[Paper Review] (2020, WSDM) RecVAE: a New Variational Autoencoder for Top-N Recommendations with Implicit Feedback
작성자: 이호진
논문: https://arxiv.org/pdf/1912.11160.pdf
Introduction
최근 Collaborative Filtering에서 autoencoder 기반 DNN들. ex (Mult-VAE)은 Top N 개 추천에서 좋은 성능을 보이고 있다.RECVAE는 Mult-VAE에서 발전된 모델이다.
MF는 CF기반 추천의 industry standard 하지만 문제점이 존재
-
파라미터 수가 매우 크다. 유저/아이템의 수에 선형적으로 의존 => 학습시간이 느려지고, 과적합 되기 쉽다.
-
새로운 유저/아이템에 대하여 예측하기 위해서는 다시 학습을 시켜야 한다.
-
작은 수의 유저/아이템 rating은 과적합 되기 쉽다.
Collaborative Denoising Autoencoder(CDAE)는 paramterized function 으로 유저 피드백을 유저 임베딩으로 맵핑하여부분적으로 이문제들을 해결했다.
CDAE는 문제 단순화를 위해 User-item interaction 정보를 binary정보로 바꿔서 학습데이터로 사용한다.
Mult-VAE는 CDAE에서 발전하여 multinomial likelihood를 사용
RecVAE는 implicit feedback을 기반으로 한 VAE, Mult VAE방식에서 발전.
-
새로운 Encoder architecture
-
새로운 composite prior distribution
- 정규분포와 이전 모델에서의 latent code distribution을 사용.
-
Kyllbback leibler term의 weight 베타를 설정하는 새로운 방법. user specific 한 베타를 사용
-
학습을 하는 새로운 방법.
- encoder의 업데이트와 decoder의 업데이트를 번갈아 가면서.
BACKGROUND AND RELATED WORK
Variational autoencoders and their extensions
VAE: deep latent variable model able to learn complex distributions
basic assumptions behind VAE
- dataset belongs to a low dimensional minfold embeded in a high-dimensional space=> marginal likelihood function can be expressed via
usually approximated with evidence lower bound(ELBO)
은 Kullback- Leibler divergence 두가지 확률 분포 함수가 있을때 얘네가 얼마나 비슷하냐를 뜻함 값이 높으면 다르고, 값이 낮으면 비슷하다는 의미 항상 양수
는 prior distribution
는 variational approximation of the posterior distribution parameterized function with ϕ,
are the parameters of
amortized/variational inference로 variational parameters with a closed form function을 얻을 수 있게 한다.
β-VAE
regularization coefficient를 kullbeack leibler term에 추가하여 disentangled representation을 학습한다.
DVAE (Denosing Variational Autoencoder)
denoising auto encoder 처럼 비슷하게 corrupted input부터 학습
는 nosie distribution 보통 Gaussian 또는 Bernoulli
CVAE (Conditional Variational Autoencoder)
복잡한 Conditional distribution을 학습
label 정보 y를 추가해서 사용! 입력과 label을 concat 해서 넣어주기만하면 된다.
VAEAC (VAE with Arbitrary Conditioning)
는 vector of unobserved feature
는 vector of observed feature
여기서 feature는 vector x의 component를 말함.
ex 이미지에서는 픽셀 같은걸 말함
implicit feedback에 바로 적용은 불가능.
Autoencoders and Regularization for Collaborative Filtering
U와I를 각각 User와 Item의 set 이라고 할때,
implicit feedback matrix는 으로 표현 할 수 있고, 은 u번째 유저와 i번째 아이템의 positive interaction(구매, 좋아요 등) 그렇지 않은 경우로 표현 가능하다. 유저 u 의 feedback vector는 로 표현한다.
CDAE Collaborative Denoising Autoencoder의 경우
corrupted vesrsion 에서 를 재구성한다. 는 에서 값을 무작위로 삭제하는 방식으로 만들어진다. 모델의 encoder 부분이 를 hidden state로 mapping 한다.
CDAE에서는 encoder decoder부분이 모두 single neural layer로 구성 되어있다.(1개의 hidden layer로 구성)
user input node로 user specific weight를 주고, 나머지 weight들은 모든 유저에서 공유된다.

는 latent representation
는 reconstructed feedback
와 는 input-to-hidden, hidden-to-output weight
는 user specific weight as user embedding
MF기반 모델의 user/item embedding들은 대부분 dataset size가 커질수록 매우 큰 parameter를 가지고 있게 된다.
그러므로 전통적인 MF기반 CF모델은 heavy regularization이 필요하다. 보통은 L2,L1 regularizer를 embedding weights에 추가하여 해결한다고 하지만, 실제로는 다양한 prior 또한 사용되고, RecVAE와 가장 비슷하게 prior를 사용하는 모델은 Mult-VAE가 있다.
PROPOSED APPROACH
Mult-VAE
Mult-VAE는 likelihood function을 VAE에서 흔히 쓰이는 Gaussian 과 Bernoulli 분포가 아니라 Multinomial 분포를 사용했다.
generative model은 유저 u 의 k-dimensional latent representation,를 sampling 한다. 그후,
transforms it with a function parameterized by θ
k-dimension에서 I dimension으로 다시 transform 시켜준다.
일반적인 CF모델은 linear한 를 사용하지만, Mult-VAE는 parameter θ를 가지고 있는 neural network를 사용한다는 점에서 다르다.
Model Architecture
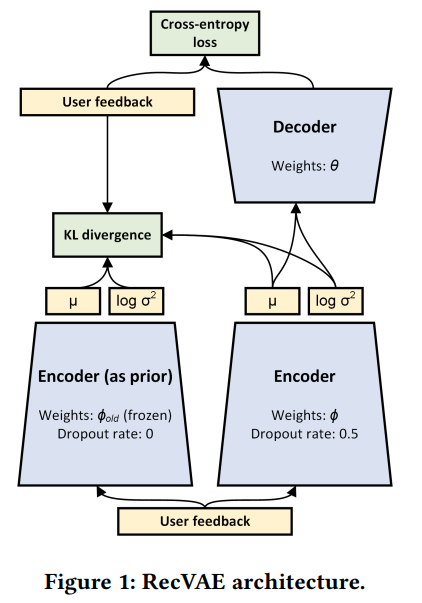
- moved denoising variational autoencoder
=>
=>
기존 Mult VAE논문에서 VAE 구조를 가지고 있지 않지만, Bernoulli based 인 DAE(Mult-DAE)를 같이 비교 했다고 하는데, 사실 Mult-VAE에서도 denoising을 사용한 것으로 보임으로 여기에서도 추가. (코드와, 저자의 실험을 통해 알 수 있었다고 한다, denosing을 사용했더니 논문과 같은 결과를 낼 수 있었고, denosing을 사용하지 않으면 아예 다른 값이 나왔다고 한다.)

#https://github.com/ilya-shenbin/RecVAE/blob/master/model.py
class Encoder(nn.Module):
def __init__(self, hidden_dim, latent_dim, input_dim, eps=1e-1):
super(Encoder, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.ln1 = nn.LayerNorm(hidden_dim, eps=eps)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.ln2 = nn.LayerNorm(hidden_dim, eps=eps)
self.fc3 = nn.Linear(hidden_dim, hidden_dim)
self.ln3 = nn.LayerNorm(hidden_dim, eps=eps)
self.fc4 = nn.Linear(hidden_dim, hidden_dim)
self.ln4 = nn.LayerNorm(hidden_dim, eps=eps)
self.fc5 = nn.Linear(hidden_dim, hidden_dim)
self.ln5 = nn.LayerNorm(hidden_dim, eps=eps)
self.fc_mu = nn.Linear(hidden_dim, latent_dim)
self.fc_logvar = nn.Linear(hidden_dim, latent_dim)
def forward(self, x, dropout_rate):
norm = x.pow(2).sum(dim=-1).sqrt()
x = x / norm[:, None]
x = F.dropout(x, p=dropout_rate, training=self.training)
h1 = self.ln1(swish(self.fc1(x)))
h2 = self.ln2(swish(self.fc2(h1) + h1))
h3 = self.ln3(swish(self.fc3(h2) + h1 + h2))
h4 = self.ln4(swish(self.fc4(h3) + h1 + h2 + h3))
h5 = self.ln5(swish(self.fc5(h4) + h1 + h2 + h3 + h4))
return self.fc_mu(h5), self.fc_logvar(h5)class VAE(nn.Module):
def __init__(self, hidden_dim, latent_dim, input_dim):
super(VAE, self).__init__()
self.encoder = Encoder(hidden_dim, latent_dim, input_dim)
self.prior = CompositePrior(hidden_dim, latent_dim, input_dim)
self.decoder = nn.Linear(latent_dim, input_dim)
def reparameterize(self, mu, logvar):
if self.training:
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
else:
return mu
def forward(self, user_ratings, beta=None, gamma=1, dropout_rate=0.5, calculate_loss=True):
mu, logvar = self.encoder(user_ratings, dropout_rate=dropout_rate)
z = self.reparameterize(mu, logvar)
x_pred = self.decoder(z)
if calculate_loss:
if gamma:
norm = user_ratings.sum(dim=-1)
kl_weight = gamma * norm
elif beta:
kl_weight = beta
mll = (F.log_softmax(x_pred, dim=-1) * user_ratings).sum(dim=-1).mean()
kld = (log_norm_pdf(z, mu, logvar) - self.prior(user_ratings, z)).sum(dim=-1).mul(kl_weight).mean()
negative_elbo = -(mll - kld)
return (mll, kld), negative_elbo
else:
return x_pred
Composite Prior
Mult VAE의 input 과 output은 high dimensional sparse vector이다.
amortized approximate posterior (위의 L)는 학습을 regularize 하지만, variational parameter를 손상하여 학습중 instability를 야기할 수 있다.(강화학습의 forgetting과 유사한 효과)
이전의 policy based reinforcement learning 은
모델의 parameter를 이전 epoch의 모델 parameter를 가깝게 하는 것이 final score를 좀더 smooth하게 증가하고, 모델이 good behaviour를 잊어버리는 것을 방지 할 수 있다는 것을 보여 주었다.
하지만 latent code z 에 standard Gaussian prior를 사용하고 다른 regularization 텀을 새로운 parameter 분포와 이전 epoch의 parameter 분포의 KL divergence같은 형식으로 추가하면 위의 아이디어와는 상반 된다고 볼 수 있다.
하지만 저자의 실험에서는 두 아이디어(prior and additional regularizer)를 포함 한 것이 더 좋았다고 한다.
뒤의 term은 variational parameter optimization 중 large step을 규제한다.
앞의 term은 overfitting을 방지한다.
Rescaling KL divergence
β를 어떻게 선택해야할까?는 아직도 완벽하게 해결 되진 않았다. 학습중 0에서1로 증가시키는 방법등이 제시되기도하고 Mult VAE의 학습에서는 0에서 어떤 상수 값까지 증가시킨다고 한다.
저자의 실험에서는 β를 점차적으로 늘린다고 성능이 좋아지진 않았다고 한다. 따라서 값을 고정하기로 하였다고 한다.
hyperparameter shared across all users
현재 유저가 가지고 있는 피드백에 비례한다. 높은 성능 향상을 보였다.
Alteranating Training and Regularization by Denoising

encoder 의 parameter 와 item matrix and bias vector의 parameter (decoder)를 번갈아가면서 학습
encoder가 더 복잡하기 때문에, 를 여러번 업데이트 하고 를 한번 업데이트 한다.
실험에서 를 학습할때 input을 corrupt 하지 않고, denosing을 를 학습할때만 했더니, 성능이 향상 되었다.
L2나 Bayesian decoder 같은 regularization또한 성능을 저하시키는 것으로 보아 decoder 의 parameter가 overregularize 된 것 같아, decoder부분은 vanila VAE 처럼 denoising 없이 사용하고, encoder는 denoising variational autoencoder의 구조를 사용했다.
Summary
decoder를 학습할때 input이 corrupted 되지 않게, 를 업데이트 할때 objective function은 따로 정의
KL term 은 에 대한 식이 아님으로 무시
Multinomial likelihood를 사용했기 때문에 Loss의 main component는 cross-entropy이다.
EXPERIMENTAL EVALUATION
Metrics
Recall@k
NDCG@k
top-k predictions of a model
Datasets
MovieLens-20M
Netflix Prize Dataset
Million Songs Dataset
Baseline
-
Linear models from classical cf
- Weighted Matrix Factorization(WMF)
- Sparse Linear Method(SLIM)
- EASE
-
Learning to rank methods
- WARP
- LambdaNet
-
Autoencoder based
- CDAE
- Mult-DAE
- Mult-VAE
- RaCT


Negative results
- 주어진 아이템에 대하여 top users를 예측하는 symmetric autoencoder 형태로 학습을 시도
- 학습이 더 느리고, 더 많은 메모리를 사용하고, 성능도 RecVAE보다 나빴다
- 더 복잡한 prior distribution을 사용하려고 시도
- standard Gaussian 보다 성능이 좋았던 것들이 있지만 제시된 composite prior에 같이 적용할 수는 없었고, composite prior with Gaussian term이 가장 좋았다
- B-VAE 처럼 KL의 weight 를 주지 않고, 각 term을 풀어서 따로 weight를 주려고 시도
- 성능이 더 좋아지진 않음
Conclusion
-
new encoder architecture
-
new composite prior distribution for the latent codes
-
new approach to setting the hyperparameter β
-
new approach to training RecVAE with alternating updates of the encoder and decoder
-
EASE와 맞먹고 다른 모델들 보다 뛰어나다!
