ItemReader
Chunk Tasklet은
- ItemReader를 통해 데이터 읽기
- ItemProcessor를 통해 서비스 로직 진행
- ItemWriter를 통해 일괄처리
의 로직으로 진행된다. 이 중 Reader에 대해서 학습해보자.
CursorItemReader
CursorItemReader는 Streaming으로 데이터를 처리한다. 쉽게 생각하면 Db와 어플리케이션 사이에 통로를 하나 연결하고 하나씩 가져온다고 생각하면 된다.
실습을 위해 query 실행
create table pay (
id bigint not null auto_increment,
amount bigint,
tx_name varchar(255),
tx_date_time datetime,
primary key (id)
) engine = InnoDB;
insert into pay (amount, tx_name, tx_date_time) VALUES (1000, 'trade1', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (2000, 'trade2', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (3000, 'trade3', '2018-09-10 00:00:00');
insert into pay (amount, tx_name, tx_date_time) VALUES (4000, 'trade4', '2018-09-10 00:00:00');db에 데이터를 우선 등록해준다.
Pay 생성
@ToString
@Getter
@Setter
@NoArgsConstructor
public class Pay {
private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss");
private Long id;
private Long amount;
private String txName;
private LocalDateTime txDateTime;
public Pay(Long amount, String txName, String txDateTime) {
this.amount = amount;
this.txName = txName;
this.txDateTime = LocalDateTime.parse(txDateTime, FORMATTER);
}
public Pay(Long id, Long amount, String txName, String txDateTime) {
this.id = id;
this.amount = amount;
this.txName = txName;
this.txDateTime = LocalDateTime.parse(txDateTime, FORMATTER);
}
}pay를 db에서 객체로 가져오기 위해서 class 생성
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JdbcCursorItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private static final int chunkSize = 10;
@Bean
public Job jdbcCursorItemReaderJob(){
return jobBuilderFactory.get("jdbcCursorItemReaderJob") //jdbcCursorItemReaderJob 이름으로 job 생성
.start(jdbcCursorItemReaderStep()) //step 실행
.build();
}
@Bean
public Step jdbcCursorItemReaderStep() {
return stepBuilderFactory.get("jdbcCursorItemReaderStep") //jdbcCursorItemReaderStep 이름으로 step 생성
.<Pay, Pay>chunk(chunkSize) //chunk size 지정 (=transaction 범위)
.reader(jdbcCursorItemReader()) //reader 실행
.writer(jdbcCursorItemWriter()) //writer 실행
.build();
}
@Bean
public ItemReader<? extends Pay> jdbcCursorItemReader() { //itemReader 구현
return new JdbcCursorItemReaderBuilder<Pay>()
.fetchSize(chunkSize) //db에서 읽어오는 데이터 양
.dataSource(dataSource) //db 설정
.rowMapper(new BeanPropertyRowMapper<>(Pay.class)) //반환되는 데이터를 Pay 객체로 변환
.sql("select id, amount, tx_name, tx_date_time from pay")
.name("jdbcCursorItemReader")
.build();
}
private ItemWriter<? super Pay> jdbcCursorItemWriter() { //writer 구현
return list -> {
for(Pay pay : list){
log.info("Current Pay={}",pay);
}
};
}
}Step의 Reader와 Writer를 구현하여 직접 실행 결과를 확인해보자.
intellij server 실행시
--job.name=jdbcCursorItemReaderJob version=7다음과 같이 설정해준 값으로 보내면 된다.
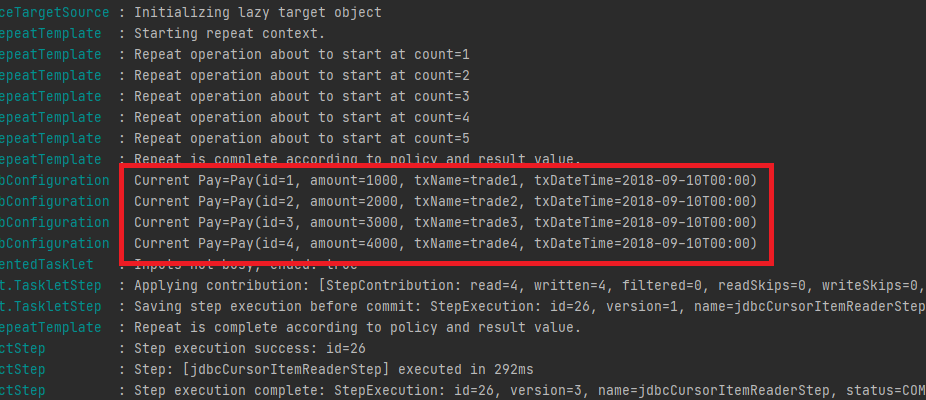
다음과 같이 결과를 확인할 수 있다.
process()는 꼭 구현하지 않아도 되는 부분이며 서비스 로직을 담당하는 부분이다.
PagingItemReader
@Slf4j
@RequiredArgsConstructor
@Configuration
public class JdbcPagingItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource; // DataSource DI
private static final int chunkSize = 10;
@Bean
public Job jdbcPagingItemReaderJob() throws Exception{
return jobBuilderFactory.get("jdbcPagingItemReaderJob") //jdbcPagingItemReaderJob 이름으로 Job 생성
.start(jdbcPagingItemReaderStep())
.build();
}
@Bean
public Step jdbcPagingItemReaderStep() throws Exception{
return stepBuilderFactory.get("jdbcPagingItemReaderStep") //jdbcPagingItemReaderStep 이름으로 Step 생성
.<Pay, Pay>chunk(chunkSize)
.reader(jdbcPagingItemReader())
.writer(jdbcPagingItemWriter())
.build();
}
@Bean
public ItemReader<Pay> jdbcPagingItemReader() throws Exception{
Map<String, Object> param = new HashMap<>(); //parameter 생성
param.put("amount", 2000);
return new JdbcPagingItemReaderBuilder<Pay>()
.pageSize(chunkSize)
.fetchSize(chunkSize)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Pay.class))
.queryProvider(createQueryProvider()) //각 DB에 정의된 provider를 사용해도 되지만 spring에서 적용 가능한 더 범용성 있는 코드 작성
.parameterValues(param) //parameter
.name("jdbcPagingItemReader")
.build();
}
private ItemWriter<Pay> jdbcPagingItemWriter() { //writer 실행
return list -> {
for(Pay pay : list){
log.info("Current Pay={}",pay);
}
};
}
@Bean
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource); //db에 맞는 pagingProvider 자동 선택
queryProvider.setSelectClause("id, amount, tx_name, tx_date_time"); //select 문
queryProvider.setFromClause("from pay"); //from 절
queryProvider.setWhereClause("where amount >= :amount"); //where 절
Map<String, Order> sortKey = new HashMap<>(1); //sort 정의
sortKey.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKey);
return queryProvider.getObject(); //결과값 반환
}
}PagingItemReader 주의 사항
! 정렬이 무조건 포함되어 있어야 함
