범주형 자료란?
범주형 자료는 수치로 측정이 불가능한 자료를 말한다.
예를 들어 성별,지역, 혈액형 등이 있다.
하지만 그렇다고 범주형 자료가 숫자로 표현이 불가능하다는 말은 아니다.
예를 들어 남녀 성별을 남자를 1 여자를 0으로 표현하면 숫자로 표현도니 범주형 자료라고 볼 수 있고,
수치형 자료인 나이를 만10~19세, 만20~29처럼 구간으로 나누어 준다면 수치형 자료를 범주형 자료로 변환하였다고 할 수 있다.
범주형 자료의 종류
범주형 자료에는 순위형 자료(Ordinal data), 명목형 자료(Norminal data)가 있다.
순위형 자료(Oridnal data)는 범주 사이의 순서에 의미가 있다.
Ex. 학점(A+,A,A-,...)
명목형 자료(Norminal data)는 범주 사이의 순서에 의미가 없다.
Ex. 혈액형(A,B,O,AB), MBTI
범주형 자료의 표현
범주형 자료들은 도수분포표 또는 막대그래프로 나타낼 수 있다.
도수(Frequency) 각 범주에 속하는 관측값의 개수 value_counts()
상대도수(Relative Frequency) 도수를 자료의 전체 개수로 나눈 비율 value_counts(normalize=True)
도수분포표
강의 만족도 설문(100명 조사)
| 범주 | 도수 | 상대도수 | 누적 상대도수 |
|---|---|---|---|
| 매우 만족 | 30 | 0.3 | 0.3 |
| 만족 | 10 | 0.1 | 0.4 |
| 보통 | 30 | 0.3 | 0.7 |
| 불만족 | 15 | 0.15 | 0.85 |
| 매우 불만족 | 15 | 0.15 | 1.00 |
막대그래프
plt.bar()를 사용하여 그래프로 출력 가능.
범주형 자료의 전 처리
순서에 의미가 없는 명목형 자료의 경우 수치 맵핑 방식과 더미(Dummy)기법으로 자료를 변환 할 수 있고,
순서에 의미가 있는 순서형 자료의 경우 수치 맵핑 방식을 사용한다.
명목형 자료
수치 맵핑
일반적으로는 범주를 0,1로 맵핑 한다

(-1,1),(0,100)등 다양한 방법으로 할 수 있지만, 모델에 따라 성능이 달라질 수 있다.
맵핑 해야할 범주가 3개이상인 경우, 수치의 간격을 같게 하여 맵핑한다.
코드
DataFrame.replace({A:B, C:D,...})
를 사용하여 A를 B로 C를 D로 변환 할 수 있다.
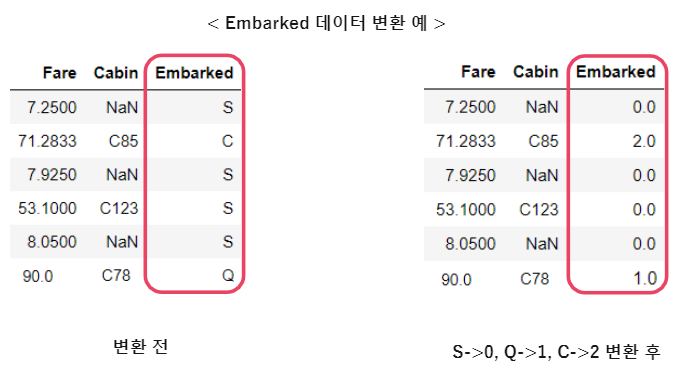
titanic = titanic.replace({'male':0,'female':1})
로 male을 0으로 female을 1로 변환 할 수 있다.
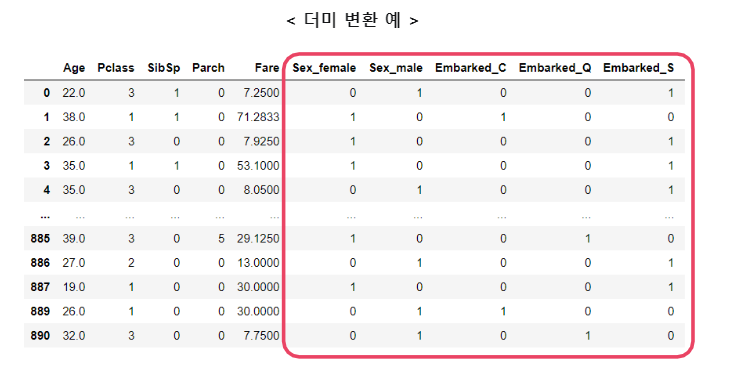
더미(Dummy) 기법
각 범주를 0 또는 1로 표현 할 수 있도록 더미 변수들을 만들어 범주형 변수들을 연속형 변수처럼 만들어 주는 방법이다.
코드
pd.get_dummies(DataFrame[[칼럼명]])
을 사용하여 data frame의 칼럼의 범주형 변수들을 연속형으로 변경 할 수 있다.
dummies = pd.get_dummies(titanic[['Embarked']])
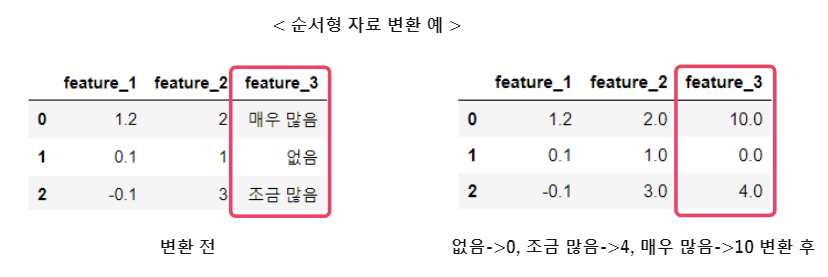
순서형 자료
수치 맵핑
동일하게 수치로 변환하지만, 수치 간 간격은 조절 할 수 있고, 이 크기 차이가 머신러닝 결과에 영향을 끼칠 수 있다.