포인터의 사용 이유
포인터를 사용하면 간결하고 효율적인 표현과 처리가 가능하고 더 빠른 기계어 코드를 생성할 수 있으며, 복잡한 자료구조 (배열, 구조체 등)와 함수에 쉬운 접근이 가능하다. 또한 포인터를 사용하지 않았을 때 코드로 표현할 수 없는 경우가 생길 수 있다.
포인터는 메모리의 주솟값을 저장한다.
포인터는 변수의 형태로 32비트 시스템에서는 4바이트 크기를 가지고 64비트 시스템에서는 8바이트 크기를 가진다.
포인터의 장점
메모리에 직접 접근이 가능
call by ref 방식으로 불필요한 복사를 생략할 수 있다
배열, 구조체 등의 복잡한 자료 구조와 함수에 쉽게 접근 가능
메모리 동적 할당이 가능
스마트 포인터 사용 이유
스마트 포인터는 일반 포인터처럼 생겼지만, 일반 포인터보다는 똑똑한 객체이다. 이는 무엇을 의미하는가?
일반 포인터처럼 보이기 위해서 스마트 포인터는 포인터가 가진 인터페이스를 가져야 한다. 포인터 값이 접근하기 위한 operator *와 포인터에 접근하기 위한 operator ->를 지원해야 한다. 서로 다른 무엇인가와 동일하게 보이는 객체를 Proxy 객체 혹은 그냥 Proxy라고 부른다. Proxy 패턴과 사용처는 The Design Pattern과 Pattern Oriented Software Architecture에 설명되어 있다.
일반 포인터보다 똑똑하기 위하여 스마트 포인터는 일반 포인터가 하지 못하는 일을 할 수 있어야 한다. C++ (혹은 C) 프로그램에서 가장 빈번히 발생하는 버그는 포인터와 메모리 관리에 관련되어 있다. dangling 포인터, 메모리 누수, 할당 실패 등에 관련된 버그들이다. 스마트 포인터를 이용하여 이런 버그를 줄일 수 있다.
스마트 포인터는 포인터를 operator overload로 접근할 수 있는 클래스 자료형이다.
왜 사용해야 하는가?
자동해제: 스마트 포인터를 사용할 때는 delete를 명시적으로 호출할 필요가 없으므로 메모리 해제에 대해서는 잊어도 된다.
자동 initialization : nullptr로 초기화 시키지 않아도 된다. 디폴트 생성자가 자동으로 처리해준다.
Dangling 포인터 : 이미 삭제된 객체를 가리키고 있는 포인터를 의미한다.
스마트 포인터를 사용하면 이러한 dangling pointer 문제에 대해서 자유로울 수 있다.
가비지 컬렉션 : 일부 언어들은 가비지 컬렉션 기능을 제공하지만 c++은 그렇지 못하다. 스마트 포인터는 가비지 컬렉션 용도로 사용될 수 있다. 가장 단순한 가비지 컬렉션 기법은 참조 카운트 혹은 참조 연결 방법이다. 스마트 포인터를 이용하는 경우 이러한 가비지 컬랙션을 좀 더 정교하게 구현할 수 있따.
컴파일러 cpp -> obj 링커 obj library -> exe
컴파일러의 역할
- 컴파일러는 먼저 코드가 rule을 따르는지 검사한다
- 다음으로 컴파일러는 c++ 소스코드를 machine language로 바꾼다
이를 object file이라고 칭한다
링커의 역할
- 링커는 컴파일러가 생성한 하나 혹은 복수의 obj 파일을 취합하여 하나의 executable 프로그램으로 만든다 (.exe)
- 링커는 개체 파일 뿐 아니라 library file도 연결할 수 있다.
라이브러리 파일은 다른 프로그램에서 재사용하기 위해 "패키징"된 미리 컴파일된 코드 모음이다. - 링커는 모든 파일간 종속성이 올바르게 해결되었는지 확인한다
이러한 종속성이 해결되지 않으면 linker error가 발생한다. linking process가 중단된다
링커가 obj파일과 library 파일을 linking하고나면 executable file(.exe)가 만들어진다.
빌드
c프로그램의 개발 과정
1. 소스코드 작성
2. 전처리기
3. 컴파일
4. 링크
5. 실행
6. 디버깅 -> 1
- 전처리기
프로그래머가 작성한 소스 파일을 컴파일하기 위한 소스파일로 변환하는 단계.
주석을 제거하고 다른 파일을 포함(#include)하거나, 소스 파일 내의 특정 문자열을 다른 문자열로 대치하는 일(#define)을 한다
전처리 문장은 '#'으로 시작하므로 쉽게 구별이 가능하다.
#include는 주로 header file을 포함시키는 경우가 가장 많은데,
C언어에서는 항상 사용하는 <stdio.h>가 헤더파일의 예이다.
visual studio에서는 전처리/컴파일/링크를 빌드라는 하나의 과정으로 수행해준다.
컴파일 에러 런타임 에러
정말 간단하게 실행 부터 안되면 컴파일 에러
실행됐다가 에러가 나면서 꺼지면 런타임 에러
문법 실수 컴파일 에러
런타임 에러는 올바르지 못한 참조, 접근 등
얕은 복사 vs 깊은 복사
얕은 복사의 경우 원본 개체의 모든 변수 데이터를 단순 복제하여 개체를 만든다.
만약 이때 원본 개체에 동적으로 할당된 메모리를 가르키는 포인터가 존재한다면 포인터의 value를 그대로 복사하는 경우 문제가 발생할 수 있다
따라서 일반적으로 동적으로 할당된 경우 Deep copy를 수행해야 한다
deep copy는 명시적으로 복사 생성자를 정의해서 달성할 수 있다.
동적 메모리를 복사하는 경우 새로이 할당하는 등의 방법으로 복사를 진행할 수도 있다.
스마트포인터
auto포인터, unique 포인터, shared 포인터, weak 포인터
1. auto_ptr
가장 기초적인 스마트 포인터, 하지만 현대에는 사용하지 않는다
단순히 포인터가 소멸하면 가리키는 대상을 삭제한다
따라서 얕은 복사가 이뤄진 경우, 다른 포인터는 삭제된 데이터를 가리키게 되는 문제가 발생한다
- shared_ptr
포인팅하는 객체에 대한 포인팅 횟수를 카운트한다.
여러 포인터가 가리키고 있을 땐, 하나의 포인터가 소멸되어도 데이터는 해제되지 않는 것이다.
그리고 마지막 포인터마저 소멸되면 이때 데이터가 해제된다
- unique_ptr
shared_ptr과 달리, 단 하나의 포인터만이 데이터를 가리킬 수 있다.
따라서 사전에 얕은 복사의 가능성을 차단한다.
만약 유일하게 가리키고 있는 포인터가 소멸한다면 데이터가 해제될 것이다.
std::unique_ptr의 특징
-
복사를 못한다. copy semantics는 안됨
: 소유권은 오로지 한 곳에서만 가질 수 있기 때문에 단순히 res2 = res1 와 같은 copy assignment는 불가능 -
이동만 할 수 있다. move semantics
: res2 = std::move(res1)
res1이 r-value로 바뀐다
res1은 소유권이 박탈 되어 이제 아무 객체도 가리키지 않는 nullptr이 되고
res2는 res1이 소유하고 있던 객체의 소유권을 물려받게 된다.
c++11에서는 move semantics를 위해 두가지 새로운 function이 정의되어 있다.
move constructor와 move assignment operator이다.
copy constructor와 copy assignment의 목적이 object의 copy를 만들어 다른 object를 만드는 것에 있었다면, move constructor와 move assignment는 ownership을 옮기는데에 그 목적이 있다
move constructor와 assignment를 정의하는 것은 copy류와 비슷하다
그러나 copy가 l-value ref로 parameter를 설정하는데에 반해
move는 r-value ref로 parameter를 설정한다
std::move
std::move는 l-value를 r-value처럼 다루고 싶을 때 언제든지 사용할 수 있다
이는 보통 move semantics를 호출하기 위함이 목적이다
move semantics는 rvalue-ref로 constructor와 assignment operator overloading이 되어 있다.
- weak_ptr
shared_ptr이 가리키는 대상에 참조형식으로 포인팅할 수 있지만, 참조 카운터에 영향을 주지 않는다.
즉 데이터 삭제시에 weak_ptr이 포인팅하고 있는 여부는 문제가 되지 않는다
이는 순환참조의 문제를 해결하는데 사용한다고 한다.
https://blog.naver.com/young_rnr/222066134379
위의 링크에 자세하게 설명되어 있다.
weak_ptr을 통해서 순환참조로 인한 메모리 누수를 방지할 수 있다
rvalue vs lvalue
lvalue, LValue라고해서 수정가능한 값을 의미한다. 대입 연산 수행시 좌측에 위치한다.
해당 연산을 수행하고나서도 값이 사라지지 않는다.
rvalue, RValue로 수정 불가능한 값을 의미하고 대입 연산 수행시 우측에 위치한다.
임시로 존재하는 값이기 때문에 연산을 수행하고 난 뒤에는 더이상 존재하지 않는다.
왼쪽과 오른쪽에 모두 사용될 수 있으면 lvalue, 오른쪽에만 사용할 수 있으면 rvalue라고 이해하면 쉽다.
lvalue는 단일 표현식 이후에도 없어지지 않고 지속되는 객체입니다. 그러므로 const 타입을 포함한 모든 변수는 Lvalue입니다.
반면에 Rvalue는 표현식이 종료된 이후에는 더 이상 존재하지 않는 임시적인 값입니다. 상수 또는 임시객체는 Rvalue라고 할 수 있겠네요.
#include <iostream>
#include <string>
using namespace std;
int main()
{
int x = 3;
const int y = x;
int z = x + y;
int* p = &x;
cout << string("one");
++x;
x++;
}위 식에서 Rvalue는 3, x + y, &x, string("one") , x++입니다.
여기서 ++x와 x++의 rvalue, lvalue가 헷갈리긴 합니다.
참고로 &연산자는 Lvalue를 요구하기 때문에 판별할 때 사용할 수 있습니다.
&(++x);
&(x++); // error C2102: '&' requires l-value생각해보면 ++x는 증가된 x 자체를 리턴하지만 x++를 대입연산에 써보면 증가된 x가 아닌 원래 x 값을 return 한다.
이는 복사된 x 값이라고 생각할 수 있는 것이다.
Lvalue ref vs Rvalue ref
먼저 reference라는 것은 이미 존재하는 변수에 다른 이름을 할당하는 것외에 다른 기능은 없습니다.
참조는 잘 사용하면 프로그램안에서 임시 객체자 인자 값을 생성하면서 발생하는 복사 횟수를 줄일 수 있다.
또한 참조는 포인터와는 다르게 한번 initialize 되면서 참조하는 객체 이외에 다른 객체를 참조하도록 변경하거나 null로 수정할 수가 없습니다.
-lvaue 참조 : 이름이 있는 변수를 참조. &연산자 사용
-rvalue 참조 : 일시적인 객체를 참조, &&연산자 사용
call by value, call by ref
함수 호출 방법은 크게 두가지가 있다
call by value는 argument를 복사해서 가져오고
call by ref는 argument 원형을 그대로 참조한다.
함수를 호출할 때 복사라는 과정이 불필요하고 비효율적일 때가 있다. 이때 참조를 통해 효율성을 증대시킬 수 있는 것이다.
그러나 참조를 통해 불러온 parameter를 함수내에서 조작하다 문제를 발생시킬 수 있는 위험도 존재한다.
캐스팅
캐스트는 자료형간 또는 포인터간 형변환시 사용됩니다.
캐스트는 크게 implicit cast와 explicit cast 두 가지로 나눌 수 있습니다.
특별히 캐스트 연산자를 사용하지 않고 형변환이 이루어지는 경우를 implicit cast라고 합니다.
static_cast
정적 캐스트(static_cast)는 컴파일 시점에서 무결성을 검사하는데 이때, '허용'과 '컴파일러에 의한 값 변환' 이라는 두 가지 관점에서 이루어 집니다.
형변환에 대한 타입체크를 run-time에 하지 않고, compile 타임에 정적으로 수행합니다.
const_cast
const_cast는 표현식의 상수성(const)를 없애는 데 사용됩니다.
reinterpret_cast
reinterpret_cast는 어떠한 포인터 타입도 어떠한 포인터 타입으로든 변환이 가능합니다.
-
어떠한 정수 타입도 어떠한 포인터 타입으로 변환이 가능하고, 그 역(포인터 타입->정수 타입)도 가능합니다.
-
char -> int 또는 int 에서 char 로 또는 any_class 에서 another_Class* 로도 가능합니다. 얼핏 봤을 때 상당히 자유롭고 강력한 캐스터 같지만, 특수한 케이스가 아니면 사용하지 않는 것을 권합니다.
우선, 전통적인 캐스팅의 개념에서 벗어날 수 있는 포인터 변환 등이 reinterpret_cast를 씀으로써 강제 형변환되기 때문입니다.
dynamic_cast
dynamic_cast는 런타임에(동적으로) 상속 계층 관계를 가로지르거나 다운캐스팅시 사용되는 캐스팅 연산자 입니다. 기본 클래스 객체에 대한 포인터(*)나 레퍼런스(&)의 타입을 자식 클래스, 혹은 형제 클래스의 타입으로 변환 할 수 있습니다. 캐스팅의 실패는 NULL(포인터)이거나 예외(참조자)를 보고 판별할 수 있습니다. 상속 관계에 있지만 virtual 멤버 함수가 하나도 없다면 다형성을 가진게 아니라 단형성이며, dynamic_cast는 다형성을 띄지 않은 객체간 변환은 불가능하며, 시도시 컴파일 에러가 발생합니다. 또한 RTTI에 의존적이므로 변환 비용이 비쌉니다.
static_cast VS. dynamic_cast (어떨때 써야 하나)
<static_cast> 정적으로 형변환을 해도 아무런 문제가 없다는 것은 이미 어떤 녀석인지 알고 있을 경우에 속할 것이고, <dynamic_cast> 동적으로 형변환을 시도해 본다는 것은 이 녀석의 타입을 반드시 질의해 봐야 된다는 것을 의미합니다. RTTI를 해야 하는 경우엔 dynamic_cast를 이용해 런타입의 해당 타입을 명확히 질의해야 하고, 그렇지 않은 경우엔 static_cast를 사용하여 변환 비용을 줄이는 것이 좋습니다.
// 비행기에 여러 직군의 사람들이 탑승했다.
// 한 승객이 갑자기 급성 맹장염에 걸려 의사가 급하게 수술을 해야 한다.
class Passenger {...};
class Student : public Passenger
{
...
void Study();
};
class Teacher : public Passenger
{
...
void Teach();
};
class Doctor : public Passenger
{
...
void Treat();
void Operate();
};
int main()
{
typedef vector<Passenger *> PassengerVector;
PassengerVector passengerVect;
Passenger* pPS = new Student();
if ( pPS )
{
passengerVect.push_back( pPS );
// 비행기 타자마자 공부한다고 치고~
// pPS가 명확하게 어느 클래스의 인스턴스인지 알고 있다.
// 이 경우엔 굳이 비용이 들어가는 dynamic_cast가 아닌, static_cast를 쓰는게 낫다.
Student* pS = static_cast<Student *>( pPS );
pS->Study();
}
Passenger* pPT = new Teacher();
if ( pPT )
{
passengerVect.push_back( pPT );
}
// Doctor 역시 비슷하게 추가.
...
// 응급 환자 발생. passengerVect 중 의사가 있다면 수술을 시켜야 한다.
PassengerVect::iterator bIter(passengerVect .begin());
PassengerVect::iterator eIter(passengerVect .end());
for( ; bIter != eIter; ++bIter )
{
// Passenger 포인터로 저장된 녀석들 중 누가 의사인지 구분해야 한다.
// 런타임 다형성 체크에 의해 Doctor가 아닌 녀석들에 대한 형변환 결과는 NULL
Doctor* pD = dynamic_cast<Doctor *>(*bIter);
if ( pD )
{
pD->Operate();
}
}
}위의 예시를 보면 static_cast와 dynamic_cast를 어떻게 사용하는지 알 수 있다.
RTTI
RTTI는 Run Time Type information이라 하며,
프로그램 실행 중에 실시간으로 데이터의 타입을 얻어올 때 사용하는 방법입니다.
템플릿
템플릿이란?
- 함수나 클래스를 개별적으로 다시 작성하지 않아도, 여러 자료 형으로 사용할 수 있도록 하게 만들어 놓은 틀.
- 함수 템플릿(Function Template)와 클래스 템플릿(Class Template) 로 나누어집니다.
c++에서는 다형성의 실현을 위해 함수 오버로딩이 가능하다. 따라서 함수의 이름이 같지만 parameter를 다르게 사용할 수 있다.
이러한 맥락으로 타입에 대한 유현한 대처를 가능하게 하는 것이 템플릿이다.
함수뿐만이 아닌 클래스에도 템플릿은 적용이 가능하다
네임스페이스
두 헤더파일에 동일한 이름과 parameter로 정의된 함수가 존재한다
이를 main 함수에서 include 시킨다음 해당 함수를 호출하면 모호성이 발생해 컴파일러 에러가 발생한다
이러한 이름 충돌 문제를 해결하기 위해 네임스페이스 개념이 도입되었다.
원래은 전역 namespace에 정의된 함수나 변수를 지정된 namespace로 옮겨 이러한 충돌문제를 해결하고 각 namespace에 접근할 때는 스코프 분석 연산자(::)를 통해 접근할 수 있다.
functor (함수객체)
클래스에 ()연산자를 오버로딩하게 되면 object를 함수처럼 사용할 수 있다
예시
#include <iostream>
using namespace std;
class Adder
{
public:
int operator()(const int &n1, const int &n2)
{
return n1 + n2;
}
}
int main()
{
Adder adder;
cout << adder(1, 3) << endl;
}
함수포인터
함수 포인터는 말그대로 함수의 포인터 타입이다.
함수포인터의 가장 유용한 기능은 함수를 다른 함수에 전달하는 것이다. 다른 함수에 대한 argument로 사용되는 함수를 call back 함수라고 부르기도 한다.
(call back 함수가 무엇인지 잘 기억하도록!!)
sorting 같은거 할 때 오름차순 내림차순으로 할지 정할때 사용하고는 한다.
람다(Lambda)
c++에는 람다라는 문법이 존재합니다
앞서 functor와 함수 포인터를 설명했는데
람다는 functor, 함수 포인터의 장점만을 가지고 있습니다.
-
함수 객체와는 다르게 class를 선언할 필요가 없다 (코드 길이 감소)
-
함수 포인터의 단점은 "함수의 inline화가 불가능하다"입니다. 하지만 람다는 "함수의 인라인 화가 가능합니다"
람다 기본 모양과 사용법

첫 번째 [] : 캡처
두 번째 () : 매개변수 선언 부분 (생략 가능 - 매개변수 필요 없을 때)
세 번째 {} : 함수 동작 부분
네 번째 () : 함수 호출 시 인자 (생략 가능 - 호출 시에만 사용)
cout << [](int a, int b) {return a + b; } (10, 20);
auto l1 = [](int a, int b) {return a + b; };
cout << l1(50,50);출력은 30, 100이다
네번째 괄호는 위와 같이 사용하는 것이다.
람다는 함수 포인터와 마찬가지로 콜백함수에 쓰일 수 있다.
우리가 std::sort 함수에서 정렬을 위해서 3번째 매개변수로 함수를 넘겨주는 경우가 있습니다.
이렇게 함수는 필요한데 이번 한번 사용하고 땡처리되는 1회성 함수가 필요할 때 사용합니다.
즉, "함수가 필요한데 많이 쓰일 것 같진 않고, 애매~할 때" 사용합니다.
inline
C++에서의 함수 호출 과정
함수가 호출되면 우선 스택에 함수로 전달할 매개변수와 함께 호출이 끝난 뒤 돌아갈 반환 주소값을 저장하게 됩니다.
그리고서 프로그램의 제어가 함수의 위치로 넘어와 함수 내에 선언된 지역 변수도 스택에 저장합니다.
그때부터 함수의 모든 코드를 실행하게 되고, 실행이 전부 끝나면 반환값을 넘겨 줍니다.
그 후 프로그램의 제어는 스택에 저장된 돌아갈 반환 주소값으로 이동하여, 스택에 저장된 함수 호출 정보를 제거합니다.
이와 같은 일련의 함수 호출 과정이 함수마다 일어나게 됩니다.
인라인 함수(inline function)
위와 같이 C++에서 함수의 호출은 꽤 복잡한 과정을 거치므로, 약간의 시간이 걸리게 됩니다.
이때 함수를 실행하는 시간이 오래 걸린다면, 함수를 호출하는데 걸리는 시간은 전혀 문제가 되지 않습니다.
하지만 함수의 실행 시간이 매우 짧다면, 함수 호출에 걸리는 시간도 부담이 될 수 있습니다.
C++에서는 이러한 경우에 사용할 수 있는 인라인 함수(inline function)라는 것을 제공합니다.
인라인 함수는 호출될 때 일반적인 함수의 호출 과정을 거치지 않고, 함수의 모든 코드를 호출된 자리에 바로 삽입하는 방식의 함수입니다.
이 방식은 함수를 호출하는 데 걸리는 시간은 절약되나, 함수 호출 과정으로 생기는 여러 이점을 포기하게 됩니다.
따라서 코드가 매우 적은 함수만을 인라인 함수로 선언하는 것이 좋습니다.
함수 호출로 인한 오버헤드를 줄이기 위한 방법!!
함수를 실행하는데 오랜시간이 걸리면 오버헤드가 끼치는 영향은 미미하나 함수가 매우 빠르게 실행되는 경우라면 오버헤드가 차지하는 비중이 크므로 인라인 함수를 도입해 해결한다.
오버헤드란?
오버헤드란 프로그램의 실행흐름에서 나타나는 현상중 하나입니다. 예를 들어 , 프로그램의 실행흐름 도중에 동떨어진 위치의 코드를 실행시켜야 할 때 , 추가적으로 시간,메모리,자원이 사용되는 현상입니다.
콜스택 (call stack)
콜스택은 프로그램이 함수 호출(function call)을 추적할 때 사용하는 것이다.
stack에 실행 중인 함수를 쌓아나가면서
함수 내부에서 함수를 실행하면 stack에 쌓고 함수를 모두 실행하면 pop을 하는 형태로
그런데 무한재귀함수의 경우 stack의 정해진 용량을 초과해 push가 되면서 stack overflow가 발생하게 되는 것이다.
OOP 란
Object-Oriented Programming 의 약자로,
Procedural Programming (PP), 즉 절차지향 프로그래밍이 데이터 오퍼레이션에 필요한 기능이나 절차를 쓰는 형식이라면 객체 지향은 데이터와 기능을 가추고 있는 오브젝트(Object)를 만드는 역할을 한다.
객체 지향 프로그래밍을 사용하는 이유는
- OOP는 실행하는데 쉽고 빠르다.
- OOP는 프로그램에 필요한 구조를 보기 쉽게 재공한다.
- OOP는 C++코드를 보다 쉽게 관리, 수정 및 디버그를 할수있게 도와준다.
- OOP는 짧은 개발 시간과 적은 코드로 재사용 가능한 어플리케이션을 만들수있다.
OOP의 4가지 원리
1.캡슐화 (Encapsulation)
[정의]
- 데이터( 멤버변수 ), 기능( 메서드 ) 을 하나의 단위로 묶어놓음
- 데이터를 가리고 접근하기 위한 메서드만을 노출 ( 데이터 은닉 )
[사용]
- 클래스 사용자는 내부 구조 이해 X, 사용법만 알면 사용 가능하다.
- 사용자가 실수로 데이터를 바꾸지 못한게 한다.
2.상속성 (Inheritance)
[정의]
- 부모 클래스의 멤버를 재사용하여 자식 클래스에서도 사용하게
- 부모 클래스의 기능을 자식도 할 수 있게 하기 위해
[사용]
- 상속을 통해서
3.다형성 (Inheritance)
[정의]
- 한 클래스로부터 파생된 여러 클래스들이 다양한 형태를 가질 수 있다.
- 자식 클래스의 메서드 구현이 부모 클래스와 다르게 만들 수 있다.
[사용]
- 오버라이딩, 가상함수, 오버로딩
4.추상화 (Abstraction)
[정의]
- 부모 클래스 : 클래스가 구현할 기능들을 명시만 함 (순수 가상함수)
- 자식 클래스 : 명시된 기능들을 실제로 구현
[사용]
- 순수가상 함수를 사용하는 추상 클래스를 사용
- 추상 클래스는 개별적인 객체를 생성할 수 없다.
가상함수란?
가상함수는 부모 클래스에서 상속받을 클래스에서 재정의할 것으로 기대하고 정의해놓은 함수입니다. virtual이라는 예약어를 함수 앞에 붙여서 생성할 수 있으며 이렇게 생성된 가상함수는 파생 클래스에서 재정의하면 이전에 정의되었떤 내용들은 모드 새롭게 정의된 내용들로 교체됩니다.
주로 실행시간(runtime)에 함수의 다형성(polymorphism)을 구현하는데 사용된다.
가상함수는 실행시간(runtime)에 그 값이 결정된다.
가상함수 선언 규칙
-
클래스의 공개(public) 섹션에 선언합니다.
-
가상 함수는 정적(static)일 수 없으며 다른 클래스의 친구(friend) 함수가 될 수도 없습니다.
-
가상 함수는 실행시간 다형성을 얻기위해 기본 클래스의 포인터 또는 참조를 통해 접근(access)해야 합니다.
-
가상 함수의 프로토타입(반환형과 매개변수)은 기본 클래스와 파생 클래스에서 동일합니다.
-
클래스는 가상 소멸자를 가질 수 있지만 가상 생성자를 가질 수 없습니다.
예시
Parent 포인터에 Child 포인터를 주고난 후
virtual 선언 없이 함수를 호출하면 일반적으로
포인터의 형태에 따라서 함수 호출
그런데 virtual 선언이 되어 있다면
가상함수 테이블을 참조해 비록 parent 포인터에 담겨있으나 원 개체는 child 였으므로 child 함수를 호출함
예시 더 찾아볼 필요 있음
순수가상함수
virtual void foo() = 0;위와 같은 방식으로 순수가상함수를 설정할 수 있다.
함수의 정의가 이뤄지지 않고 선언만 이뤄진 것이다
이렇게 선언된 순수가상함수가 존재한다면 이를 추상클래스 (abstract class)라고 부른다.
또한 추상클래스는 객체로 만들지 못하고 상속으로써만 사용이 가능하다.
그리고 상속받은 자식 클래스는 무조건 해당 순수 가상함수를 override해서 재정의 시켜줘야만 한다.
다형성 (polymorphism)
https://forswdev.tistory.com/52
하나의 기호를 여러가지 의미로 사용하는 기술을 의미한다.
예를들어 오버로딩, 오버라이딩을 말할 수 있다.
오버라이딩vs오버로딩
함수 오버라이딩(functino overriding) 은 함수 오버로딩(overloading)과 살짝 다르다.
함수 오버로딩은 같은 이름의 다른 기능을 구현하는 것이었다면, 함수 오버라이딩은 같은 함수를 덮어 쓰는 것을 의미한다.
오버로딩 (overloading)
오버로딩은 같은 이름의 함수(메서드)를 여러개 정의해놓고 매개변수의 유형 또는 개수를 다르게 하여 다양한 유형의 호출에 대응하여 응답할 수 있다.
오버라이딩 (overriding)
멤버함수를 재정의 하는 오버라이딩.
자식클래스에서 필요에 의해 부모클래스로부터 상속받은 멤버 함수를 재정의해서 사용하는 것을 오버라이딩이라고 한다.
'override' keyword
오버라이딩을 의도하고 함수를 작성했는데
형태가 미묘하게 달라 오버라이딩의 의도가 실현되지 않을 수 있다
(ex. const를 빼먹는다던가)
따라서 오버라이딩을 의도하는 경우에 override라는 키워드를 입력해서
의도와 다르게 오버라이딩이 되지 않는 경우를 미연에 방지할 수 있다.
ex) https://seastar105.tistory.com/135?category=963553
override 키워드 사용의 조건
- 기반 클래스 함수가 반드시 가상 함수 이어야 한다
- 기반 함수와 파생함수의 이름이 반드시 동일해야 한다(소멸자 제외)
- 기반 함수와 파생함수의 const 성이 반드시 동일해야 한다
- 기반함수와 파생함수의 반환형식과 예외 명세가 호환되어야한다
- 멤버 함수들의 참조 한정자(reference qualifier)가 동일해야 한다.
'final' keyword
클래스 상속을 방지하거나, 더 이상 가상함수를 오버라이딩 하지 않겠다는 키워드 입니다.
함수에서 사용할 때 override와 마찬가지로 final도 가상함수에만 (virtual 키워드가 붙은 메서드류) 사용가능한 것입니다!!!
부모 클래스의 특정 멤버함수를 자식 클래스에서 재정의하지 못하도록 방지할 때 사용하거나, 부모 클래스를 자식 클래스에 상속 받을때 클래스 자체를 더 이상 상속이 불가능하게 하려고 할 때 쓰입니다.
final 키워드가 붙은 함수를 상속 받아서 사용하려 할 때는 컴파일 에러가 발생합니다.
class Car final { ... };위와 같이 클래스를 final로 만들어 줍니다
클래스를 final로 하면 다른 클래스에서 위 클래스를 상속받을 수가 없습니다. (컴파일 에러 발생)
물론 함수에도 사용할 수 있습니다.
void func() final;클래스를 상속불가로 만들거나 함수를 override 불가로 만듭니다
위처럼 멤버함수에 final 키워드를 설정하면
만약 public인 경우 자식 클래스에서 접근해 사용은 가능하나
overriding을 통해 가상함수의 재정의가 불가능하다는 것입니다.
class vs struct
c++에서 struct와 class의 차이점은 기본보기 설정(default)가 다른 것 밖에 없다
struct는 public, class는 private
둘다 데이터와 함수의 집합체임에는 동일하다.
다만 c에서 사용하는 struct와 c++에서 사용하는 struct는 차이가 있다고 합니다
c언에서 struct는 연관있는 데이터를 묶을 수 있기는 하지만 c++의 struct는 default access modifier를 제외하고는 기능적으로 동일하다
접근 지정자 (Access Modifiers)
public : 어디서든 접근가능
protected : 상속관계일 때 접근 가능
private : 해당 클래스에서만 접근 가능
protected는 해당 클래스 메소드와 상속을 받을 파생 클래스에서만 접근이 가능하다.
상속 접근 지정자에 따른 상속 형태
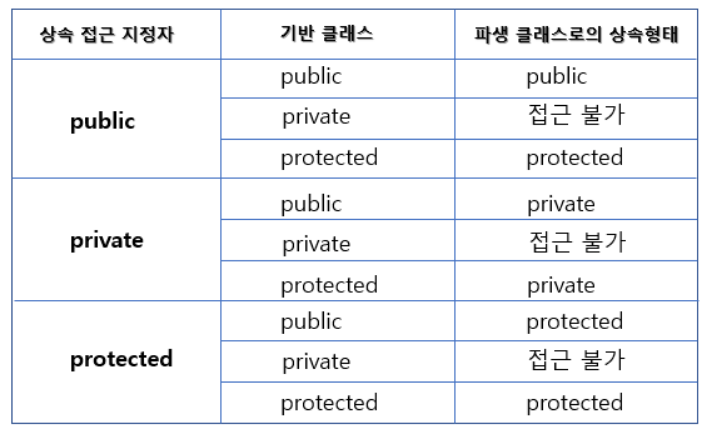
부모 클래스의 private 멤버들은 오직 부모 클래스에서만 접근이 가능하다.
public은 어디서든 접근이 가능하기 때문에 자식에서 접근이 가능하고
protected는 상속관계일 때 접근이 가능하다는 것
위의 표를 잘 기억하자
parameter vs argument
파라미터는 함수를 정의할 때 사용되는 변수를 의미한다
argument(인수)는 함수가 호출될 때 매개변수에 실제로 담기는 값을 의미한다.
캡슐화 (encapsulation)
같은 기능을 목적으로 작성된 코드, (데이터와 함수)를 하나로 묶는 것을 말하며 주로 클래스를 이용한다.
클래스 내에서 정의된 속성(Attribute)는 private로 은닉하고,
수행할 기능은 public으로 공개하여 외부에서 사용할 수 있도록 한다.
