캐시란 ?
속도가 빠른 장치와 느린 장치의 속도차에 따른 병목 현상을 줄이기 위한 범용 메모리.
CPU가 메인 메모리 접근하기 전에 캐시 메모리에서 원하는 데이터 존재 여부 확인
데이터 있을 때 = Hit, 없는 경우 Miss -> 요청한 데이터를 캐시 메모리에서 찾을 확률 (Hit Ratio)
캐시 종류
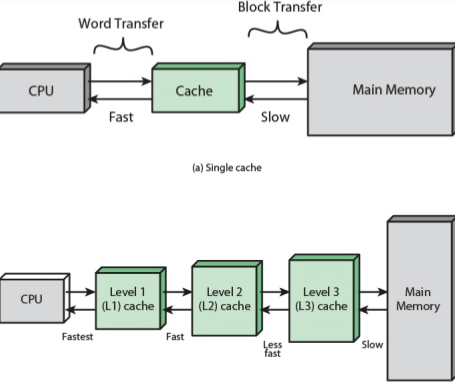
캐시 메모리의 작동 순서가 L1에서 순차적으로 데이터를 찾아 L1에 찾고자 하는 데이터가 없다면 순서대로 L2, L3로 올라가며 데이터를 찾는 것
-
L1 Cache
CPU의 가장 가까운 캐시, 속도를 위해 IC와 DC로 나눈다.
IC : 메모리에서 text 영역의 데이터를 다루는 캐시
DC : 메모리에서 text 영역을 제외한 데이터를 다루는 캐시 -
L2 Cache
용량이 크다. 크기를 위해 L1 Cache와 같이 나누지 않는다. -
L3 Cache
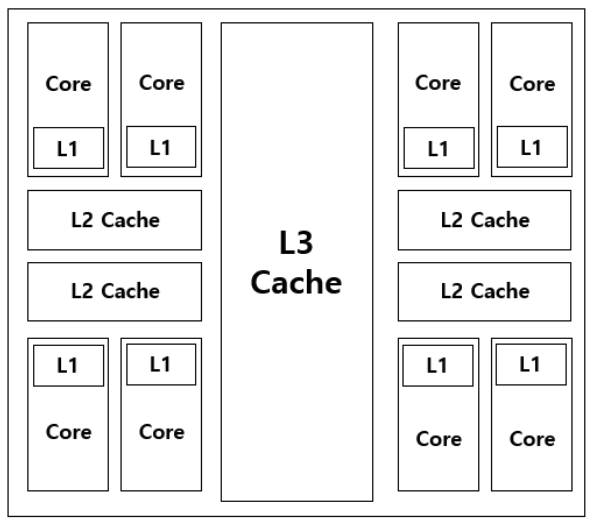
멀티 코어 시스템에서 코어가 공유하는 캐시 -
전송 단위
- 워드
CPU의 기본 처리, 블록/라인을 구성하는 기본 단위- 블록
메모리를 기준으로 잡은 캐시와의 전송 단위, 캐시 라인과 크기가 같으며, 메모리 블록은 여러개의 워드로 구성 - 캐시 라인
메모리 블록과 동일한 크기의 캐시 관점의 캐시 -> 메모리간 전송 단위, 캐시는 여러개의 캐시 라인으로 이어져 있으며 각 라인은 여러개의 워드로 구성
- 메인 메모리의 내용을 캐시에 저장하기 위해서는 메인 메모리 데이터를 읽어와야 .
읽어들이는 최소 단위를 캐시 라인. 읽어드리는데 데이터의 캐시의 data block을 구성
- 블록
캐시의 쓰기
캐시는 데이터를 읽을때 빠르게 읽기 위해서 사용하는 저장공간, 하지만 캐시는 쓰기 명령을 수행할 때도 사용
- write Through(동시 쓰기) : CPU가 데이터를 사용하면 캐시에 저장, 데이터가 캐시됨과 동시에 메인 메모리에 기입하는 방식
- 즉 데이터를 쓸때 메모리에는 쓰지 않고 캐시에만 업데이트 하다, 필요할 때만 메인메모리에 기록 하는 방식- 장점 : write though보다 빠름
- 단점 : 캐시와 메인 메모리 데이터가 서로 값이 다른 경우 발생 가능
캐시의 지역성 원리
캐시가 효율적으로 동작, 캐시의 적중률을 극대화, 캐시의 적중률을 극대화, 캐시에 저장할 데이터가 지니는 지역성을 가져야함
지역성이란 데이터 접근이 시간적 혹은 공간적으로 가깝게 일어나는 것
지역성의 전제 조건으로 프로그램은 모든 코드나 데이터를 균등하게 Access하지 않는다는 특징
즉 지역성이란 기억장치 내의 정보를 균일하게 Access 하는 것이 아닌 어느 한 순간에 특정 부분을 집중적으로 참조하는 특성.
-
시간 지역성 : 최근에 참조된 주소의 내용은 곧 다음에 다시 참조
- for, while- 반복문을 수행하면 특정 메모리 값으로 선언된 부분을 반복해서 접근. 방금전 접근했던 메모리를 다시 참조 하게 될 확률이 증가
-
공간 지역성 : 대부분의 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조
- Array
- 배열은 일정한 메모리 공간을 순차적으로 할당받아 사용. 공간할당을 연속적으로 받는다.
연속적으로 받게 된 메모리를 사용할때 연속적으로 사용할 확률 높음

Mapping Function
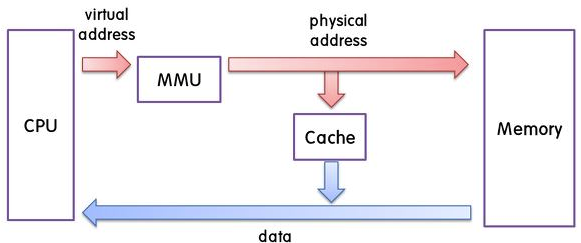
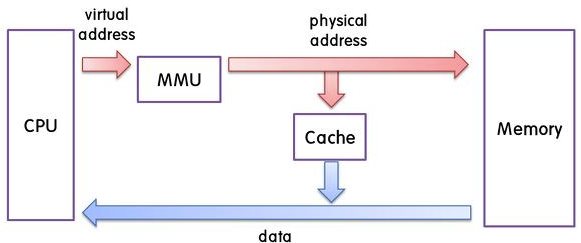
CPU 메모리 주소를 사용해서 메모리로 데이터 받으려고 함.
CPU가 쓰는 주소는 가상 메모리 주소, 메모리 입장에서는 생소함
중간에 MMU가 가운데에서 번역 -> 물리주소로 변환. 그리고 캐시에 해당 주소에 대한 데이터가 있는지 확인.
캐시에 데이터를 저장하는 방식에 따라 물리주소를 다르게 해석 가능
Mapping Function이란 캐시에 데이터를 저장하는 여러가지 방법
-
직접 Mapping
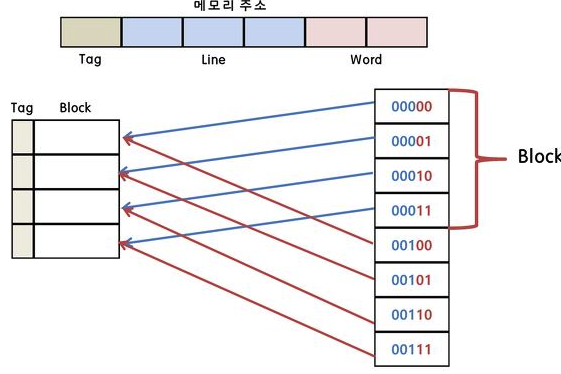
캐시에 들어올때 이미 자리 정해짐
캐시로 데이터 저장할때 캐시의 지역성 -> 한번 퍼낼 때 인접한 곳 까지 캐시 메모리에 저장, == 단위 블록그리고 캐시는 메인 메모리의 몇번째 블록인지 알려주는 Tag- 메모리 주소 중 가장 뒷부분 = 블록의 크기 - 같은 라인에 위치하는 데이터는 파란색 칠한 영역에 의해 구별 가능
캐시 메모리는 메인 메모리보다 작기 때문에 직접 메핑 방식을 사용하게 되면 겹치는 부분은 캐시를 교체
- 연관 Mapping
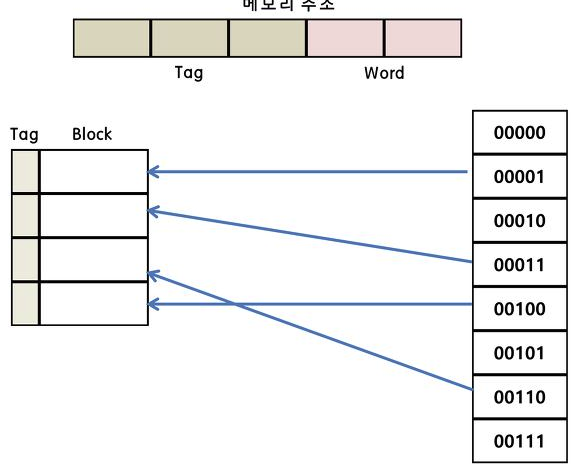
직접 매핑의 단점을 보안하기 위해 등장. 캐시에 저장된 데이터들은 메인 메모리의 순서와는 아무런 관련 없다.
즉 빈공간 있다면 데이터를 넣을 수 있다.
캐시를 전부 뒤져서 태그같은 데이터가 있는지 확인. 따라서 병렬 검사를 위해 복잡한 회로를 갖고 있는 것이 단점. 하지만 적중률 높음
- 세트 연관 매핑
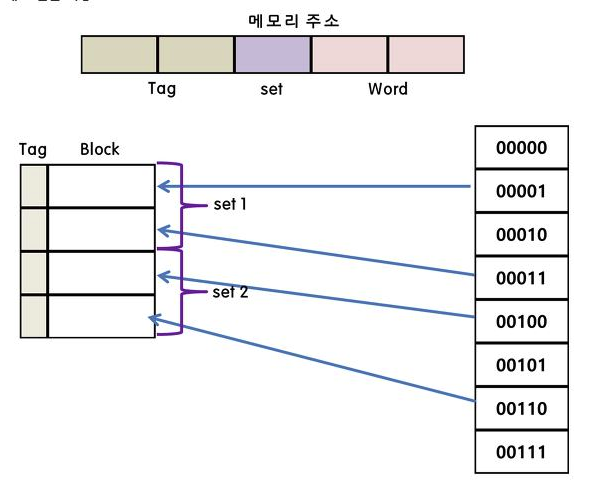
직접 매핑의 단순한 회로와 연관 매핑의 적중률 두 개 장점만 갖기 위해 생성된 방식.
각각의 라인들은 하나의 세트에 속해있음. 세트 변호를 통해 영역을 탐색함으로 연관 매핑의 병렬 탐색을 줄일 수 있음
