컬랙션 프레임워크
프레임워크라는 표현에 이해
잘 정의된 골격의 구조, 잘 정의된 구조의 클래스 = 라이브러리라고 부른다.
컬렉션 의미와 자료구조
자료구조 -> 데이터의 저장, 탐색, 삭제등 다양한 측면으로 연구
알고리즘 -> 데이터의 일부 또는 전체를 대상으로 하는 각종 가공 및 처리를 하는 학문
List, stack, Queue, Tree, Hash
Bubble Sort, Quick Sort, Binary Search
리스트 인터페이스를 구현하는 컬랙션들
ArrayList
ArrayList -> 배열 기반 자료구조, 배열을 이용하여 인스턴스 저장.
LinkedList -> 리스트 기반 자료구조, 리스트를 구성하여 인스턴스 저장.
List 인터페이스를 구현하는 컬랙션 클래스들이 갖는 공통점
인스턴스 저장 순서를 유지
인스턴스 중복저장을 허용
public class Main1 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
List<String> list1 = new LinkedList<>();
list.add("Toy");
list.add("Box");
list.add("Robot");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i) + " ");
System.out.println();
list.remove(0);
for (int j = 0; j < list.size(); j++) {
System.out.println(list.get(0) + " ");
System.out.println();
}
}
}
}
List list = new ArrayList<>();
ArrayList를 사용하지 않은 이유는 코드의 유연성을 제공. List에 선언된 메소드를 호출하기 때문에 굳이 ArrayList형 참조 변수를 굳이 선언 할 필요X
List.add -> 저장
for (int i = 0; i < list.size(); i++) {
size의 호출을 통해서 저장된 인스턴스 수를 알 수 있으며, get 메소드에 인덱스 값을 전달 하므로써 원하는 인스턴스를 참조할 수 있다. 0을 전달 -> 첫 인덱스 값 가져온다.
List.remove(0) -> 첫 번째로 저장된 인스턴스 삭제
컬렉션 인스턴스를 사용하면, 배열처럼 길이를 신경쓰지 않아도 된다. ArrayList 인스턴스는 내부적으로 배열을 생성해서 인스턴스를 저장. 필요하면 그 배열의 길이를 스스로 늘린다.
따라서 성능을 신경 써야 한다면 ArrayList의 생성자 정도는 알아둘 필요성 O
Public ArrayList(int initialCapacity)
인자로 전달된 수의 인스턴스를 저장 할 수 있는 공간 확보
저장해야 할 인스턴스 수가 계산이 된다면, 생성자를 통해 적당히 길이의 배열을 미리 만들어 두는 것 도움 된다.
LinkedList
public class Main2 {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
list.add("Toy");
list.add("Box");
list.add("Robot");
for (String s:
list) {
System.out.println(s);
}
System.out.println();
list.remove(0);
for (String s:
list) {
System.out.println(s);
}
System.out.println();
}
}
LinkedList는 연결 리스트라는 자료구조 기반으로 디자인 된 클래스. 칸칸이 연결된 화물열차.
인스턴스 저장 : 열차 칸 하나 추가로 연결 -> 칸에 인스턴스 저장
인스턴스 삭제 : 해당 인스턴스를 저장하고 있는 열차 칸 삭제
ArrayList Vs LinkedList
ArrayList 단점
-> 저장 공간을 늘리는 과정에서 시간 소모 많음
-> 삭제 과정에서 많은 연산 필요
배열 중간에 위치한 인스턴스를 삭제 -> 삭제된 위치를 비워두지 않기 위해 한칸씩 인스턴스 이동
ArrayList 장점
저장된 인스턴스의 참조 빠름
배열에 저장된 요소에 접근 할 때 인덱스 값을 통해 원하는 위치에 바로 접근. 어느 위치에 있건 접근에 소요되는 시간은 동일. 반면에 LinkedList는 이런 접근 불가능.
연결 리스트라는 구조는 중간에 위치한 열차 칸에 바로 접근이 안된다. 한칸 한칸 건너가야 하는 구조
속도 느리다.
저장된 인스턴스 순차적 접근 방법
Enhanced for
저장된 모든 인스턴스들에 순차적 접근
저장된 인스턴스 전부를 대상을 탐색.
public class Main3 {
public static void main(String[] args) {
List<String> list = new LinkedList<>();
list.add("Toy");
list.add("Box");
list.add("Robot");
Iterator<String> itr = list.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
System.out.println();
itr = list.iterator();
String str;
while (itr.hasNext()){
str = itr.next();
if (str.equals("Box")){
itr.remove();
}
itr = list.iterator();
while (itr.hasNext()){
System.out.println(itr.next());
System.out.println();
}
}
}
}
}저장된 인스턴스를 대상으로 한 연산이 필요한 경우 for – each 문을 사용 할 수 있다. For -each 문을 순차적 접근의 대상이 되려면 인터페이스를 구현
Public interface Iterable
Collection -> Iterable을 상속하고 있고, ArrayList와 LinkedList를 상속
인터페이스의 순차적 접근2
Iterator iterator()
반복자라는 것을 반환. 반복자는 저장된 인스턴스들을 순차적으로 참조 할 때 사용하는 인스턴스.
public class Main4 {
public static void main(String[] args) {
List<String> list = new ArrayList<>(Arrays.asList("Toy", "Box", "Robot"));
list = new ArrayList<>(list);
for (Iterator<String> itr = list.iterator(); itr.hasNext();) {
System.out.println(itr.next());
System.out.println();
}
for (Iterator<String> itr = list.iterator(); itr.hasNext();){
if (itr.next().equals("Box")){
itr.remove();
}
}
list = new LinkedList<>(list);
for (Iterator<String> itr = list.iterator(); itr.hasNext();){
System.out.println(itr.next());
System.out.println();
}
}
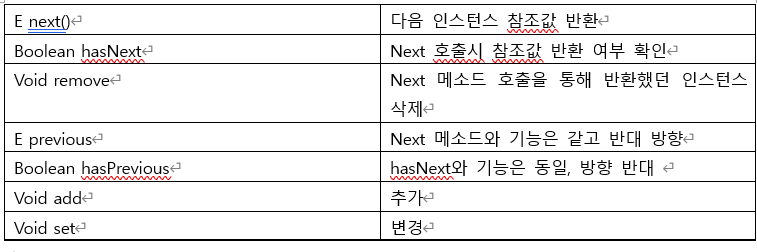
} E next -> 다음 인스턴스 참조값 반환
Boolean hasNext – next 메소드 호출 시 값 반환 가능 여부
Void remove – 인스턴스 삭제
Next를 호출 할 때 마다, 첫 번째 인스턴스를 시작으로 다음 인스턴스 참조 값을 차례대로 반환
더 이상 반환 값이 없을때는 NoSuchElementException 예외를 발생시킨다.
While(itr.hasNext()){
Str = itr.next();
}
hasNext는 반환할 대상이 있는지 미리 확인하는 메소드이다. 반환할 인스턴스가 있으면 true, 없으면 false. Next 호출 이전에 hasNext를 호출하여 next 호출의 성공 가능성 확인
for - each문 보다 반복자를 사용하면 중간에 삭제 가능
for (Iterator itr = list.iterator(); itr.hasNext();){
if (itr.next().equals("Box")){
itr.remove();
}
}
next가 호출되 때마다 가르키는 대상이 다음 인스턴스로 옮겨진다. 이 반복자를 원하는 때에 다시 첫 인스턴스를 가리키게 하려면, 다시 반복자를 얻으면 된다.
while(itr.hasNext()){
System.out.println(itr.next());
System.out.println();
itr = list.iterator();
String str;
while (itr.hasNext()){
str = itr.next();
if (str.equals("Box")){
itr.remove();
}
itr = list.iterator();
while (itr.hasNext()){
System.out.println(itr.next());
System.out.println();
}
}itr = list.iterator -> 다시 반복자 획득
foreach 문도 반복자를 이용하는 코드로 변경 가능
for (Iterator itr = list.iterator(); itr.hasNext();){
배열보다는 컬랙션 인스턴스가 좋다 (컬랙션 변환)
배왈과 ArrayList는 특성이 유사. 배열을 기반으로 인스턴스를 저장. 대부분의 경우 배열보다 ArrayList가 더 좋다. 첫번째 이유로, 인스턴스의 저장과 삭제 용이. 두번째는 반복자를 사용가능. 단 배열처럼 선언과 동시에 초기화를 할 수 없어서 초기 설정 값이 쫌 까다롭다.
List list = Arrays.asList(“”);
인자로 전달된 인스턴스들을 저장한 컬랙션 인스턴스의 생성 및 반환
단 생성된 컬랙션 인스턴스는 새로운 인스턴스의 추가나 삭제가 가능하다. 새로운 인스턴스의 추가나 삭제가 필요한 상황이라면, 생성자 기반으로 ArrayList 인스턴스를 생성해야 한다.
또한 생성자의 매개변수 선언에 <? Extends E>가 등장한다. 덧붙여서 매개변수 c로 전달된 컬랙션 인스턴스에서 참조 값만 가능
Public ArrayList(Collection<? Extends E> c)
Collection을 구현한 컬랙션 인스턴스를 인자로 전달받는다.
E는 인스턴스 생성 과정에서 결정되므로 무엇이든 가능
C로 전달된 컬랙션 인스턴스에서는 참조만 가능
ArrayList 인스턴스를 생성하면, 생성자로 전달된 컬랙션 인스턴스에 저장된 모든 데이터가 새로 생성된 ArrayList 인스턴스에 복사.
public class Main4 {
public static void main(String[] args) {
List list = new ArrayList<>(Arrays.asList("Toy", "Box", "Robot"));
list = new ArrayList<>(list);
for (Iterator<String> itr = list.iterator(); itr.hasNext();) {
System.out.println(itr.next());
System.out.println();
}
for (Iterator<String> itr = list.iterator(); itr.hasNext();){
if (itr.next().equals("Box")){
itr.remove();
}
}
list = new LinkedList<>(list);
for (Iterator<String> itr = list.iterator(); itr.hasNext();){
System.out.println(itr.next());
System.out.println();
}
}}
대다수 컬랙션 클래스들은 다른 컬랙션 인스턴스를 인자로 전달받는 생성자를 가지고 있어서, 다른 컬래션 인스턴스에 저장된 데이터를 복사. -> 새로운 컬랙션 인스턴스를 생성
따라서 ArrayList 인스턴스를 사용하다 연결리스트 자료구조 특성이 필요하다면, LinkedList 인스턴스를 생성하면 된다.
list = new LinkedList<>(list);
for (Iterator itr = list.iterator(); itr.hasNext();){
System.out.println(itr.next());
System.out.println();
}
}
}
linkedList가 for문 iter 순환.
기본 자료형 데이터의 저장과 참조
컬래션 인스턴스도 기본 자료형의 값은 저장하지 못한다. 그러나 래퍼 클래스라면, 저장 및 참조가 가능. 이 과정에서 오토 박싱으로 인해 자연스로운 코드가 된다.
public class Main5 {
public static void main(String[] args) {
LinkedList list = new LinkedList<>();
list.add(10);
list.add(20);
list.add(30);
int n;
for (Iterator<Integer> itr = list.iterator(); itr.hasNext();) {
n = itr.next();
System.out.println(n);
}
System.out.println();
}}
연결리스트만 갖는 양뱡향 반복자.
Iterator 메소드의 호출을 통해서 반복자를 얻을 수 있다. List 인스턴스들만 얻을 수 있는 양방향 반복자라는 것이 있는데, List의 다음 메소드 호출을 통해 얻을 수 있다.
Public ListIterator listIterator()
ListIterator 는 Iterator를 상속
위 메소드가 반환하는 반복자는 양방향 이동 가능. 이는 배열이나 연결리스트와 같은 자료구조 특성상 가능한 일.
public class Main6 {
public static void main(String[] args) {
List list = new ArrayList<>(Arrays.asList("Toy", "Box", "Robot"));
list = new ArrayList<>();
ListIterator<String> itr = list.listIterator();
String str;
while (itr.hasNext()){
str = itr.next();
System.out.println(str);
if (str.equals("Toy")){
itr.add("Toy2");
}
}
System.out.println();
while (itr.hasNext()){
str = itr.previous();
System.out.println(str);
if (str.equals("Robot")){
itr.add("Robot2");
}
}
for (Iterator<String> itr1 = list.listIterator(); itr1.hasNext();){
System.out.println(itr1.next());
System.out.println();
}
}}
이 예제에서는 왼쪽에서 오른쪽, 다시 오른쪽에서 왼쪽으로 이동하면서 중간에 add 메소드를 호출하여 인스턴스를 추가로 저장.
ListIterator itr = list.listIterator();
양방향 반복자 획득
Set 인터페이슬 구현하는 컬랙션들
Set을 구현하는 클래스의 특성과 HashSet 클래스
Set
저장 순서가 유지
중복 허용 X
List 구현하는 컬랙션 인스턴스에 저장된 데이터를 출력 -> set 이용하면, 순서 중복 허용 X
public class Main7 {
public static void main(String[] args) {
Set set = new HashSet<>();
set.add("Toy");
set.add("Robot");
set.add("Box");
set.add("Robot");
System.out.println(set.size());
for (Iterator<String> itr = set.iterator(); itr.hasNext();){
System.out.println(itr.next());
System.out.println();
}
for (String s:
set) {
System.out.println(s);
System.out.println();
}
}}
순서 유지 X & 중복 저장 X
class Num{
private int num;
public Num(int n){
num = n;
}
@Override
public String toString(){
return String.valueOf(num);
}
@Override
public int hashCode(){
return num % 3;
}
@Override
public boolean equals(Object obj) {
if (num == ((Num)obj).num){
return true;
} else {
return false;
}
}}
public class Main8 {
public static void main(String[] args) {
HashSet set = new HashSet<>();
set.add(new Num(7799));
set.add(new Num(9955));
set.add(new Num(7799));
System.out.println(set.size());
for (Num n:
set) {
System.out.println(n.toString());
System.out.println();
}
}}
저장한 두개 Num은 같은 값으로 인식 할 수 있지만, 서로 다른 값
Hashset의 판단하는 동일 인스턴스의 기준은 Object 클래스에 정의 되어 있는 다음 두 메소드의 호출 결과를 근거로 판단
해쉬 알고리즘과 hashCode 메소드
HashSet 탐색 과정
Object 클래스에 정의된 hashCode 메소드의 반환값을 기반으로, 부류 결정
Equals 메소드를 호출하여 동등비교
HashSet set = new HashSet<>();
set.add(new Num(7799));
set.add(new Num(9955));
set.add(new Num(7799));
Object 클래스에 정의 되어 있는 hashCode와 equals 메소드는 인스턴스가 저장된 주소값을 기반으로 반환 값이 만들어지고, 정의
인스턴스가 다르면 Object 클래스의 hashCode 메소드는 다른 값을 반환
인스턴스가 다르면 Object 클래스의 equals 메소드는 false
@Override
public String toString(){
return String.valueOf(num);
}
@Override
public int hashCode(){
return num % 3;
}
@Override
public boolean equals(Object obj) {
if (num == ((Num)obj).num){
return true;
} else {
return false;
}
}
HashSet 인스턴스에는 동일한 문자열을 지니는 String 인스턴스가 둘 이상 저장되지 않는다.
hashCode 메소드의 다양한 정의
class Car{
private String name;
private String color;
public Car(String name, String color) {
this.name = name;
this.color = color;
}
@Override
public String toString(){
return name + color;
}
@Override
public int hashCode() {
return (name.hashCode() + color.hashCode());
}
@Override
public boolean equals(Object obj){
String n = ((Car) obj).name;
String c = ((Car) obj).color;
if (name.equals(n) && color.equals(c)){
return true;
} else {
return false;
}
}}
public class Main9 {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add(new Car("HY_MD_301", "RED"));
set.add(new Car("HY_MD_302", "Black"));
set.add(new Car("HY_MD_303", "Yellow"));
System.out.println(set.size());
for (Car car:
set) {
System.out.println(car.toString());
}
}}
메소드의 매개변수 선언에는 가변인자 선언이라는 것이 있는데 이는 전달되는 인자으 ㅣ수를 메소드 호출 시마다 달리할 수 있는 선언.
Hash 메소드를 이용하면 위 예제의 hashCode 메소드를 다음과 같이 오버라이딩
@Override
public int hashCode() {
return (name.hashCode() + color.hashCode());
}
<문제>
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name + (age);
}
@Override
public int hashCode() {
return name.hashCode() + (age % 7);
}
@Override
public boolean equals(Object obj) {
Person p = (Person)obj;
if ((name.equals(p)) && (p.age == age)){
return true;
} else {
return false;
}
}}
public class Main10 {
public static void main(String[] args) {
HashSet set = new HashSet<>();
set.add(new Person("Hwang", 20));
set.add(new Person("Kim", 20));
set.add(new Person("Lee", 20));
System.out.println(set.size());
System.out.println();
}
}
TreeSet
트리는 자료구조를 기반으로 인스턴스를 저장
public class Main11 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet<>();
treeSet.add(2);
treeSet.add(3);
treeSet.add(4);
treeSet.add(5);
System.out.println(treeSet.size());
for (Integer n:
treeSet) {
System.out.println(n.toString());
System.out.println();
}
for (Iterator<Integer> itr = treeSet.iterator(); itr.hasNext();){
System.out.println(itr.next().toString());
System.out.println();
}
}}
TreeSet 인스턴스가 정렬 상태를 유지하면서 인스턴스를 저장
인터페이스 비교 기준을 정의하는 Comparable 인터페이스 구현 기준
int comparTo(T o)
class Person2 implements Comparable{
private String name;
private int age;
public Person2(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString(){
return name + age;
}
@Override
public int compareTo(Person2 p) {
return this.age - p.age;
}}
public class Main12 {
public static void main(String[] args) {
TreeSet tree = new TreeSet<>();
tree.add(new Person2("Hwang", 22));
tree.add(new Person2("park", 22));
tree.add(new Person2("kim", 22));
for (Person2 p:
tree) {
System.out.println(p);
}
}}
Comparator 인터페이스를 기반으로 TreeSet 정렬 기준 제시
class Person3 implements Comparable{
private String name;
int age;
public Person3(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return name + age;
}
@Override
public int compareTo(Person3 o) {
return this.age - o.age;
}}
class PersonComparator implements Comparator {
@Override
public int compare(Person3 o1, Person3 o2) {
return o2.age - o1.age;
}}
public class Main13 {
public static void main(String[] args) {
TreeSet set = new TreeSet<>();
set.add(new Person3("Lim", 55));
set.add(new Person3("Kim", 55));
set.add(new Person3("Lee", 55));
for (Person3 p:
set) {
System.out.println(p);
}
}}
@Override
public int compareTo(Person3 o) {
return this.age - o.age;
}
}
문자열 길이 순으로 정렬
class StringCompartor implements Comparator{
@Override
public int compare(String o1, String o2) {
return o2.length() - o1.length();
}}
public class Main14 {
public static void main(String[] args) {
TreeSet set = new TreeSet<>();
set.add("adsedse");
set.add("1234567895");
for (String s:
set) {
System.out.println(s);
}
}}
<문제>
class Num1 implements Comparator{
@Override
public int compare(Integer o1, Integer o2) {
return o2.intValue() - o1.intValue();
}}
public class Main15 {
public static void main(String[] args) {
TreeSet set = new TreeSet<>();
set.add(30);
set.add(20);
set.add(10);
System.out.println(set);
}}
중복된 인터페이스를 삭제하려면
List 구현하는 컬랙션 클래스는 중복 삽입을 허용. 그런데 저장된 인스턴스들 중에서 중복 삽입된 인스턴스들을 하나만 남기고 지워야 한다고 가정.
public class Main16 {
public static void main(String[] args) {
List list = new ArrayList<>(Arrays.asList("Toy", "Box", "Toy","Box"));
ArrayList list1 = new ArrayList<>(list);
for (String s:
list1) {
System.out.println(s.toString());
System.out.println();
}
HashSet<String> set = new HashSet<>(list1);
list1 = new ArrayList<>(set);
for (String s:
list1) {
System.out.println(s.toString());
}
}}
중복을 제거 하기 위한 코드
HashSet set = new HashSet<>(list1);
list1 = new ArrayList<>(set);
Queue
Stack & Queue
스택은 가장 먼저 저장된 데이터가 가장 마지막에 빠져나가는 구조
LIFO -> 먼저 저장된 데이터가 마지막에 나간다.
큐는 들어간 순으로 빠져나간다.
FIFO -> 먼저 저장된 데이터가 먼저 빠져나간다.
Queue 인터페이스와 Queue 구현
Boolean add/ E remove/ E element (확인)
Boolean offer (넣기, 넣을 공간 부족시 false 반환)
E poll (꺼낼 값 없을 시 null)
E peek(확인하기, 확인할 값 없을 때 null 반환)
public class Main17 {
public static void main(String[] args) {
Queue queue = new LinkedList<>();
queue.offer("Box");
queue.offer("Toy");
queue.offer("Robot");
System.out.println(queue.peek());
System.out.println(queue.poll());
System.out.println(queue.poll());
System.out.println(queue.peek());
System.out.println(queue.poll());
}}
Stack 구현
Stack은 동기화된 클래스로 멀티 쓰레드 환경에서는 유리하지만, 그만큼 성능 저하 발생. 때문에 덱 이라는 자료구조가 포함되었다. 덱의 경우 양쪽 끝에서 넣을 수도 있고 빼는 것 또한 가능하다. 또한 Deque의 경우 꺼낼 값이 없거나 공간이 부족해서 넣지 못할 때 예외를 발생 시키는 것이 아니라 null 값 반환
public class Main18 {
public static void main(String[] args) {
Deque dq = new ArrayDeque<>();
dq.offerFirst("1.Box");
dq.offerFirst("2.Box");
dq.offerFirst("3.Box");
System.out.println(dq.pollFirst());
System.out.println(dq.pollFirst());
System.out.println(dq.pollFirst());
}}
Deque의 경우 ArrayDeque 또는 LinkedList로 구성
interface DIStack{
public boolean push(E item);
public E pop();
}
class DCStack implements DIStack{
private Deque deq;
public DCStack(Deque<E> deq) {
this.deq = deq;
}
@Override
public boolean push(E item) {
return deq.offerFirst(item);
}
@Override
public E pop() {
return deq.pollFirst();
}}
public class Main19 {
public static void main(String[] args) {
DIStack stack = new DCStack<>(new ArrayDeque<>());
stack.push("Box");
stack.push("1Box");
stack.push("2Box");
System.out.println(stack.pop());
System.out.println(stack.pop());
System.out.println(stack.pop());
}}
interface DIStack{
public boolean push(E item);
public E pop();
}
배열 기반 스택이 생성
DIStack stack = new DCStack<>(new ArrayDeque<>());
리스트 기반의 스택 생성
Map <K, V> 인터페이스를 구현하는 컬랙션 클래스
Key – Value 방식의 데이터 저장, HashMap
Key는 실질적 데이터가 아니다. 대신에 데이터 value를 찾는 지표가 된다.
Map<K, V>를 구현하는 클래스는 Value를 저장할 때 이를 찾을 때 사용하는 Key도 함께 저장하는 구조. 때문에 Key는 중복 X, Value는 Key 만 다르다면 중복 가능
public class Main20 {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(45, "a");
map.put(46, "b");
map.put(47, "c");
System.out.println(map.get(45));
System.out.println(map.get(46));
System.out.println(map.get(47));
System.out.println();
map.remove(46);
System.out.println(map.get(46));
}}
HashMap의 순차적 접근
Iterable 인터페이스를 구현하고 있지 않아. For-each문을 통해서 반복자를 통해서 순차적 접근이 가능. 또한 Map에는 set을 구현하는 컬렉션 인스턴스를 생성 하고, Key를 담아서 반호나
public class Main21 {
public static void main(String[] args) {
HashMap<Integer, String> map = new HashMap<>();
map.put(45, "a");
map.put(46, "b");
map.put(47, "c");
Set<Integer> ks = map.keySet();
for (Integer n:
ks) {
System.out.println(n.toString());
}
for (Integer s:
ks) {
System.out.println(map.get(s).toString());
}
for (Iterator<Integer> itr =ks.iterator(); itr.hasNext();) {
System.out.println(map.get(itr.next()));
System.out.println();
}
}}
TreeMap의 순차적 접근
HashMap과 구조는 유사. 단 정렬상태를 유지하고 있다.
public class Main22 {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(45, "a");
map.put(46, "b");
map.put(47, "c");
Set<Integer> ks = map.keySet();
for (Integer n:
ks) {
System.out.println(n.toString());
}
for (Integer s:
ks) {
System.out.println(map.get(s).toString());
}
for (Iterator<Integer> itr = ks.iterator(); itr.hasNext();) {
System.out.println(map.get(itr.next()));
System.out.println();
}
}}
인스턴스에 따라 반복자는 달라진다.
class Age implements Comparator{
@Override
public int compare(Integer o1, Integer o2) {
return o2.intValue() - o1.intValue();
}}
public class Main23 {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(45, "a");
map.put(46, "b");
map.put(47, "c");
Set<Integer> ks = map.keySet();
for (Integer n:
ks) {
System.out.println(n.toString());
}
for (Integer s:
ks) {
System.out.println(map.get(s).toString());
}
for (Iterator<Integer> itr = ks.iterator(); itr.hasNext();) {
System.out.println(map.get(itr.next()));
System.out.println();
}
}}
Compartor를 사용해 정렬 기준 변경 가능,
