문제
5개의 정점을 가지는 방향 그래프의 모든 경로의 가지 수를 출력하는 프로그램을 작성하는 문제가 있다. 이때 입력되는 예시는
5 9
1 2
1 3
1 4
2 1
2 3
2 5
3 4
4 2
4 5
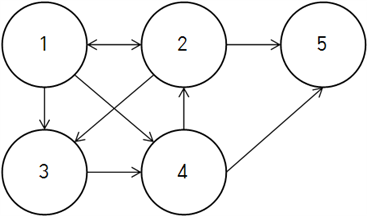
입력받은 값을 그래프로 표현하면 위 그림과 같다.
총 가지수는
1 2 3 4 5
1 2 5
1 3 4 2 5
1 3 4 5
1 4 2 5
1 4 5
총 6개가 존재한다. 이를 DFS 알고리즘을 사용하여 풀어내보자.
코드
public class AdjacencyMatrix {
static int n, m, answer = 0;
static int[][] graph;
static int[] ch;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
graph = new int[n+1][m+1];
ch = new int[n+1];
for(int i=0; i<m; i++){
int su1 = sc.nextInt();
int su2 = sc.nextInt();
graph[su1][su2] = 1;
}
ch[1] = 1;
dfs(1);
System.out.println(answer);
}
public static void dfs(int v){
if(v==n){
answer ++;
return ;
}
for(int i=1; i<=n; i++){
if(graph[v][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}
}
}설명
먼저 해답 코드는 위 코드와 같다. 이 코드를 하나씩 풀어가면서 이해해보도록 하자.
static int n, m, answer = 0;
static int[][] graph;
static int[] ch;우선 static 변수들을 선언하였고
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
graph = new int[n+1][m+1];
ch = new int[n+1];
for(int i=0; i<m; i++){
int su1 = sc.nextInt();
int su2 = sc.nextInt();
graph[su1][su2] = 1;
}main코드부터 따라가면 main에서 총 꼭지점의 갯수인 n의 값 5를 입력받고 각 꼭지점 사이의 이동 가능한 경로인 m의 값 9를 입력받는다. 그 후 m만큼 반복하여 총 이동 가능한 경로들을 입력 받는데. graph는 각 인덱스 값을 그대로 사용하기 위해 각 입력받은 n과 m보다 +1씩 더하여 2차원 배열을 생성하고 그 후 반복문에서 이동가능한 경로에 값을 1로 변경하여 체크해준다. (2차원 배열을 최초 생성하면 모두 0으로 초기화되는건 기본^^)
ch[1] = 1;
dfs(1);
System.out.println(answer);그 후 시작점이 1을 실행하기 위해 체크 배열인 ch[1] = 1을 실행하여 1은 실행됨을 선언하고 dfs(1)을 실행한다.
그럼 이제부터 dfs()의 내부 실행을 알아보자.
dfs의 코드는 생각보다 간단한데
public static void dfs(int v){
if(v==n){
answer ++;
return ;
}
for(int i=1; i<=n; i++){
if(graph[v][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}
}전체 코드는 위와 같으며 입력된 값 v가 n의 값인 5인 경우 최종 노드에 도착한 것이므로 answer을 증가시키고 반환한다. 그게 아니라면 입력된 값 v를 행으로 반복문 내부에서 행의 열의 값을 모두 검사한다. 이때 이미 한번 체크한 곳은 들리지 않을 것이기 때문에 체크 배열이 0인지도 검사하는게 필요하다.
for(int i=1; i<=n; i++){
if(graph[v][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}dfs에서 가장 중요한 부분인데 이 부분을 1을 입력받은 dfs(1)을 기준으로 한번 따라가보자.
입력 받은 값들을 기준으로 위 코드를 다시 작성하면
for(int i=1; i<=5; i++){
if(graph[1][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}과 같아지며 i는 인덱스 값을 0을 쓰지 않기 위해 +1하여 만들었기 때문에 1부터 시작한다. 그럼 지금 graph 배열의 상황을 그림으로 확인해보자.
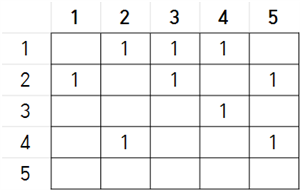
체크 배열 ch의 내부도 확인하면

임을 생각하며 for문을 차례대로 확인해보자
dfs(1)
i = 1일때
graph[1][1] = 0 이므로 조건 x
i = 2일때
graph[1][2] = 1 이므로 조건 통과
ch[2] = 0 이므로 조건 통과
i=2일때 조건을 모두 만족시켰다. 그럼 이제 조건문의 내부에서 실행되는 결과를 살펴보자.
먼저 ch[2] = 1;을 실행시켰으므로

체크 배열을 확인하고 그 다음 다시 dfs(2)을 실행시킨다. 우리가 지금까지 계속 언급하고 있는 jvm의 구조와 stack frame으로 인해 dfs(1)은 여기서 멈추고 dfs(2)의 값이 반환될 때까지 대기한다.

다음 그림과 같이 stack frame이 쌓여있으며 dfs(2)의 실행 동작도 살펴보자.
dfs(2)의 입력 값인 2는 5가 아니므로 다시 반복문이 실행된다. 반복문 내부의 조건문을 다시 현재 값에 맞게 재구성하면
for(int i=1; i<=5; i++){
if(graph[2][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}다음과 같으며 반복문 실행을 다시 1부터 살펴보자.
dfs(2)
i = 1 일때
graph[2][1] = 1 이므로 통과
ch[2] = 1 이므로 조건 x
i = 2 일때
graph[2][2] = 0 이므로 조건 x
i = 3 일때
graph[2][3] = 1 이므로 통과
ch[3] = 0 이므로 통과
ch[3] = 1을 실행
dfs(3) 실행
이제부터는 설명보다는 간단한 글과 그림으로만 진행하겠다.

dfs(3)
i = 1 일때
graph[3][1] = 0 조건 x
i = 2 일때
graph[3][2] = 0 조건 x
i = 3 일때
graph[3][3] = 0 조건 x
i = 4 일때
graph[3][4] = 1 조건 o
ch[4] = 0 조건 o
ch[4] = 1 실행
dfs(4) 실행

dfs(4)
i = 1 일때
graph[4][1] = 0 조건 x
i = 2 일때
graph[4][2] = 1 조건 o
ch[2] = 1 조건 x
i = 3 일때
graph[4][3] = 0 조건 x
i = 4 일때
graph[4][4] = 0 조건 x
i = 5 일때
graph[4][5] = 1 조건 o
ch[5] = 0 조건 o
cf[5] = 1 실행
dfs(5) 실행

dfs(5)
if(v==n){
answer++;
return ;
}조건에 걸려서 answer값을 1 증가시키고 반환된다. 이때 우리가 값을 구하기 위해 사용된 루트는
1 2 3 4 5 이다.
또한 지금까지 쌓여있는 stack frame을 확인하면

그림과 같으며 dfs(5)가 반환되며 dfs(4)가 마저 실행되어져야한다. 그럼 다시 실행되는 동작을 계속 살펴보자
dfs(5)를 반환받은 dfs(4)
for(int i=1; i<=5; i++){
if(graph[1][i] == 1 && ch[i] == 0){
ch[i] = 1;
dfs(i);
ch[i] = 0;
}
}우리가 실행한 코드는 dfs(i); 까지가 실행되었으니 나머지 ch[i]=0;을 실행시켜주고 해당 메서드도 반환을 하면된다.

i = 5일때 dfs(5)가 실행되었다가 반환 받은 것이므로 i는 5다. 그래서 체크 배열의 5를 0으로 다시 바꾸고 i의 값이 n까지 반복되었으므로 dfs(4)가 종료된다. dfs(4)가 종료되었으니 dfs(3)을 마저 종료시키면
dfs(4)를 반환받은 dfs(3)
dfs(3)은 i의 값이 4일때 종료되었다. 그래서 ch[4] = 0을 실행하고

나머지 i의 반복인 5를 실행한다.
graph[3][5] = 0 조건 x
이므로 dfs(3)도 종료된다.
dfs(3)를 반환받은 dfs(2)
dfs(2)는 i의 값이 3일때 종료되었다. 그래서 ch[3] = 0을 실행하고

다시 i의 나머지 반복인 4부터 반복을 실행한다.
i = 4 일때
graph[2][4] = 0 조건 x
i = 5 일때
graph[2][5] = 1 조건 o
ch[5] = 0 조건 o
ch[5] = 1 실행
dfs(5) 실행

dfs(5)가 실행되어 answer++가 되어지고 이때 사용된 루트는
1 2 5 이다.
그리고 dfs(5)는 dfs(2)에게 반환되어진다.
dfs(5)를 반환받은 dfs(2)
ch[5]=0 실행

i는 5까지 실행되었으므로 해당 메서드도 반환되어진다.
dfs(2)를 반환받은 dfs(1)
dfs(1)은 dfs(2)를 반환받았으므로 i를 3부터 반복하면 된다. 이제부터는 dfs()는 2를 사용하지 않고 1-3번으로 가는 루트를 모두 탐색하고 이후에는 1-4번 루트, 1-5번 루트를 순서대로 모두 탐색한 후 종료되어진다. 설명은 여기까지만 해도 이해에 도움이 될것이라 생각하고 이해가 되지 않는다면 글로만 읽지말고 실제로 그림을 그려가며 이해해보기를 추천한다.
그림으로 이해하기 위해서는
1. 체크 배열인 ch
2. 노드의 이동경로 2차원 배열
3. stack frame
을 직접 그려가며 이해해보고 실제 메서드들의 실행 결과를 눈으로 확인해보면 더 좋을거 같다!
