✅ 크롤링 방법
1️⃣ 컨트롤러 생성하기
1. 터미널에 아래 명령어를 사용해서 컨트롤러를 생성한다.
rails g controller [폴더명] [파일명]그럼 아래처럼 폴더와 파일 그리고 라우터가 생성된다.
(예제를 위해 kurly라는 컨트롤러 생성)
- 컨트롤러 폴더와 파일
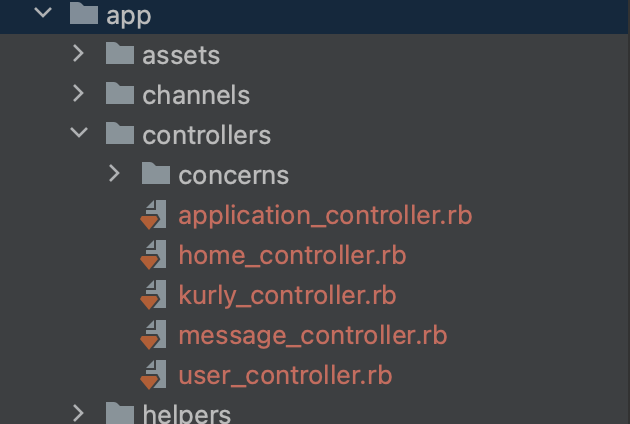
-
view 폴더와 파일
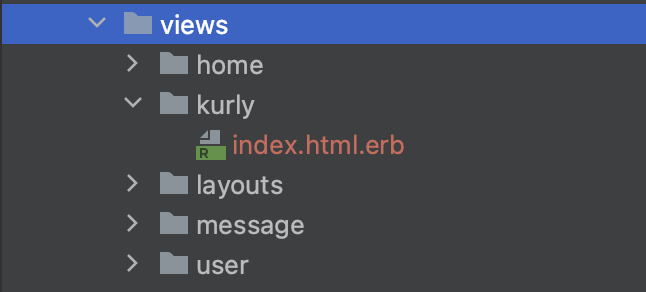
-
라우터 경로
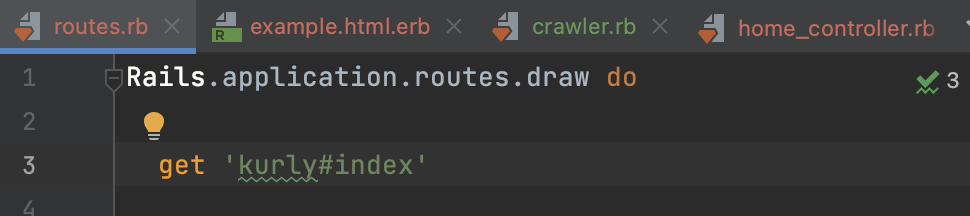
👉 여기서 라우터의 경로는 아래처럼 수정해준다.
get 'kurly', to:'kurly#index'그럼 url에 kurly라고 입력시 kurly#index 페이지로 이동할 수 있다.
2️⃣ 크롤러 만들기
아래 내용을 시작하기 전에 **Ruby의 클래스(클릭)**에 대해 정리 해놓은 블로그를 참고하면 좋다.
1. Selenium import 하기
require 'selenium-webdriver'여기서 require 는 import 와 같다.
2. class를 생성한다.
class crawler
endclass 키워드로 시작하면 항상 end 로 끝난다.
(⬇️ 모두 위에서 작성한 class 안에 작성하기)
2-1. 브라우저 설정하기 (= 초기화)
def initialize
@driver = Selenium::WebDriver.for :chrome
@window = @driver.manage.window
@window.maximize
end@driver = Selenium::WebDriver.for :chrome: Selenium의 브라우저는 chrome으로 설정@window = @driver.manage.window: 브라우저의 크기를 조절하는 메소드는 @window라는 변수에 저장@window.maximize: 브라우저의 창 크기 최대화
👉 2~3번째 코드는 self.browser.manage.window.maximize 로 한줄로 줄일 수 있다.
2-2. driver 관리 로직 만들기
✍️ @driver 에 접근할 수 있는 로직 만들기
def browser
@driver
end앞으로 browser 란 이름으로 @driver 에 접근할 수 있다.
✍️ @driver 의 창을 닫을 수 있는 로직 만들기
def close
@driver.quit if @driver
end그럼 이제 다른 곳에서 .close 를 사용했을때 켜져있는 브라우저가 있다면 자동으로 창을 닫을 수 있다.
✍️ @driver 를 이동시키는 로직을 만들기
def goto(url)
browser.navigate.to url
end@driver 를 url이라는 이름의 인자를 받아서 해당 링크로 이동시킬 수 있다.
2-3. 크롤러 로직 작성하기
👛 변수의 접근자/설정자 작성하기 (추가 설명은 클릭)
attr_accessor :driver👛 인스턴스 메소드 생성하기
def self.fetch_kurly_data
[...crawler 로직...]
end👛 object 생성하기 / url 지정하기
crawler = self.new
crawler.goto "https://www.kurly.com"👛 해당요소 찾기
crawler.driver.find_element(css:'#header > div ul > li:nth-child(2)').clickfind_element=document.quertSelector와 같다.(css : ): css 선택자로 찾겠다는 의미이다.
🧟♀️ 반복문 돌리기
data_list = crawler.driver.find_elements(css: '.list_theme > li.theme_item').map do |item|
{
title: item.find_element(css:'strong.title').text,
image: item.find_element(css:'img').attribute('src'),
link: item.find_element(css:'a').attribute('href'),
text: item.find_element(css:'p.desc').text,
}Ruby rails에서는 each / map 을 사용해서 반복문을 작성하면 된다.
👛 브라우저 닫기 / object 보여주기
crawler.close
data_list3. 크롤러 실행하기
rails s터미널에 위 명령어를 입력 후 크롤러가 잘 작동하는지 확인한다.
