How LLM Works
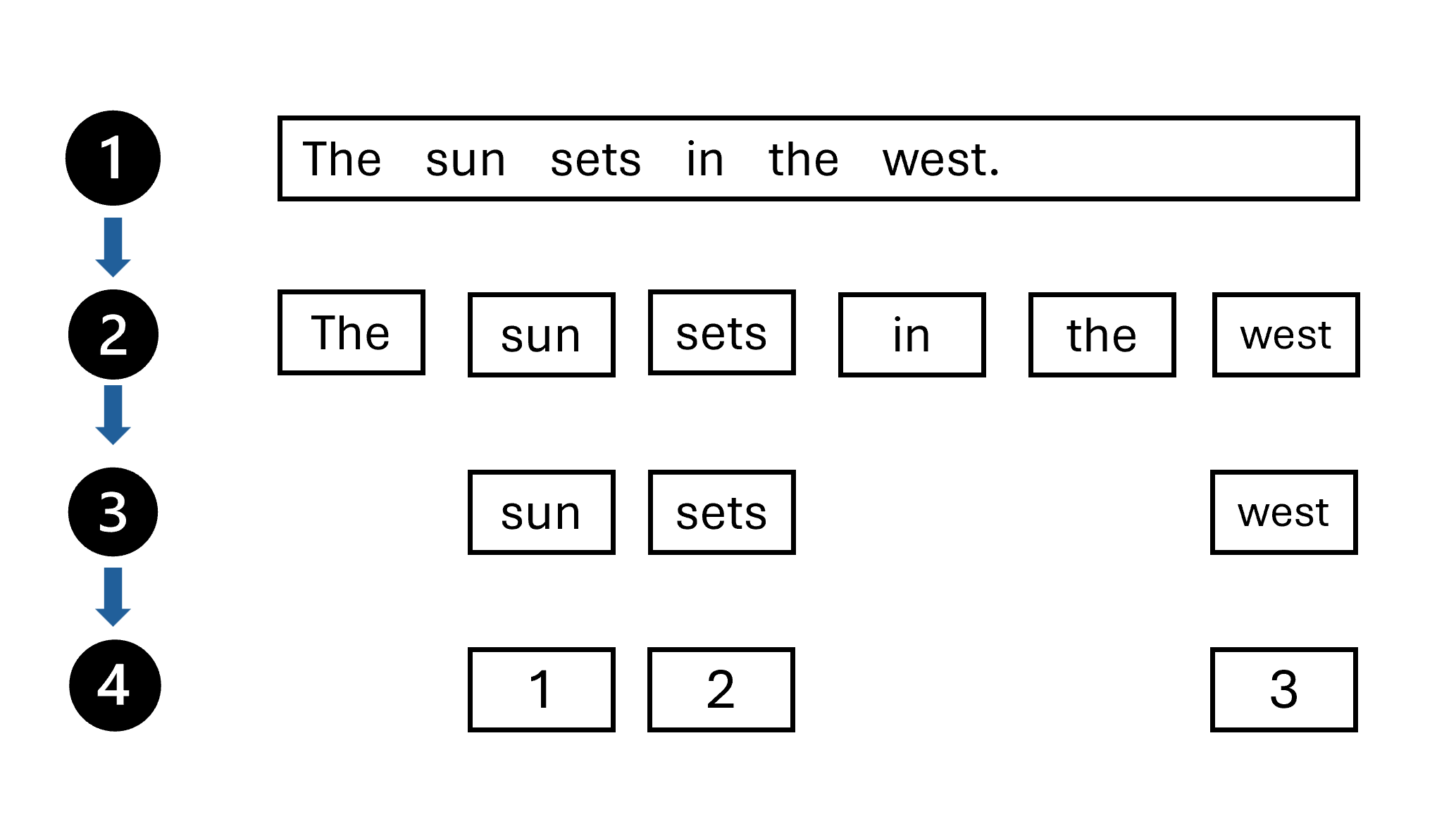
Tokenization
- Tokens are string with a known meaning
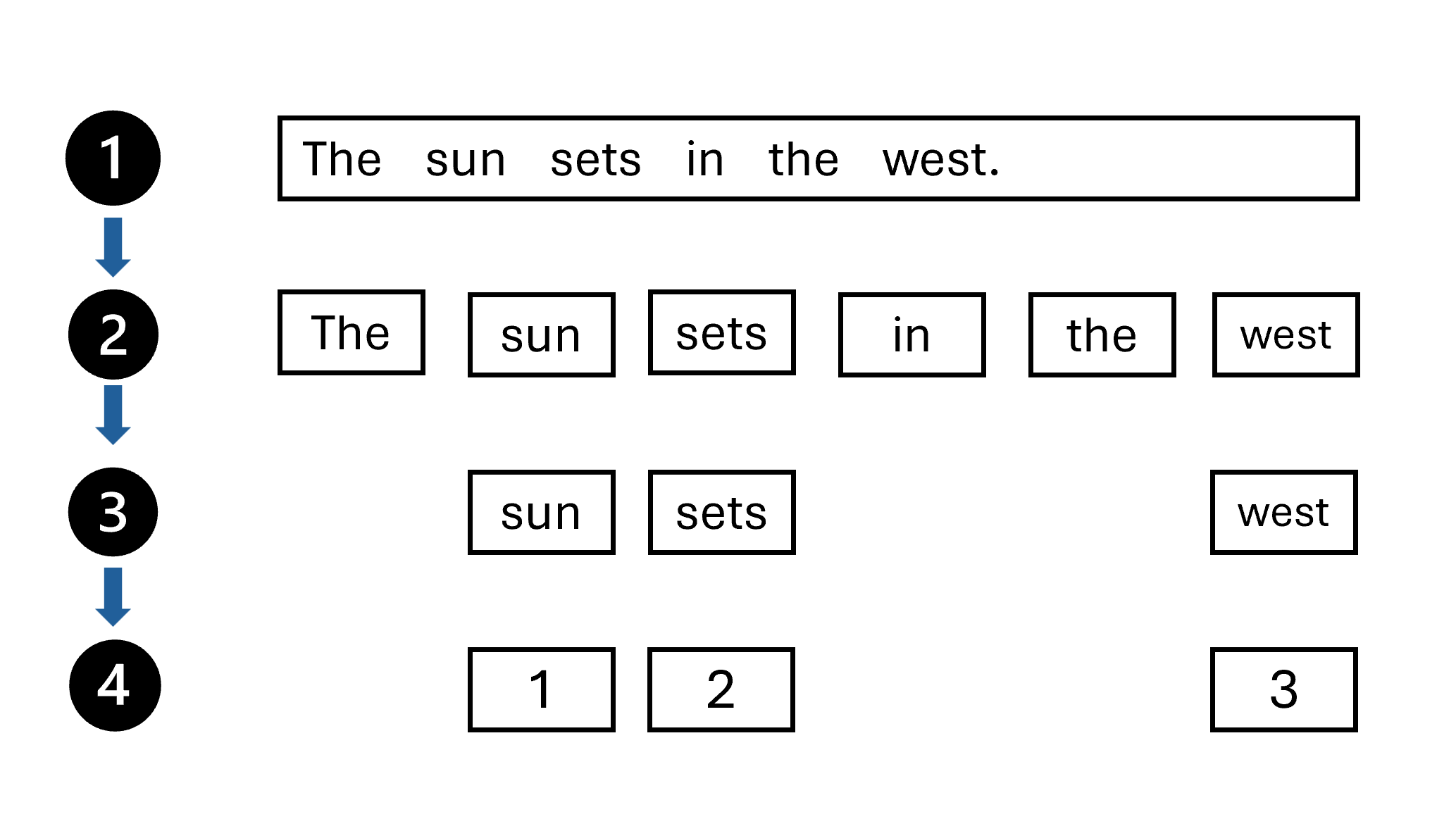
- Start text want to tokenize
- Split the words in the text based on a rule
- Stop word removal
- Assign a number to each unique token
Word Embedding
- Define the semantic relationship between words
- created during model training process
- represented as vectors
- point in n-dimensional space
Machine Learning Model Architecture and RNNs
- Model architecture defines the structure for data processing, training, evaluation, and prediction generation.
- Recurrent Neural Networks (RNNs) were an early breakthrough in language model architecture.
- Context matters: The meaning of a word depends on the surrounding sentence context, not just the word itself.
- RNNs process sequential data:
- Each step takes an input (a new word) and a hidden state (memory from the previous step).
- Hidden states pass information forward, helping the model remember earlier parts of a sentence.
- Example: In a sentence about Vincent Van Gogh, remembering the painter’s name is essential to predicting the next word.
- [MASK] token: Used to indicate a missing word that the model needs to predict in NLP tasks.
Transformer Architecture Overview
- Transformer architecture has two main components:
- Encoder: Processes input sequence and captures token context.
- Decoder: Generates output sequence by attending to encoder output and predicting the next token.
- Key innovations:
- Positional encoding
- Multi-head attention
- In the encoder:
- Input sequence → Positional encoding → Multi-head attention → Encoded representation.
- In the decoder:
- Output sequence → Positional encoding → Multi-head attention → Combines with encoder output → Final output generation.
Understand Positional Encoding
- Position matters for meaning in text.
- Positional encoding adds position information to word embeddings.
- Combines word embedding vectors + positional vectors to encode both meaning and position.
- Simple index values (e.g., "The" = 0, "work" = 1) could be unstable; positional vectors encode position more meaningfully.
Understand Attention
- Attention replaces recurrence (RNNs) to process tokens in parallel, not sequentially.
- Attention mechanism maps new input (query) to learned knowledge (keys and values).
- Example:
- Query: Vincent van Gogh
- Key: Vincent van Gogh
- Value: Painter
- In practice:
- Query, Key, and Value are all encoded into vectors.
- Scaled dot-product computes similarity between query and keys.
- Softmax function produces a probability distribution over keys.
- Highest-probability key determines the output value.
Multi-Head Attention and Efficiency
- Multi-head attention processes tokens multiple times in parallel.
- Enables different "views" of the same input for richer understanding.
- Parallel processing allows for faster and more efficient model training compared to sequential models like RNNs.
How to improve prompt
- 어시스턴트에게 원하는 작업에 대해 구체적인 목표를 설정하세요.
- 응답의 범위를 한정할 수 있는 출처를 제공하세요.
- 적절성과 관련성을 극대화하기 위해 맥락(컨텍스트)을 추가하세요.
- 응답에 대한 명확한 기대사항을 설정하세요.
- 이전 프롬프트와 응답을 기반으로 반복 수정하여 결과를 개선하세요.
Key Mechanisms to Improve Generative AI Responses
-
Grounding Data: Align outputs with factual, contextual, and reliable data sources.
Methods include linking to databases, using search engines for real-time info, or incorporating domain-specific knowledge bases to enhance trustworthiness and relevance. -
Retrieval-Augmented Generation (RAG):
Connects the model to an organization's proprietary database.
Retrieves relevant information from curated datasets to generate contextually accurate and up-to-date responses.
Useful for real-time applications like customer support or knowledge management. -
Fine-tuning:
Further trains a pre-trained model on a task-specific dataset.
Helps the model specialize in a domain, improve accuracy, and reduce irrelevant or inaccurate outputs. -
Security and Governance Controls:
Manage access, authentication, and data usage.
Helps prevent publication of incorrect or unauthorized information.
Metrics to Measure Response Quality
-
Performance and quality evaluators:
Measure accuracy, groundedness, and relevance of generated content. -
Risk and safety evaluators:
Assess risks associated with content generation, ensuring the AI avoids harmful or inappropriate outputs. -
Custom evaluators:
Industry-specific metrics tailored to meet specialized needs and goals. -
Modern services like Azure AI Foundry support these evaluation workflows and responsible AI practices.
