소 까다롭죠. 만약 키가 유출되면 큰일이닌까요. 더군다나 데이터를 공유할 모든 이들에게 같은 키를 나눠줘야 한다는 것도 꽤나 부담이죠.
이와 달리 공개 키 암호화 방식은 암호화를 하는 키와 복호화를 하는 키를 각각 만들어서 관리하는 방식이에요. 두 키를 각각 개인 키(또는 비밀 키)와 공개 키라고 하는데, 개인 키는 자신이 가지고 공개 키는 데이터를 공유할 상대방이 가지죠. 데이터를 주고 받을 때는, 먼저 상대에게 자신의 공개 키를 사전에 전달해둬요. 이후 상대방이 데이터를 보낼 때 받았던 공개 키로 데이터를 암호화하여 보내고, 수신자는 자신의 개인 키로 데이터를 복호화해서 볼 수 있어요. 복호화는 개인 키만의 능력이기 때문에 공유 키를 가지고 있다고 하더라 데이터를 읽을 수는 없어요. 단지 데이터를 암호화할 뿐이죠.
전자 증명서와 전자 서명
공유 키나 공개 키로도 완전히 안전한 것은 아니에요. 자신이 데이터를 주고 받는 사람이 정말 신뢰할만한 사람인지 모른다면, 데이터가 유출될 수 있죠. 이와 같이 신분 사칭이나 메일 내용의 위변조를 막을 방법으로 인증 기관(CA, Certificate Authority)이 발행한 전자 인증서 라는 것이 있어요. 발급받은 전자 인증서 안에는 공개 키 와 인증 기관의 전자 서명 이 포함되어 있죠. 전자 서명은 데이터 내용이 위변조되지 않았다는 것과 누가 보낸 것인지를 보증해줘요.
전자 서명을 만들기 위해서는 원본 데이터의 해시(Hash) 값을 구하여 공개키로 암호화하면 돼요. 개인 키로 암호화된 데이터는 나중에 전자 증명서와 함께 보내진 공개 키로 복원할 수 있어요. 이후 메시지 다이제스트가 일치하는지 확인하여 위변조 여부를 결정하죠.
이러한 공개 키나 전자 인증서 등의 보안 인프라를 통틀어 공개 키 기반 구조(PKI, Public Key Infrastructure) 라고 해요. 하지만 이러한 공개 키 기반 구조가 피싱 사이트로 인한 금융 사기나 컴퓨터 바이러스와 같이 모든 위협으로부터 보호해주지는 못해요. 그래서 이러한 취약점에 따라 별도의 방어 대책을 세워야 하죠.
이메일을 안전하게 주고 받을 때는 또 다른 방법을 사용해요. 바로 표준화된 규격인 S/MIME(Secure / Multipurpose Internet Mail Extensions) 에요. 이메일을 주고 받는 프로그램이 S/MIME을 지원하고 서로가 전자 인증서를 가지고 있을 경우 사용 가능하죠. S/MIME가 보안을 지키는 방법은 앞에서 설명했건 것들과 비슷한데 다른 점이 있다면, 이메일을 암호화할 때 공개 키와 공유 키 방식을 조합 해서 사용한다는 거에요. 통신 과정은 다음과 같아요.
- 공유 키를 사용해 메일 본문을 암호화한다.
- 상대방의 공개 키로 공유 키를 암호화한다.
- 암호화한 본문과 키를 첨부한 이메일을 보낸다.
- 수신자의 개인 키로 수신 받은 공유 키를 복호화한다.
- 수신 받은 메일 본문을 공유 복호화한 공유 키로 복호화한다.
본문을 암호화할 때 공유 키를 사용하는 이유는 공개 키 방식으로 암복호화하는 것보다 연산 처리 측면에서 부담이 덜하기 때문이라고 해요.
SSL/TLS
SSL(Secure Sockets Layer) 혹은 TLS(Tranport Layer Security) 는 클라이언트와 서버 간의 통신 보안을 높이기 위한 프로토콜이에요. 인증 기관에서 발행된 서버 인증서를 시용해 서버를 증명하고, 통신 구간을 암호화하여, 데이터 위변조를 막죠. 방법은 앞서 메일에서 사용한 방식인 S/MIME과 비슷해요. 다만 여기서는 서버와 클라이언트의 통신이기 때문에, 서버가 먼저 클라이언트에게 전자 인증서를 보내주죠. 그럼 클라이언트 측은 서버의 공개키와 난수를 사용해 생성된 공유 키를 이용하여 서버와 통신하죠. SSL/TLS를 사용안 보안 프로토콜 중 대표적인 것이 바로 HTTPS 에요.
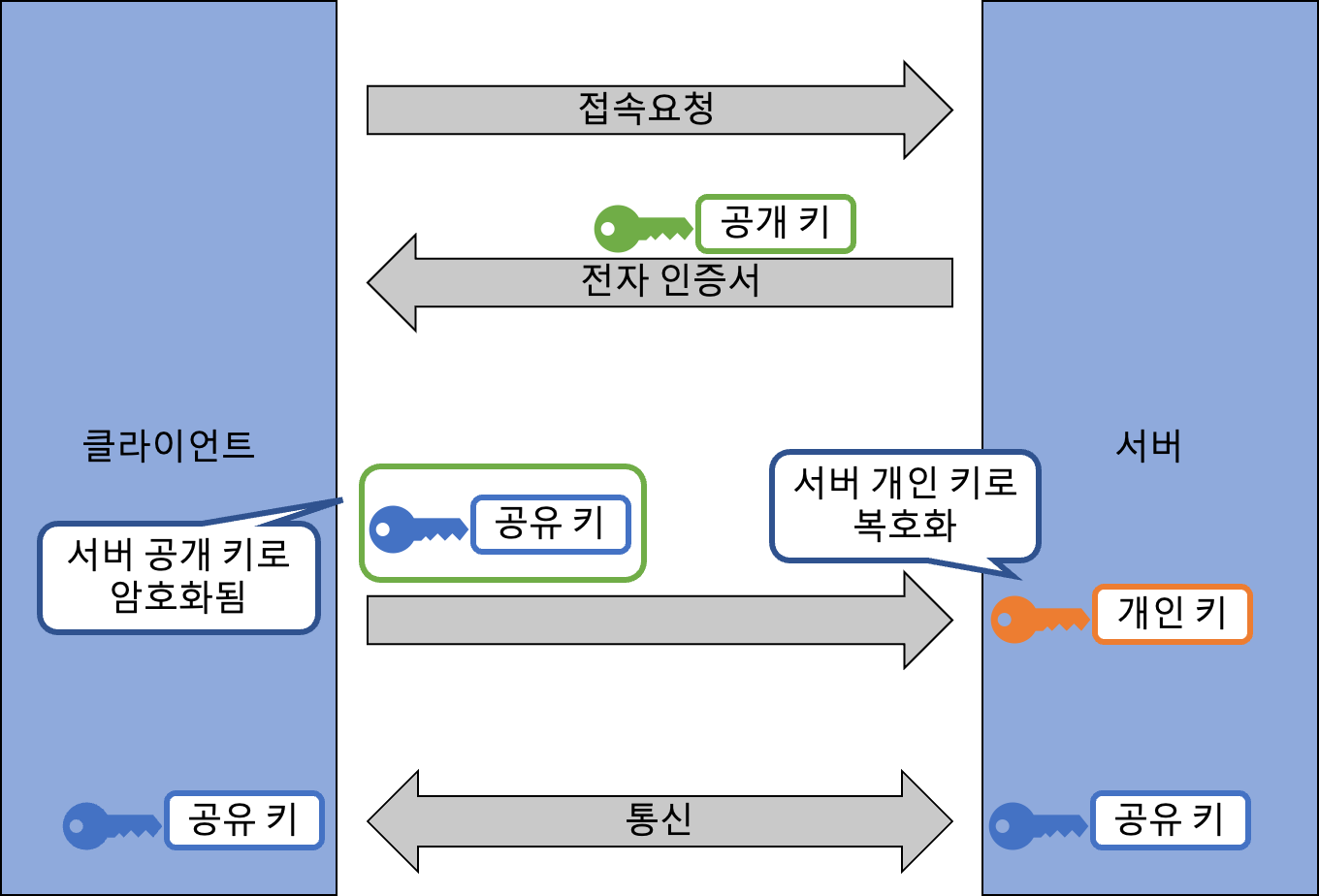
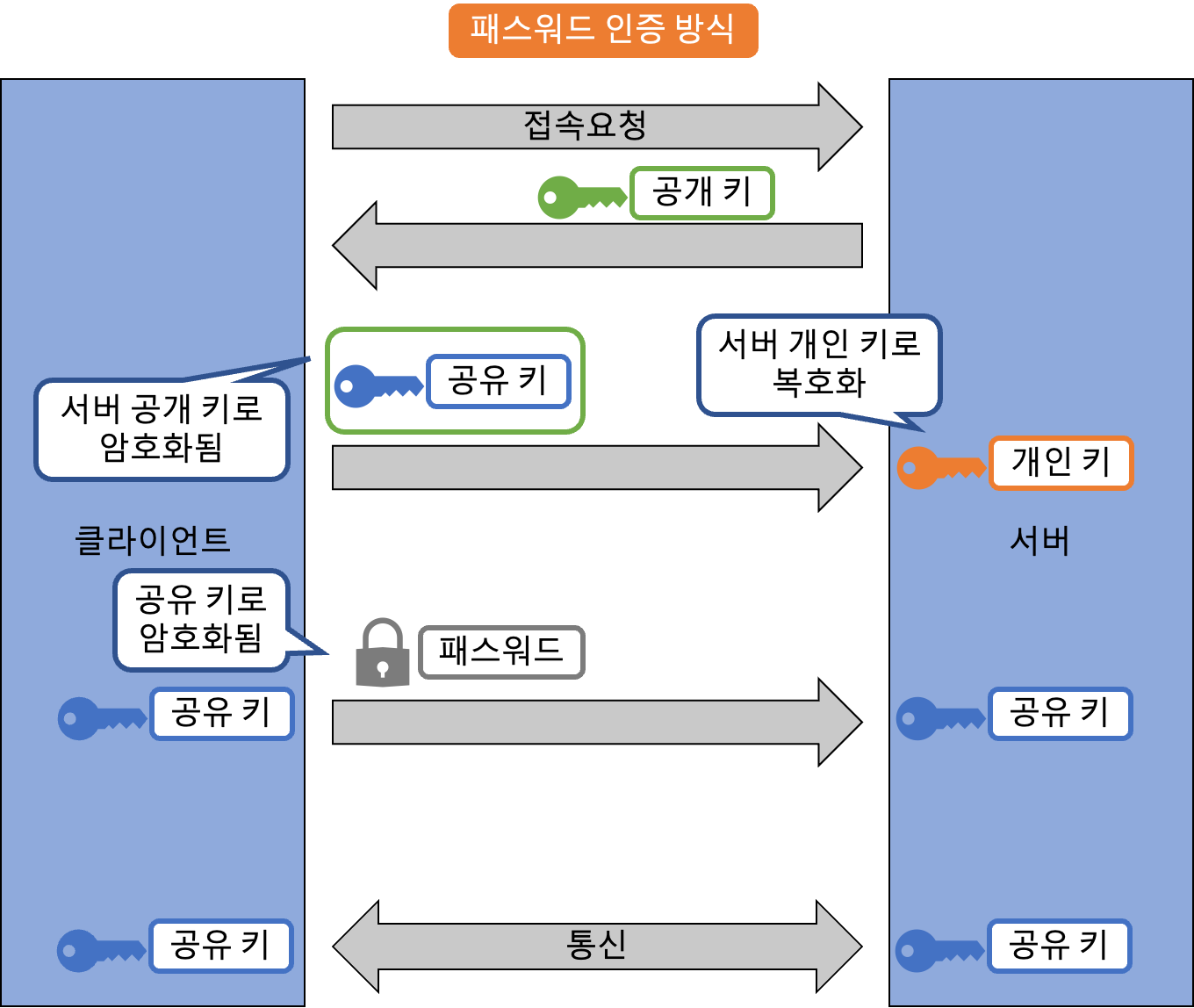
SSH
SSH(Secure SHell) 은 원래 원격지 서버를 제어하기 위해 만들어진 telnet을 대체하는 프로토콜이에요. SSL과 마찬가지로 공개 키와 공유 키를 조합한 방식으로 통신하죠. 대신 전자 인증서는 사용하지 않고 서버나 클라이언트가 만든 공개 키를 사용해요. 인증 방식으로는 패스워드 인증 이나 공개 키 인증 등을 사용하죠. 패스워드 인증 방식은 앞선 SSL 이나 S/MIME과 비슷하게 서버 측의 공개 키를 사용해요. 하지만 공개 키 인증 방식에서는 클라이언트 측에서 공개 키를 들고 미리 접속할 서버에 등록해 두어 인증에 사용하죠. 이는 원격 접속을 할 때마다 패스워드를 입력하지 않아도 돼서 편리해요.
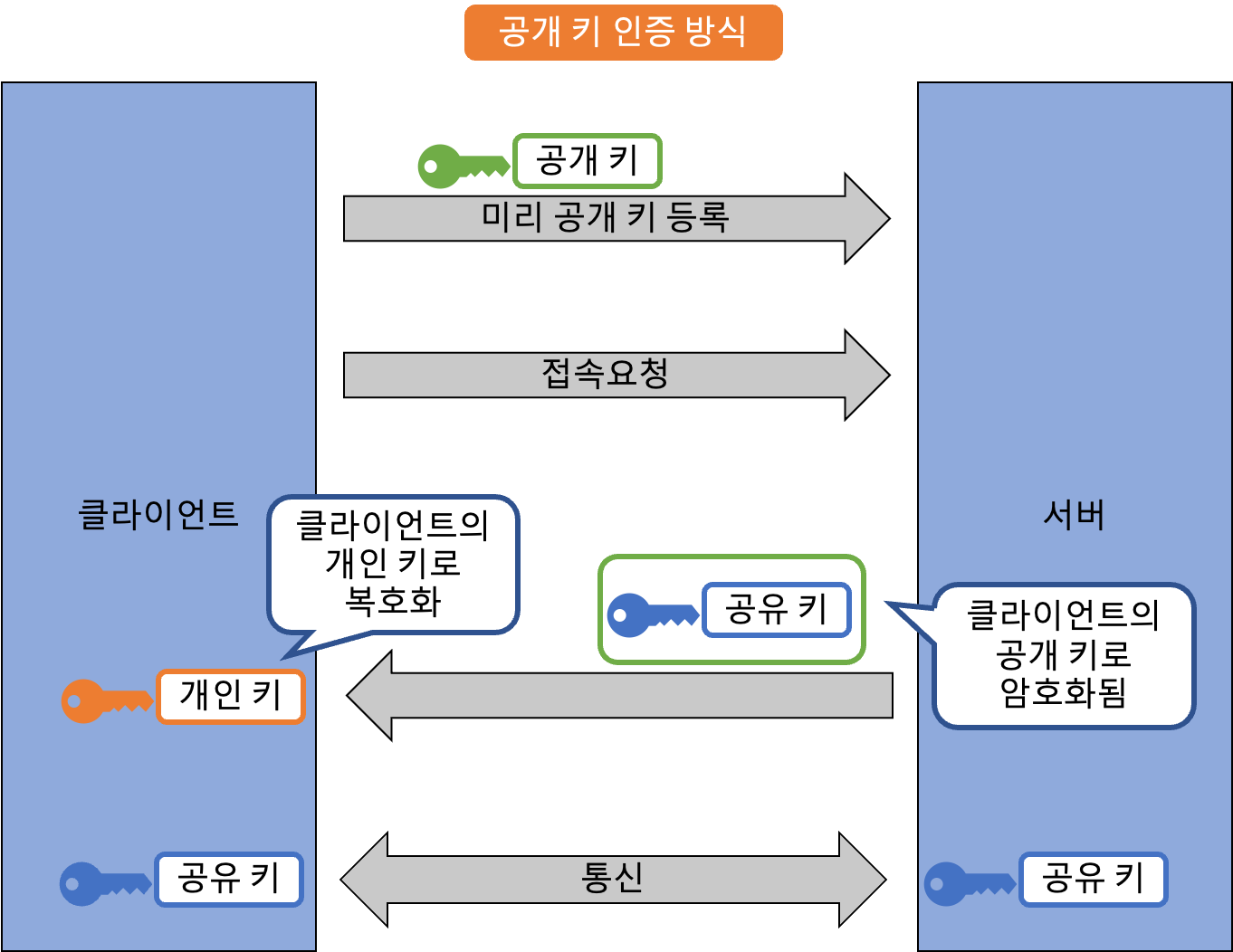
방화벽
외부에서의 접속을 허용한 네트워크는 해킹과 같은 악의적인 접근을 조심해야 돼요. 이렇게 외부로부터의 접근을 차단할 때 사용하는 방법이 방화벽 이에요. 방화벽은 허가된 통신 외에 모두 차단하기 때문에, 허용된 범주에서만 잘 관리한다면 서버를 안전하게 지킬 수 있어요.
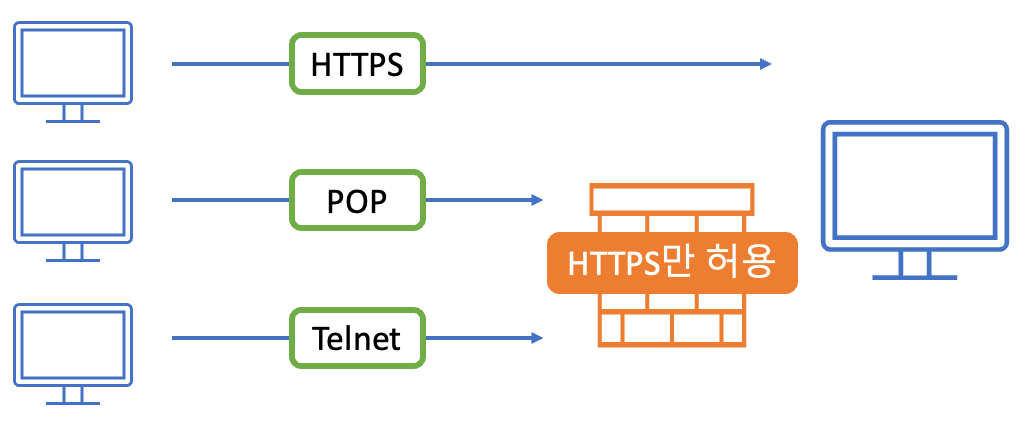
방화벽은 접속을 허가하거나 차단하기 위해 패킷 내의 정보를 확인해요. 이렇게 방화벽이 보안을 형성하는 방법은 패킷 정보를 점검하는 계층에 따라 달라져요.
패킷 필터: IP 어드레스나 포트 번호를 보고 제어한다.
서킷 레벨 게이트웨이: 통신 쌍방을 직접 연결하지 못하게 중간에서 통신을 중계한다.
애플리케이션 게이트웨이: 애플리케이션 계층에서 다루는 URL이나 텍스트 정보를 보고 판단한다.
네트워크 보안에서 중요한 단어로 시큐리티 홀(Security hole) 이란게 있어요. 이는 정보 유출과 같은 보안 취약점을 잠재한 프로그램상의 결함을 의미하고, 그냥 방치해 두면 언젠가 악의적인 공격으로부터 뚫릴 수 있는 보안상의 구멍을 말해요. 방화벽으로 필요한 통신만 열어두게 되면 이러한 시큐리티 홀에 대해 주의해야 하는 범위가 상당히 줄어들어 취약점을 예방하고 관리 측면에서 유리 할 수 있어요.
무선 LAN의 보안
무선 LAN 은 전파로 통신하기 때문에 유선 LAN에 비해 상대적으로 도청 위험이 더 커요. 이 때문에 IEEE 802.11 에서는 암호화와 같은 보안 기능에 대한 규격이 추가되었죠. 새롭게 나온 기술일 수록 보안 강도가 더 높아요. 무선 LAN 통신은 안전하면서도 고속으로 처리돼야 해요. 그래서 암복호를 할 때 연산 처리 부담이 큰 공개 키 방식은 사용하지 않고, 대신 공유 키 방식을 사용하죠. WPA 이전에는 공유 키 방식의 하나인 스트림 암호화 방식이 쓰였는데, WPA2에서 더 강력한 블록 암호화 방식을 사용해요.
WEP: IEEE 802.11의 일부. 사용자가 지정한 WEP 키와 24비트의 초기화 벡터 값을 사용하여 암호화에 필요한 키를 생성한다. 취약점이 발견되어 현재는 사용되지 않는다.
WPA: 48비트의 패스프레이즈에 MAC 어드레스의 해시 값을 합친 128비트의 데이터와 48비트의 초기화 벡터 값을 암호화 키로 사용한다. WEP보다는 강력하나, 뒤이어 나온 WPA2로 대체되고 있다.
WPA2: WPA를 강화한 암호화 방식으로, 블록 암호인 AES를 사용한다.
IEEE 802.11i: WPA, WPA2를 표준 규격화한 것이다.
무선 LAN의 보안 기능에서는 패스프레이즈 라는 사용자 지정 문자열과 초기화 벡터 라는 조금씩 변하는 값을 조합하여 암호화를 위한 공유 키를 만들어요. 초기화 벡터가 바뀌면서 공유 키도 바뀌기 때문에 통신할 때마다 다른공유 키가 생성돼요. 덕분에 간단한 암호화가 장점이지만, 초기화 벡터의 길이가 짧으면 일정 시간 간격으로 같은 공유 키가 만들어질 수 있어서 복호화의 실마리를 줄 여지가 있어요. 그래서 패스프레이즈와 초기화 벡터 값을 길게 만들어 사용하고 있죠.
VPN
아무리 각종 보안 기술들을 적용하여 보안을 안전하게 구성한다 한들, 모든 보안 프로토콜들을 하나하나 사용한다는 것은 관리 측면에서 적지 않은 부담이 되겠죠. 그래서 특정 구간 내의 통신 전체를 안전하게 만드는 기술이 필요한데, 그것이 바로 VPN(Virtual Private Network) 에요. VPN에는 인터넷상에서 암복호화를 하여 통신하는 인터넷 VPN과 인터넷과는 분리된 별개 회선을 사용하는 클로즈드 VPN이 있어요.
VPN에 사용되는 프로토콜에는 IPSec(Security Architecture for Internet Protocol) 이나 PPTP(Point to Point Tunneling Protocol) 등이 있어요. 그 외에도 IPSec에 L2TP(Layer 2 Tunneling Protocol)를 조합한 L2TP/IPSec 도 널리 사용되고 있는 기술이에요. 이를 통해 데이터를 전송할 때는 패킷을 IP 헤더까지 통째로 암호화하여 새로운 IP 헤더를 덧붙여 송신하죠.

가정에서 사용하는 컴퓨터나 스마트폰에서 VPN을 사용하면 사용자 인증이 필요해요. 하지만 IPSec에는 사용자별 인증 기능이 없으므로 L2TP를 조합해서 사용하죠.

참고 자료
- 리브로웍스, 『(명쾌한 설명과 풍부한 그림으로 배우는) TCP/IP: 쉽게, 더 쉽게』, 제이펍(2016)
