우선 순위 큐는 큐 또는 스택과 같은 추상 자료형과 유사하지만 추가로 각 요소의 ‘우선순위’와 연관되어 있다.
스택은 가장 나중에 삽에 삽입된 요소를 먼저 추출하는 LIFO 자료형이다. 이와 달리 우선순위 큐는 특정 조건에 따라 우선순위가 가장 높은 요소가 추출되는 자료형이다.
위 말은 정렬 알고리즘을 사용하여 우선순위 큐를 만들 수 있다는 의미이다. n개의 요소를 정렬하는 데 S(n)의 시간이 든다고 할 때, 새 요소를 삽입하거나 삭제하는 데에는 O(S(n))시간 복잡도를 갖는다. 반면 우선순위가 가장 높은 값을 가져오는 데에는 맨 앞의 값을 가져오기만 하면 되므로 O(1)로 가능해진다. 대개 정렬에는 O(n log n)시간복잡도를 갖기 때문에 O(S(n))은 O(n log n)으로 나타낼 수 있다.
최단경로를 탐색하는 다익스트라 알고리즘에 주로 사용되며 힙 자료구조와도 연관이 깊다.
특히 python의 queue 모듈의 PriorityQueue의 경우에는 내부적으로 heap 자료구조인 heapq 모듈을 사용하여 구현되었으며, 스레드 안정성을 위해 오버헤드가 발생되기 때문에 코딩 테스트 준비를 위해서는 priority queue를 사용하기 보다는 heapq를 사용하는 편이 좋다.
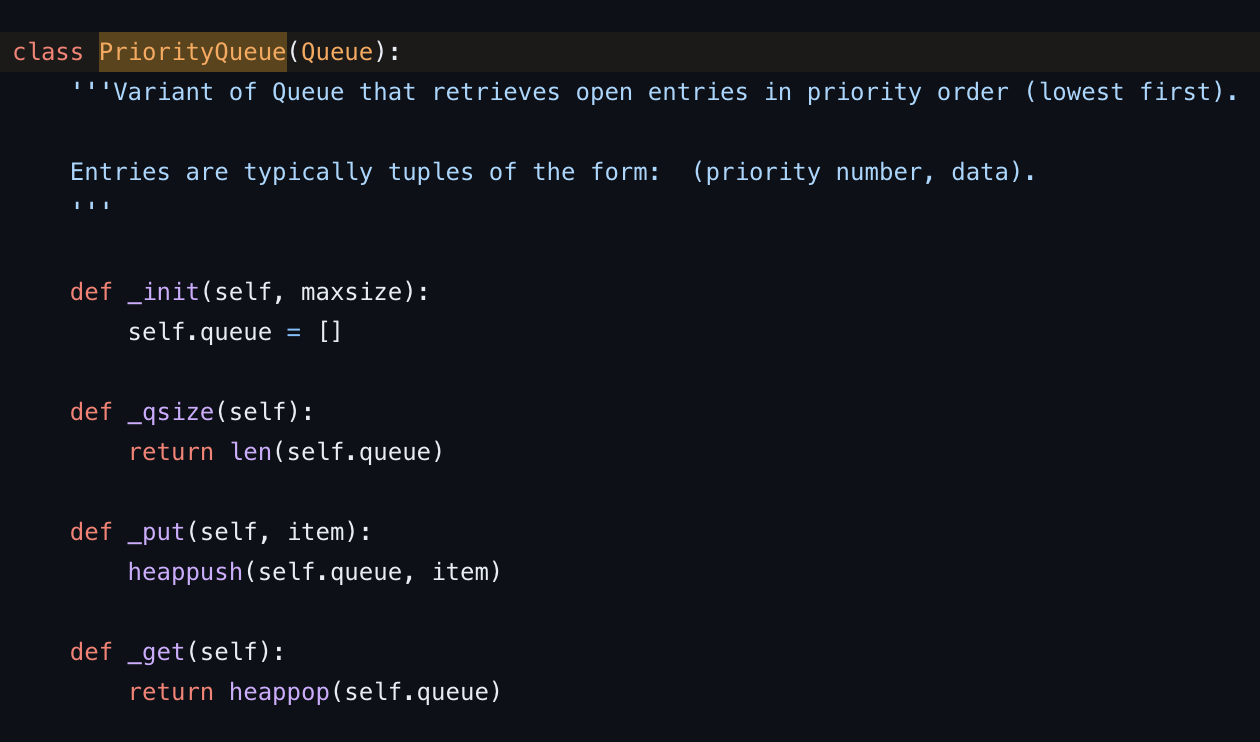
특히 프로그래머스 lv3 야근지수 문제의 경우 같은 알고리즘을 사용했음에도 불구하고 priority queue와 heapq 두 자료구조의 속도 차이만으로 효율성이 떨어지는 것을 확인 할 수 있었다.
https://velog.io/@iknow/lv3-야근-지수
