Stack
- 데이터의 삽입과 삭제가 데이터의 가장 한쪽 끝에서만 일어나는 자료구조
- 가장 마지막에 삽입된 데이터가 가장 먼저 사용되거나 삭제 됨(후입선출, LIFO, Last in First Out)
(프링글스 구조) - 데이터를 넣고 빼는 걸 자주하는 자료 구조
Method
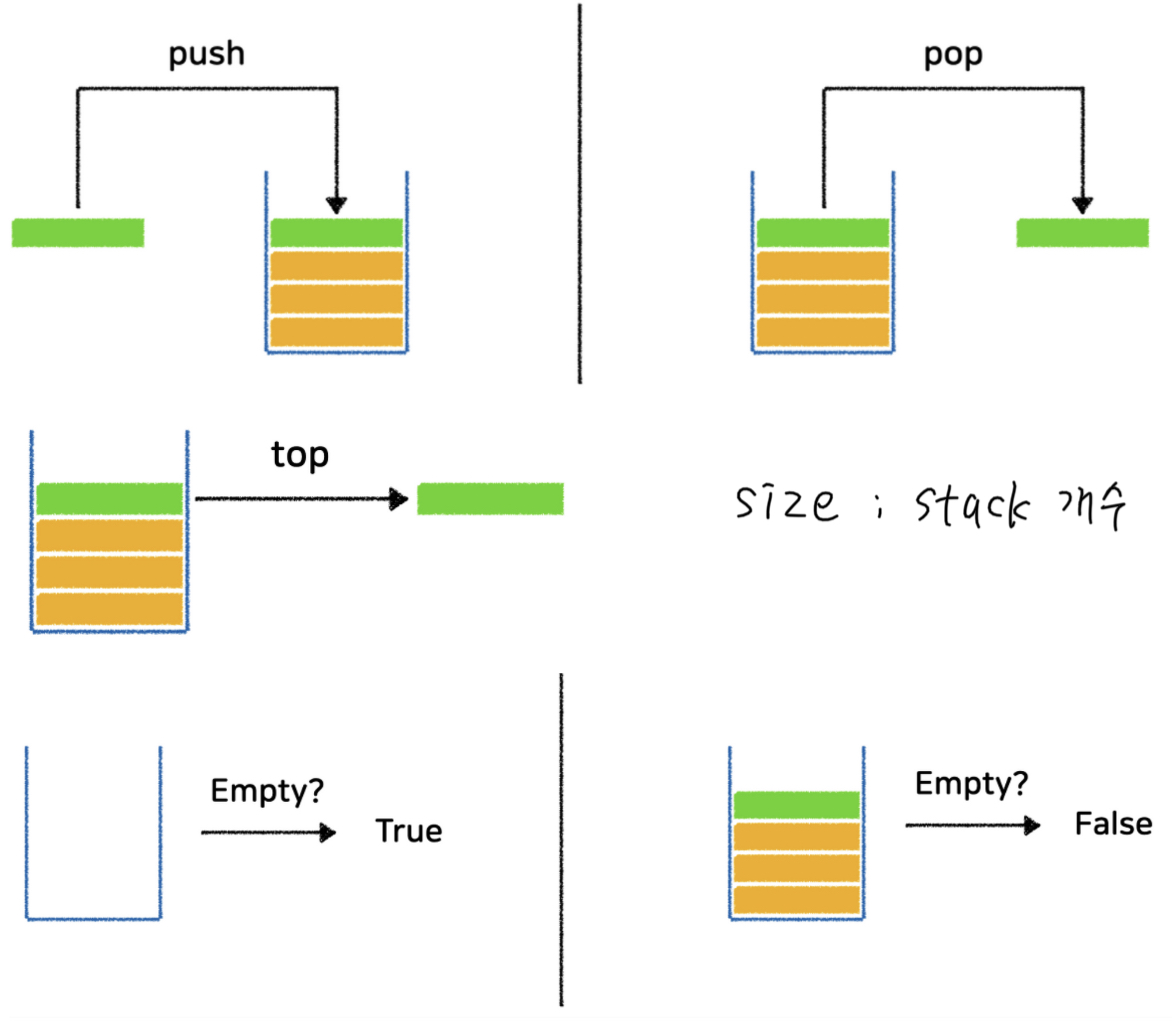
1. push : 맨 위에 데이터 삽입
2. pop : 가장 마지막 데이터를 삭제(stack이 비었는지의 여부를 먼저 확인 후 실행)
3. top : 가장 마지막에 삽입한 데이터를 삭제하지 않고 그대로 return
4. size : stack의 개수
5. isEmpty : 현재 스택이 비어있는지 여부 확인
구현
- python list로 구현
1. 기본
class Stack():
def __init__(self):
self.stack = []
def push(self, data):
self.stack.append(data)
def pop(self):
pop_object = None
if self.isEmpty():
print("Stack is Empty") # Stack is Empty, None을 return
else:
pop_object = self.stack.pop() # 현재 stack의 가장 마지막에 삽입된 값을 return
return pop_object
def top(self):
top_object = None
if self.isEmpty():
print("Stack is Empty")
else:
top_object = self.stack[-1]
return top_object
def isEmpty(self):
is_empty = False
if len(self.stack) == 0:
is_empty = True
return is_empty # stack의 값이 하나도 없을 경우 true, 있을 경우 false를 return
2. 스파르타
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Stack:
def __init__(self):
self.head = None
def push(self, value):
new_head = Node(value)
new_head.next = self.head
self.head = new_head
# pop 기능 구현
def pop(self):
if self.is_empty():
return "Stack is empty!"
delete_head = self.head
self.head = self.head.next
return delete_head
def peek(self):
if self.is_empty():
return "Stack is empty!"
return self.head.data
# isEmpty 기능 구현
def is_empty(self):
return self.head is None
stack = Stack()
stack.push(3)
- python singly linked list로 구현
Queue
- 한쪽 끝으로 자료를 넣고, 반대쪽에서는 자료를 뺄 수 있는 선형구조.
- 순서대로 처리되어야 하는 일에 필요, First In First Out(FIFO)
- 스택과 다르게 큐는 끝과 시작의 노드를 전부 가지고 있어야 하므로,
self.head 와 self.tail 을 가지고 시작
Method
- enqueue(data) : 맨 뒤에 데이터 추가하기
- dequeue() : 맨 앞의 데이터 뽑기
- peek() : 맨 앞의 데이터 보기
- isEmpty(): 큐가 비었는지 안 비었는지 여부 반환해주기
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.head = None
self.tail = None
# head tail
def enqueue(self, value): # [4] - [2]
new_node = Node(value)
if self.is_empty():
self.head = new_node
self.tail = new_node
return
self.tail.next = new_node # 현재 tail 인 [2]의 다음을 [3]으로 지정
self.tail = new_node # 새 tail을 [3]으로 지정
# [4] - [2] - [3]
def dequeue(self):
if self.is_empty():
return "Queue is empty!"
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return "Queue is empty!"
return self.head.data
def is_empty(self):
return self.head is None
Hash table
-
"키" 와 "데이터"를 저장함으로써 즉각적으로 데이터를 받아오고 업데이트하고 싶을 때 사용하는 자료구조
-
해시 함수를 사용하여 색인(index)을 버킷(bucket)이나 슬롯(slot)의 배열로 계산
-
데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행됨(공간을 많이 사용함)
Hash Function
임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수
method
- put(key, value) : key 에 value 저장하기
- get(key) : key 에 해당하는 value 가져오기
class Dict:
def __init__(self):
self.items = [None] * 8
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index] = value
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index]
my_dict = Dict()
my_dict.put("test", 3)
print(my_dict.get("test")) -> 3
충돌(collision)이 생겼을 경우
- 해쉬 값을 배열의 길이로 나눴더니 같은 index가 된 경우
- 체이닝(chaining)
- 개방 주소법(open addressing)
class LinkedTuple:
def __init__(self):
self.items = list()
# 충돌(collision)
# 다른 key값인 경우에도 hash가 같은 index를 반환할 수 있음
# 정보 소실을 막기 위해 ["key1" ,"test"] -> ["key2", "test33"] 으로 연결하고자 함 (체이닝(chaining))
def add(self, key, value):
self.items.append((key, value))
def get(self, key):
for k, v in self.items:
if key == k:
return v
class LinkedDict:
def __init__(self):
self.items = [] # [LinkedTuple, LinkedTuple, ....]
for i in range(8):
self.items.append(LinkedTuple())
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index].add(key, value) # self.items[2] == [("slow", "느린") -> ("fast", "빠른")]
return
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index].get(key) # index = 2이더라도 key 값에 따른 value 반환

하루에 한 개념씩