설명
DFS를 사용하여 입력 받은 n 값에 대한 부분 집합을 출력하는 알고리즘 작성
코드
public class SubSet {
static int n;
static int[] ch;
public static void main(String[] args) {
SubSet ss = new SubSet();
n = 3;
ch=new int[n+1];
ss.DFS(1);
}
public void DFS(int l){
if(l==n+1) {
for(int i=1; i<=n; i++){
if(ch[i] == 1) System.out.print(i+" ");
}
System.out.println();
}
else{
ch[l]=1; //1은 사용
DFS(l+1); //트리 왼쪽
ch[l]=0; //0은 사용하지 않는다.
DFS(l+1); //트리 오른쪽
}
}
}DFS를 사용한 트리 구조를 이해하기 위한 문제이다. 위의 코드의 예제를 통해 코드 실행의 구조를 하나씩 이해해보자! 무조건 이해해야한다 ㅜㅜ 어려우면 또 풀어보고 또 풀어보자!
- ss.DFS(1)의 실행
ss.DFS(1)이 실행되면 DFS에 입렵되는 값이 1로 시작된다. if에 의해 l==n+3(=4)가 아니므로 else의 DFS(l+1)을 실행하기 시작한다. 우선 else의 ch[l]=1 이 부분은 이해는 나중에 하고 DFS(l+1)로 재귀 실행이 된다는 것을 알고 가자. 그럼 최종 DFS(4)까지 실행이 된다는 것을 알 수 있다. 이제 jvm의 상황을 그림으로 봐보자.

- jvm stack을 pop
else의 DFS(l+1)을 반복적으로 재귀하여 실행하며 그 이후의
은 아직 실행되지 않고 jvm에 쌓여있는 메서드들을 하나씩 실행해줘야 다음줄로 넘어갈 수 있다.ch[l]=0 DFS(l+1)
- DFS(4)부터 실행
이제 아까 이해하지 않고 넘어갔던 ch[l]=1을 이해해야한다. ch[l]=1이라는 것은 n==4일 때 배열의 1인 index를 모두 출력하기 위해서 사용하는 값이다. 현재 배열의 상태를 그림으로 보면
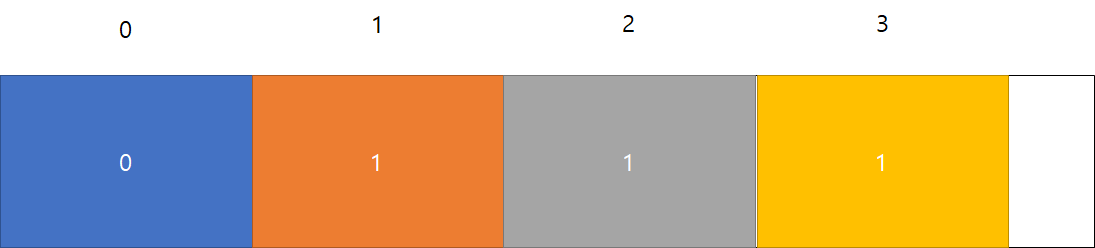
0~3까지 배열의 값이 위 그림과 같이 넣어져있다. 0번째 배열은 우리가 사용하지 않을 것이므로 신경쓰지 않아도 된다. 이렇게 ch 배열 안에 1로 입력되어 있는 배열을 출력하기 위해 우리는 ch[l]=1이란 작업을 했던 것이다. 이제 DFS(4)를 실행하면 l==4에 적용되므로 결과 값으로 1 2 3 이 출력된다. 그리고 jvm을 보면 다음 실행은 DFS(3)이 실행된다. DFS(3)은 DFS(4)의 실행결과를 리턴 받았으므로 그 다음줄을 실행한다.
ch[3]=0
DFS(4)- 위 코드 실행
위 코드를 실행한 배열의 내용은
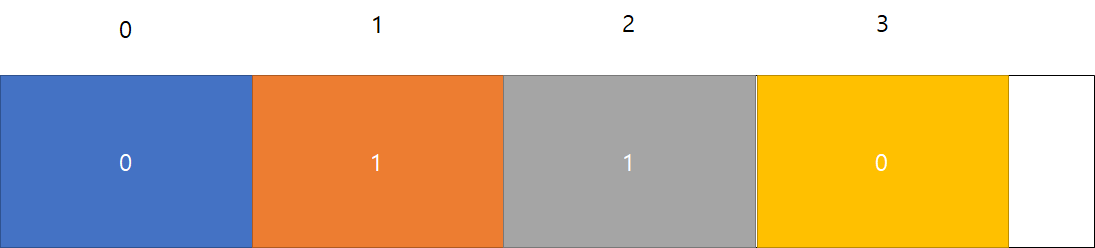
다음과 같으며 DFS(4)가 실행되었으므로 1 2가 출력된다.
이 후에 실행은 DFS(3)이 실행되며 DFS(3)은 다시 DFS(4)를 실행시킨다.
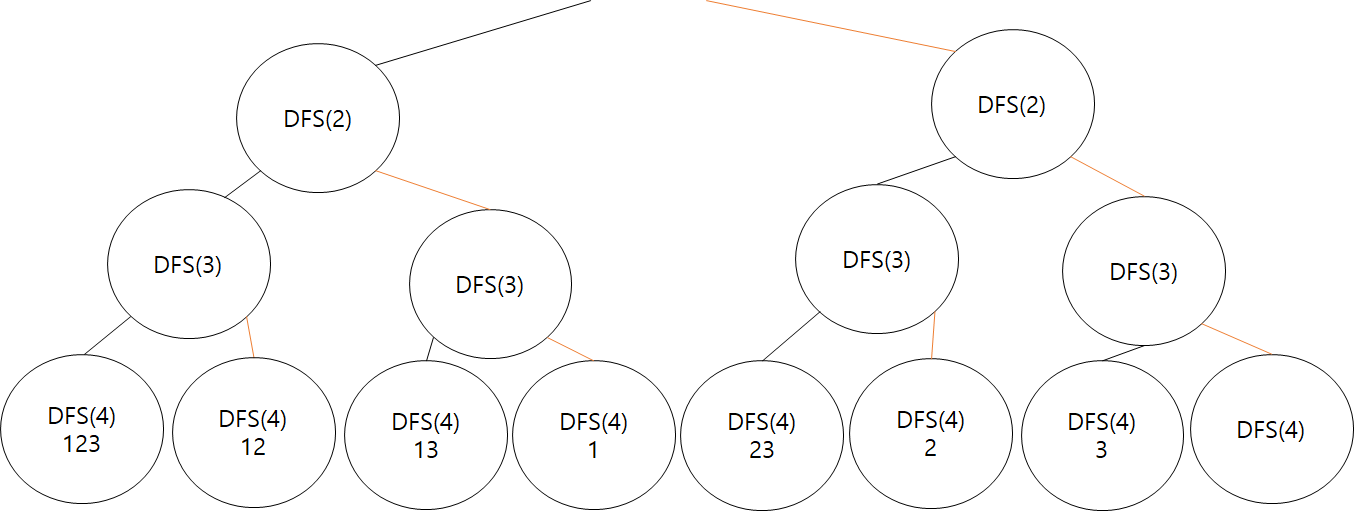
사진이 커져서 잘렸다ㅜㅜ 맨 위에는 DFS(1)이 존재한다.
검은색은 ch[l]=1로 실행한 쪽이고
주황색은 ch[l]=0으로 실행한 쪽이다. 위의 코드를 직접 실행켜 디버그를 찍어보면 위 트리 구조를 이해할 수 있을 것이다.
그리고 DFS(4)에서 출력되는 결과를 적어놨는데 이해에 도움이 되길 바란다!
DFS를 사용하여 트리구조의 알고리즘 풀이
