맥북과 윈도우를 번갈아가며 사용하다보면 가끔 한글이 깨지는 상황을 마주하곤한다. 이러한 현상들은 모두 문자 인코딩 방식과 관련이 있는데 문자열을 인코딩하는 3가지 방식을 이해해보자.
용어정리
-
문자집합(Character set) : 컴퓨터가 이해할 수 있는 문자의 모음 (알파벳, 한글 등등등..)
-
문자 인코딩(encoding) : [인코딩=코드화 하는 과정], 문자집합에 속한 문자 ⇒ 컴퓨터 언어(0,1)
-
문자 디코딩(decoding) : [디코딩=코드를 해석하는 과정], 컴퓨터 언어(0,1) ⇒ 문자집합에 속한 문자
아스키코드
알파벳, 아라비아 숫자, 일부 특수문자 및 제어문자(엔터, 백스페이스)
-
하나의 아스키 문자를 표현하기 위해서는 7비트가 필요 (실제 8비트 사용, 끝 비트는 패리티 비트)
-
7비트 ⇒ 2^7 = 128개 문자 표현 가능 _ _ _ _ _ _ _
-
아스키 코드표 ( A = 65 , a = 97 )
A : 문자집합 ⇒ 65(=코드포인트=문자에 부여된 값)라는 숫자(2진법)로 변경 = 문자 인코딩
-
아스키 코드는 127개의 문자만 변경 가능 ⇒ 턱없이 부족 (8비트 확장 아스키도..) ⇒ 언어별 인코딩 방식 ?!
-
한글 인코딩 방식 : 완성형 vs 조합형 인코딩
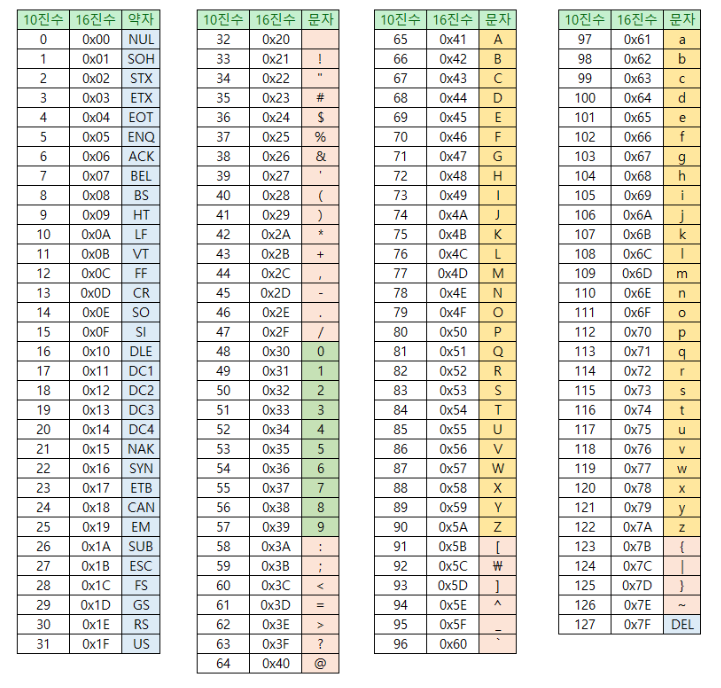
EUC-KR(Extended Unix Code-Korea)
한글 완성형 인코딩 방식의 대표
- 한글을 위한 인코딩 방식
- 완성형 인코딩 방식 : 초성 중성 종성 조합 하나 자체에 고유한 코드 부여
강 : ~~~ - 조합형 인코딩 방식 : 각각에 코드 부여 & 합치기
ㄱ: ~~ ,ㅏ: ~~, ㅇ :~~⇒ EUC-KR = 글자 하나에 2바이트 크기의 코드 부여 : 16비트 = 4bit * 4개 = 16진수 4개 https://dencode.com/ - 2300여개 표현 가능 ⇒ 여전히 부족 (쀏, 뙠, 휔 등등..?)
하지만, 언어별 각각 인코딩 방식이 존재하는 것은 개발시 모든 인코딩 방식을 적용해야하는 문제로 이어져 굉장히 불편한 방식이다.
이런 문제점을 해결하기위해 모든 언어를 표현할 수 있는 문자집합이 필요했고 유니코드, UTF-8 이 등장하게 된다.
유니코드 문자집합과 UTF-8


-
유니코드
- 통일된 문자집합
- 모든 언어 & 특수문자 표현 가능
- 유니코드 인코딩 방식 (UTF = Unicode Transformation Format)
- UTF-8, UTF-16, UTF-32…
- 유니코드 문자표 확인 : https://unicode-table.com/en/blocks
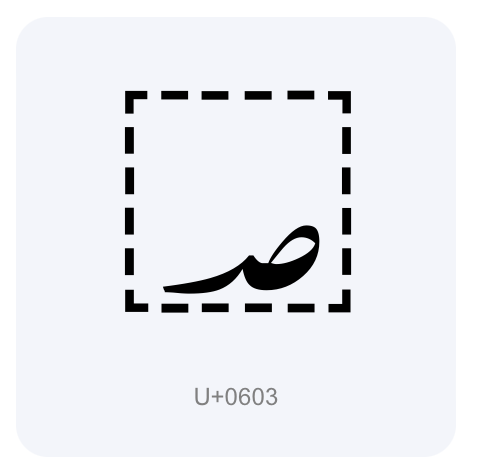
U+0603 ⇒ U+ : 유니코드에 16진수임을 표시 , 0603 ⇒ 고유한 값
고유한 값을 UTF-8,16,32 각각 다른 방식으로 인코딩을 진행
⇒ 컴퓨터 코드로 변경
-
UTF-8
- 가변길이 인코딩: 인코딩 결과가 1~4 바이트
- 인코딩 결과가 몇 바이트가 될지는 유니코드 부여된 값에 따라 상이
- 0603 ⇒ 0000 0110 0000 0011 ⇒ 1100 0000 10110 0000 0011
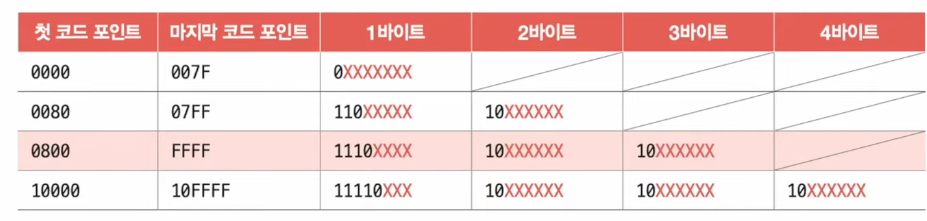
유니코드 ⇒ 바이너리 코드 : https://onlinetools.com/utf8/convert-utf8-to-binary
⇒ [맥과 윈도우 한글이 깨지는 이유??]
궁금한 부분
-
패리티 비트란?
⇒ 통신 과정에서 오류가 생기는 것을 검출 및 수정하기 위한 코드
-
패리티 코드 : 오류 검출만 가능
-
해밍 코드 : 오류 검출, 수정 가능
-
ex) i (105) : 1101001 + 패리티 비트 ⇒
-
홀수 패리티 : 1101001 + 1 (총:5개)
-
짝수 패리티 : 1101001 + 0 (총 :4개)
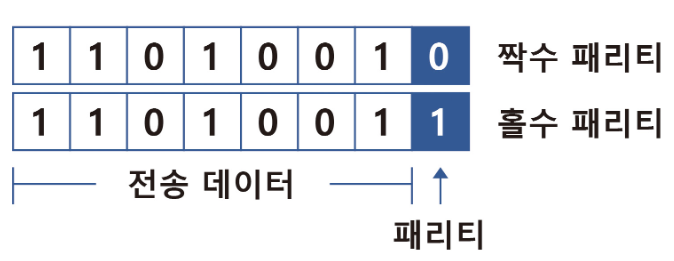
⇒ 전체 1의 개수를 홀수 / 짝수 유지
-
-
왜 필요할까??
⇒ 데이터를 송수신 하는과정에서 각 비트를 단위시간당 하나씩 전송 받게 됨
⇒ 통신 과정에서 비트의 값이 0→1, 1→0 으로 바뀔수 있음
⇒ 패리티 비트를 통해 전체 1의 개수를 검증하여 오류를 점검 할 수 있음
하지만, 오류 여부를 확인할 뿐 수정까지는 불가
+비트 2개가 잘못될 경우 소용없어짐..
-
-
윈도우와 맥이 한글이 깨지는 이유?
- 윈도우 : CP949 ( 확장 완성형 코드 = EUC-KR의 확장형)
- ⇒ 운영체제의 인코딩 방식이 영향을 주는 범위?
- 맥 : UTF-8
- 윈도우 : CP949 ( 확장 완성형 코드 = EUC-KR의 확장형)
추가설명
- 1바이트: 0xxxxxxx (7비트 사용)
- 2바이트: 110xxxxx 10xxxxxx (11비트 사용)
- 3바이트: 1110xxxx 10xxxxxx 10xxxxxx (16비트 사용)
- 4바이트: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (21비트 사용)
U+0603 ⇒ 0000 0110 0000 0011
0603의 범위 = 2바이트 범위에 해당 110xxxxx 10xxxxxx (11비트 사용)
위의 5비트는 버리고 하위비트부터 적용 ⇒ 즉, 하위비트부터 적용한다 !
⇒ 11011000 10000011
⇒ 최종 16비트로 표현할 경우 ‘D8 83’
⇒ 운영체제의 인코딩 방식이 영향을 주는 범위?
- 텍스트 파일과 문서 작성
- 콘솔 및 명령줄
- 파일 시스템 및 파일 인코딩 ⇒ 파일명
