
1. Multiplexing/Demultiplexing 란?
TCP든, UDP든, 트랜스포트 레이어라면 기본적으로 제공하는 기능이 multiplexing, demultiplexing 입니다.
Demultiplexing at rcv_host: delivering received segments to correct socket
Multiplexing at send host: gathering data from multiple sockets, enveloping data with header (later used for demultiplexing)

컴퓨터 내부에는 많은 프로세스들이 있습니다. 이런 상황에서 이 프로세스들이 네트워크 프로세스면 각각의 소켓이 있을 것 이고, 이 소켓을 통해서 트랜스포트 레이어로 메시지가 내려오게 됩니다.
그럼 트랜스포트 레이어는 여러 소켓에서 내려오는 메시지를 받아서 하나의 세그먼트로 만들고 그걸 다시 내려줘야 합니다. 여러 소켓에서 내려 오는 것을 그때마다 세그먼트를 만들어서 네트워크 레이어로 내려보내준다는 의미에서 Multiplexing 입니다. 즉, 멀티로 들어오는 것을 하나로 만들어주는 거라고 볼 수 있습니다.
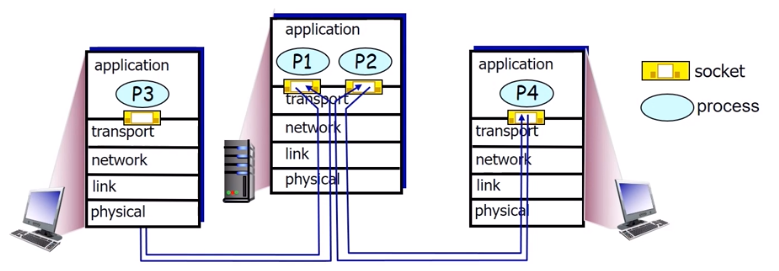
Demultiplexing은 세그먼트 형태로 내려와서 반대쪽 리시버에 도착을 해서 올라가면 여기 반대쪽 세그먼트가 받게 됩니다. 그러면 세그먼트를 받아서, 세그먼트의 데이터 부분 메시지를 꺼내서 그 메시지를 받아야 되는 프로세스에게 정확히 올려줘야 합니다.
즉, 예를 들면 프로세스들이 많이 있고, 프로세스들이 소켓을 열고 기다리고 있습니다. 자신의 메시지를 기다리고 있는상황에서, 알맞은 프로세스에게 올려줘야 되는 겁니다. 이것이 바로 Demultiplexing 입니다.
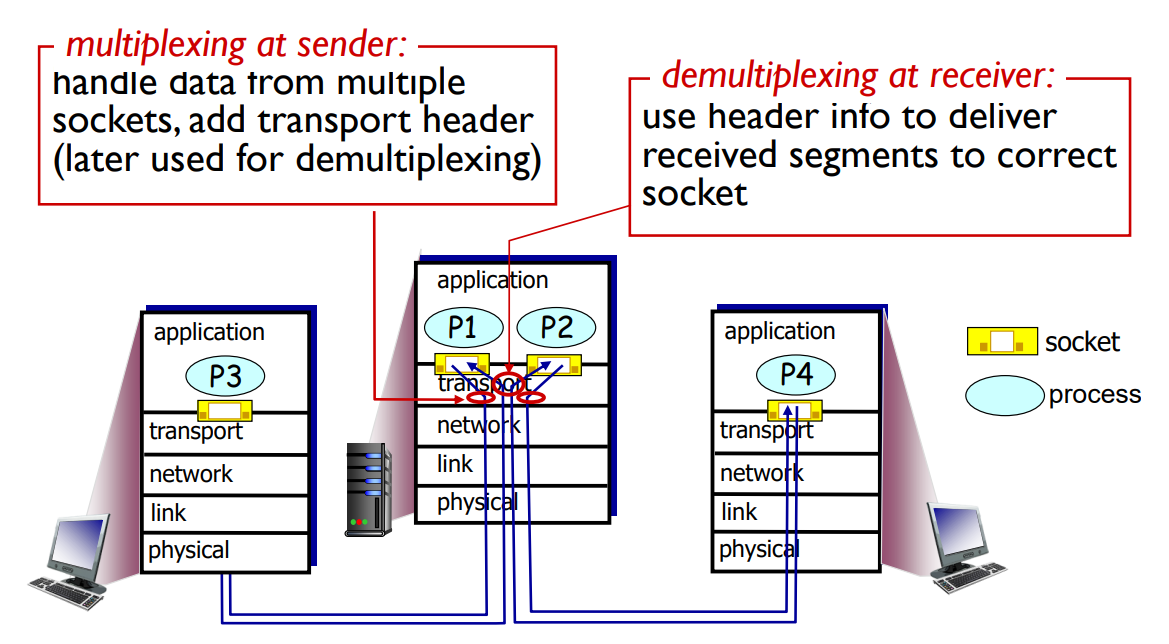
그래서 Multiplexing은 sender 측에서, sender 트랜스포트 측에서 하는 거고 Demultiplexing은 receiver 측에서 되는겁니다. 결국에는 어떤 소켓으로 올바르게 보내는가 입니다. 이 올바르게 보내는 것을 세그먼트에서 데이터 부분인 애플리케이션 메시지를 꺼내서 알맞은 목적지에 해당하는 프로세스로 올려줘야 합니다. 그것을 세그먼트의 헤더에 적힌 정보를 가지고 어떤 소켓으로 올려줘야 될지를 판단하게 됩니다.
2. How Demultiplexing works
1. Host receives IP datagrams
Each datagram has source IP address, destination IP address
Each datagram carries 1 transport layer segment
Each segment has source, destination port number
2. Host uses IP addresses & port numbers to direct segment to appropriate socket

세그먼트는 헤더와 데이터로 이루어 집니다. 정보를 적는 헤더 내에 필드들이 있습니다. 그 중에 중요한 필드가 위 그림의 source port랑 destination port 입니다. 위 필드의 크기는 16비트가 됩니다.
헤더는 부가적인 정보를 적은 공간이기 때문에 필드들이 여러 개 있습니다. source port와 destination port라는 필드가 있어서 그 필드를 가지고 Demultiplexing을 하게 됩니다. 데이터 부분은 헤더에 비해서 훨씬 큽니다. 예를 들어, 편지 봉투의 내용과, 편지 봉투 안의 편지지의 내용에 적힌 것이라고 개념적이해 하면 될 것 같습니다.
3. Connectionless Demultiplexing : Example
UDP의 경우 connectionless 합니다. 어떤 식으로 connectionless하게 Demultiplexing하는지 알아보겠습니다.
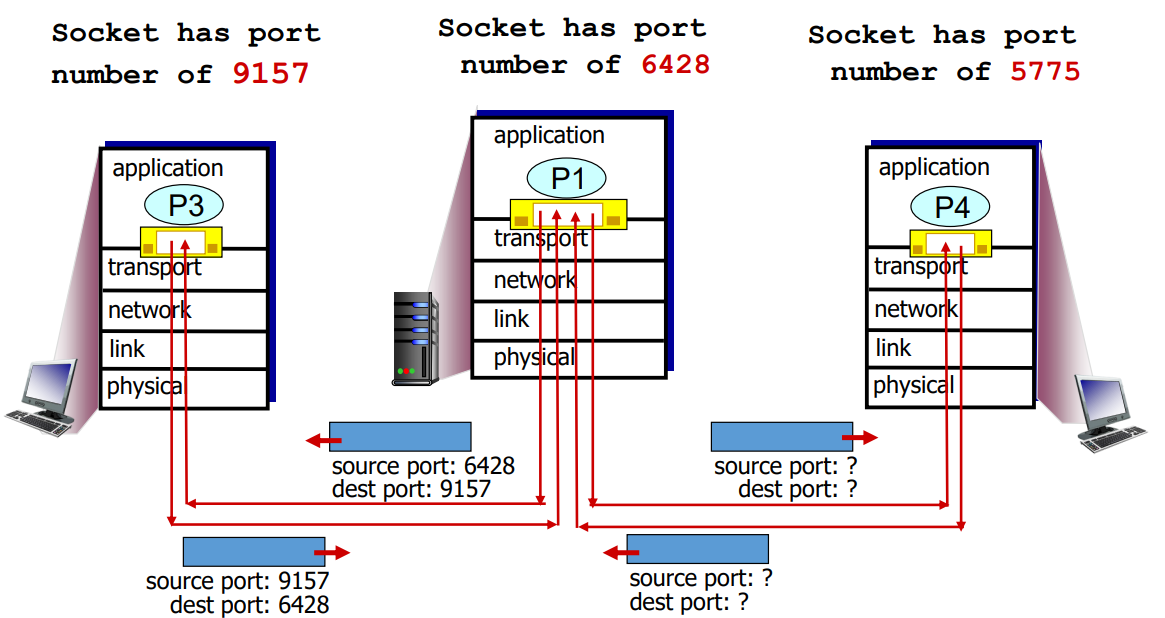
예를 들어 컴퓨터에 존재하는 p3과 서버에 존재하는 p1이 의사소통을 하고 싶어 하고, p4 또한 p1과 의사소통을 하고 싶어 합니다. (p = 프로세스) p3이 메시지를 만들어서 p1 프로세스가 받게 하기 위해서, 메시지가 소켓을 통해서 내려와서 세그먼트 안에 담겨갑니다. 그리고 이 세그먼트에 적힌 헤더에는 소스와 데스티네이션 포트 정보가 적히게 됩니다. 포트 정보로는 소스는 자기 자신의 포트 넘버, 데스티네이션 포트는 p1의 포트 넘버가 담기게 됩니다.
그리고 서버 컴퓨터에 도달하기 위해서는 서버의 IP 정보가 어딘가에 적혀야 됩니다. 이 IP 정보는 세그먼트에 안 적히고 패킷, 네트워크 레이어 전송 단위의 패킷의 헤더에 IP Address라는 필드가 있어서 그곳에 적히게 됩니다.
p4에서 p1로 가는 소스 포트는 소스 포트 필드에 적히는 거는 5775 데스티네이션 포트는 6428. 지금 세그먼트가 어디서 왔든 다 같은 소켓으로 갑니다. 같은 소켓으로 간다는 것은 동일한 프로세스로 간다는 것 입니다. UDP를 사용할 경우에는 Demultiplexing은 데스티네이션 IP와 데스티네이션 포트 넘버만을 사용해서 어떤 소켓으로 올릴지 Demultiplexing을 하게됩니다.
그래서 p3에서 전송해서 p1로 들어오는 세그먼트랑, p4에서 전송한 세그먼트는 데스티네이션 포트랑 데스티네이션 IP가 동일하게 됩니다. (p3과 p4의 데스티네이션 포트, ip 는 동일합니다.)
4. Connection-oriented Demux : Example

TCP를 사용할 경우의 Demultiplexing은 데스티네이션 IP와 데스티네이션 포트 넘버 두 개만 가지고 판단하는 게 아니라 소스 IP 그리고 소스 포트 그리고 데스티네이션 IP 그리고 데스티네이션 포트 이 4개의 튜플을 가지고 어떤 소켓으로 올릴지 판단을 하게 됩니다. 그러니까 즉 이 4개 중에 하나라도 다르면, 다른 소켓으로 올라가게 됩니다.
이 P3에서 나가는 세그먼트 헤더에 적힌 정보들을 보면 소스 IP는 A고, 소스 포트는 9157, 데스티네이션 IP는 B고 데스티네이션 포트는 80입니다. 이거 데스티네이션 포트 80이라는 것은 웹 서버가 있다는 것 입니다.
서버로 들어가는 세그먼트 세 개의 공통점은 데스티네이션 IP랑 데스티네이션 포트가 동일하다는 것 입니다. 다 이 서버의 80번 포트로 향하는 것 입니다. 그런데, Demultiplexing 해보면 다른 소켓, 다른 프로세스 올라갑니다. 그 이유는 TCP는 소스 IP가 틀리거나 소스 IP가 같더라도, 소스 포트만 틀려도, 이 넷 중에 하나라도 틀리면 다른 곳 다른 소켓으로 Demultiplexing 되기 때문입니다. 그러니까 이것이 TCP의 connection-oriented가 됩니다.
반대로 UDP는 지금 서버의 소켓을 통해서 받는 메시지는 아무나에게서 옵니다. 이 소켓은 어느 누구와도 연결이 되는 게 아닙니다. 아무나 막 받을 수 있습니다. 데스티네이션 포트만 맞으면 다 오기 때문에 Connectionless 개념이 됩니다.
즉, 결론을 내면 UDP 경우에는 데스티네이션 IP와 데스티네이션 포트 넘버만 가지고 어디로 올려보낼지에 대한 Demultiplexing을 하게 되고, TCP 같은 경우에는 소스 IP 그리고 소스 포트 그리고 데스티네이션 IP 그리고 데스티네이션 포트 4개 튜플을 가지고 Demultiplexing을 하게 돼 있습니다.
위의 경우는 웹서버가 하나의 예가 될 수 있습니다. 실제 구현은, 웹 서버 프로세스가 하나 있고 각 사용자별로 각 사용자별로 스레드가 있어가지고 그 스레드가 각각 이 소켓을 담당하게 됩니다. 그러니까 실제로 네이버에 접속을 하면, TCP connection을 만들고 이렇게 한다는 얘기는 네이버 서버는 여러분들 각각을 위한 여러분들 고유의 소켓을 생성해놓는다는 것 입니다.
그러니까 네이버 서버 프로세스가 있으면, 이게 사용자들 한 명씩 접속할 때마다 그 사용자만을 위한 소켓이 있는 겁니다. 그래서 이 소켓을 통해서 받는 건 무조건 특정 유저가 됩니다. 그래서 TCP가 각각 클라이언트를 위해서 소켓을 생성하고 관리해서 자원을 많이 소모합니다.
5. UDP: User Datagram Protocol [RFC 7681]
UDP가 제공해 주는 것은 바로 unreliable delivery, unordered delivery. 아무것도 제공해 주지 않는 것 같지만 이것이 트랜스포트 레이어가 제공해 주는 아주 기본적인 서비스는 제공하는 것 입니다. 이게 뭔지 살펴보기 전에 우선 UDP에 세그먼트를 보겠습니다.
-
"No frills," "bare bones" Internet transport protocol
-
"Best effort" service, UDP segments may be:
- Lost
- Delivered out of order to app
-
Connectionless:
- No handshaking between UDP sender, receiver
- Each UDP segment handled independently of others
-
UDP usage:
- Streaming multimedia apps(loss tolerant, rate senstive)
- DNS
- SNMP
-
Reliable transfer over UDP:
- Add reliability at application layer
- Application-specific error recovery!
6. UDP: Segment Header
UDP, TCP, IP라는 아주 중요한 프로토콜들을 우리가 계속 얘기를 할 텐데 상위 레이어에서 얘기하는 것들의 헤더 정보는 우리가 그렇게 유심히 생각하지 않아도 됩니다.
그러나 UDP TCP, IP 이 세 개의 프로토콜의 헤더 정보는 우리가 잘 알고 있어야 합니다. 여기에 어떤 필드들이 있고 각각은 어떤 의미를 가지는지를 잘 이해하고 있어야 합니다. 이 프로토콜이 중요하고 어떤 특정 프로토콜의 동작을 이해하기 위해서는 결국 이 필드들에 어떤 정보가 적혀 있는지 우리가 알아야 합니다. 이 필드들에 적힌 정보가 바로 그 프로토콜이 어떻게 동작하는지를 나타내기 때문입니다.
예를 들면 우편 배달부가 어떤 동작을 하는데 그 동작은 편지 내용에 근거하지 않습니다. 편지 봉투에 적힌 정보에 근거해서 동작을 하는 것 입니다. 그렇기 때문에 결국 편지 봉투에 어떤 정보가 적히는지를 알아야지 우편 배달부의 행동으로 우리가 알 수 있는 것 입니다. 그래서 헤더가 중요합니다. 즉, 프로토콜을 이해하는 건 결국에는 그 프로토콜의 헤더를 이해하는 게 전부입니다.
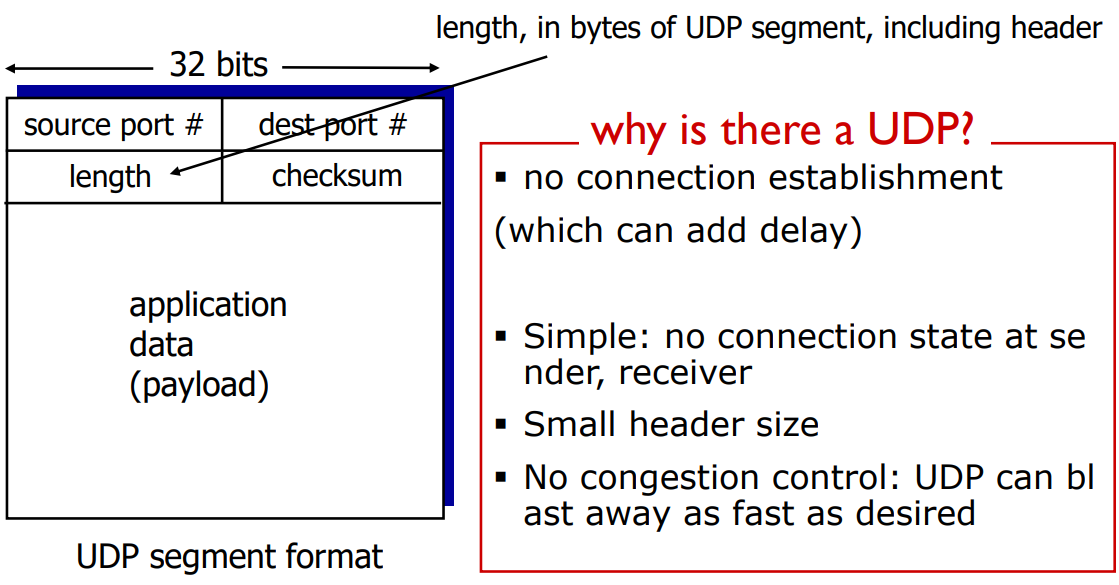
그럼 UDP 세그먼트에 헤더를 알아보겠습니다. 필드가 4개밖에 안 됩니다. UDP의 필드가 4개밖에 안 되니까 그만큼 뭔가 동작이 단순하다는 걸 알 수 있습니다.
각각이 어떤 의미인지 알아야지 UDP 동작을 알 수 있습니다. 4개 있는데 소스 포트, 데스티네이션 포트, 그 다음에 데이터 길이, checksum이라는 게 있습니다. 소스 포트 데스티네이션 포트 각각 한 필드가 16비트 입니다. 16 비트이기 때문에 포트 넘버는 0번부터 2^16-1번까지 있습니다.
그러면 UDP는 이 포트 넘버로 multiplexing, demultiplexing을 합니다. 이 세그먼트를 받아서 알맞은 대로 올려주려면 포트 넘버를 봐야합니다. 포트 넘버를 보고 demultiplexing 하게 됩니다.
그리고 length야 길이라고 치고, 이 checksum은 여기에 담긴 데이터가 전송 도중에 에러가 있었는지 없었는지 판단해 주는 필드입니다.
그래서 받았을 때 checksum 필드를 가지고 에러를 판단해서, 만약에 여기 데이터에 에러가 생겼다 그러면 어떻게 올리지 않고 바로 그냥 드랍시키게 됩니다.
기본적으로 UDP가 아무것도 안 해주는 것 같지만, 최소한의 일은 합니다. Multiplexing, demultiplexing 하나 해 주고, 그 다음에 두 번째 에러 체크해줍니다.
그래서 UDP를 통해서 뭔가 메시지를 받았다. 그럼 최소한 그 메시지에는 에러가 없게 됩니다. 기억해 둬요. UDP가 아무것도 안 하는 것 같지만 트랜스포트가 해줘야 될 기본적인 일 두 가지 일을 합니다. Multiplexing/demultiplexing 그리고 에러 체크.
7. UDP: more
Often used for streaming multimedia apps
- loss tolerant (손실 관대)
- rate sensitive (속도에 민감)
Other UDP uses
- DNS
- SNMP
Reliable transfer over UDP: add reliability at application layer (안정적인 전송 ?)
- application-specific error recovery!
