Data
Type
structured data
- 행/열 로 이루어진 데이터
- 관계형 데이터로도 불린다.
- azure SQL DB
Semi structured data
- 정리되어 있지만 완벽한 구조는 없다.
- NoSQL 으로도 불린다.
- Azure cosmos DB
Unstructured data
- 어떤 구조도 가지고 있지 않다.
- 평범한 이진파일들
- EX. 게임 실행파일
- Azure blob storage
-
Parquet
- 저장 방식: 컬럼 단위로 데이터를 저장(열 기반).
- 설명: 데이터 분석에 최적화된 컬럼형 포맷으로, 읽기 속도와 저장 효율이 뛰어남.
-
Avro
- 저장 방식: 로우 단위로 데이터를 저장(행 기반).
- 설명: 직렬화와 역직렬화가 빠른 로우 기반 포맷으로, 실시간 데이터 처리에 적합함.
-
ORC
- 저장 방식: 컬럼 단위로 데이터를 저장(열 기반)하며 색인과 고효율 압축 제공.
- 설명: Hive 환경에 최적화된 컬럼형 포맷으로, 대규모 데이터 처리에 적합함.
--
Delimited Text File
- CSV / TSV
ID,Name,Phone,Address
1,Alice Kim,010-1234-5678,Seoul, Gangnam-gu
2,Bob Lee,010-9876-5432,Busan, Haeundae-gu
3,Charlie Park,010-4567-8910,Incheon, Namdong-guXML
<People>
<Person>
<ID>1</ID>
<Name>Alice Kim</Name>
<Phone>010-1234-5678</Phone>
<Address>Seoul, Gangnam-gu</Address>
</Person>
<Person>
<ID>2</ID>
<Name>Bob Lee</Name>
<Phone>010-9876-5432</Phone>
<Address>Busan, Haeundae-gu</Address>
</Person>
<Person>
<ID>3</ID>
<Name>Charlie Park</Name>
<Phone>010-4567-8910</Phone>
<Address>Incheon, Namdong-gu</Address>
</Person>
</People>JSON
{
"People": [
{
"ID": 1,
"Name": "Alice Kim",
"Phone": "010-1234-5678",
"Address": "Seoul, Gangnam-gu"
},
{
"ID": 2,
"Name": "Bob Lee",
"Phone": "010-9876-5432",
"Address": "Busan, Haeundae-gu"
},
{
"ID": 3,
"Name": "Charlie Park",
"Phone": "010-4567-8910",
"Address": "Incheon, Namdong-gu"
}
]
}- BSON은 MongoDB에서 쓰이는 JSON의 이진 직렬화 형식으로, JSON보다 다양한 데이터 타입을 지원하고, 저장 및 검색을 더 효율적으로 처리하도록 설계되었습니다.
BLOB
- Binary Large Object
- EX. 사진파일
OLTP / OLAP
| 구분 | OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) |
|---|---|---|
| 주요 목적 | 실시간 트랜잭션 처리 (데이터 입력, 갱신, 삭제 등) | 데이터 분석 및 의사결정을 위한 대규모 데이터 조회 |
| 사용 사례 | 은행 거래, 주문 관리, 재고 관리 등 | 데이터 웨어하우스, BI 도구를 이용한 보고서 및 데이터 분석 |
| 작업 유형 | 짧고 빈번한 트랜잭션 | 복잡하고 대규모 데이터 조회 |
| 데이터 구조 | 정규화된 데이터베이스 설계 (Normalized Schema) | 비정규화된 데이터베이스 설계 (Denormalized Schema) |
| 데이터 볼륨 | 소량의 데이터 (단일 트랜잭션 단위) | 대규모 데이터 (전체 데이터 집합 분석) |
| 사용자 | 운영 직원, 고객 | 분석가, 경영진 |
| 응답 시간 | 매우 짧음 (밀리초 수준) | 상대적으로 길음 (초 또는 분 단위) |
| 주요 작업 | CRUD 작업 (Create, Read, Update, Delete) | 집계, 다차원 분석, 데이터 마이닝 |
| 성능 기준 | 높은 처리량과 빠른 응답 시간 | 쿼리 성능과 복잡한 계산 지원 |
| 데이터 최신성 | 실시간 데이터 | 주기적으로 업데이트된 데이터 |
| 예시 시스템 | 은행 시스템, 온라인 쇼핑몰, ERP | 데이터 웨어하우스, OLAP 큐브, BI 플랫폼 |
OLTP가 유리한 데이터
- 변경이 자주 필요한 데이터
- 동시성이 중요한 데이터
OLAP가 유리한 데이터
- 변경이 거의 불필요한 데이터
- 읽기가 주가 되며 장기간 보존하는 데이터
Data Ingestion
- 데이터를 모으는것, DBMS나 파일 등에 저장한다.
- 일정주기로 대량 처리하는 Batch, 실시간으로 처리하는 Real time
Data Processing
- 데이터를 깔끔하게 정제한다.
- 이를 통해 의미있는 정보로 가공
- 쿼리 수행이 가능해진다.
- DB 정규화 포함
ETL (Extract, Transform, Load)
- 데이터를 추출(Extract), 변환(Transform), 적재(Load)하는 전통적인 데이터 처리 방식.
- 데이터를 미리 변환(정제)한 후 적재하기 때문에 보안과 데이터 품질 관리에 유리.
- Stream Oriented (스트림 지향):
- 데이터가 순차적으로 처리되며 쭉 이어진 프로세스처럼 작동.
- 변환 작업이 사전에 이루어지므로 데이터가 목적지에 적재된 후 바로 사용 가능.
- 적합한 경우:
- 데이터 변환이 간단하거나 명확한 규칙이 있는 경우.
- 보안이 중요한 시스템 (예: 온프레미스 환경).
- 사용 도구 예시:
- Apache NiFi, Talend, Informatica.
ELT (Extract, Load, Transform)
- 데이터를 추출(Extract), 적재(Load)한 뒤 필요에 따라 데이터 플랫폼 내에서 변환(Transform)하는 방식.
- 대규모 데이터 처리를 위한 클라우드 환경에 적합.
- 클라우드 기반 도구 예시: Azure Data Factory, Google BigQuery, AWS Glue.
- 유연성:
- 데이터가 원시 형태로 저장되므로 변환 규칙이나 모델링 변경이 쉬움.
- 복잡한 분석 모델이나 비정형 데이터를 처리하는 데 유리.
- 적합한 경우:
- 클라우드 환경에서 대량의 데이터 처리.
- 정제되지 않은 원시 데이터를 다양한 방식으로 활용하려는 경우.
- 단점:
- 원시 데이터가 저장되므로 보안 관리가 추가로 필요할 수 있음.
- 적재 후 변환이 이루어지므로 실시간 사용보다는 사후 분석에 적합.
ETL vs ELT 비교
| 구분 | ETL | ELT |
|---|---|---|
| 순서 | 추출 → 변환 → 적재 | 추출 → 적재 → 변환 |
| 변환 위치 | 데이터 적재 전에 변환 | 데이터 적재 후에 변환 |
| 환경 | 온프레미스 또는 제한된 리소스 환경에 적합 | 클라우드 환경에 최적화 |
| 장점 | 데이터 품질 관리 및 보안 강화 | 대규모 데이터 처리 및 유연한 변환 가능 |
| 단점 | 대규모 데이터 처리에 비효율적일 수 있음 | 보안 관리 필요 및 초기 분석 시간 증가 |
| 사용 사례 | 금융 시스템, 실시간 데이터 처리 | 데이터 웨어하우스, 데이터 레이크 |
| 사용 도구 | Talend, Informatica, Apache NiFi | Azure Data Factory, AWS Glue, Google BigQuery |
Relational Database (RDB)
관계형 데이터베이스는 테이블 형태로 데이터를 구조화하여 저장하고, 행(row)과 열(column)로 데이터를 정의합니다.
구조
- Table (테이블):
- 행(Row)와 열(Column)으로 구성.
- 각각의 행은 엔터티(Entity)의 속성을 정의.
- 열은 데이터 타입(Data Type)에 따라 정의.
- 모든 행은 동일한 열을 가짐.
- Relationships (관계):
- Foreign Key - Primary Key 관계 (FK - PK):
- Foreign Key Constraint: 외래 키를 통해 테이블 간 관계를 정의.
- 데이터 무결성을 보장.
- Foreign Key - Primary Key 관계 (FK - PK):
- Normalization (정규화):
- 데이터를 여러 테이블로 분리하여 중복을 최소화.
- 목적:
- 이상(Anomaly) 방지 (삽입, 삭제, 갱신 이상).
- 데이터 저장 효율성을 향상.
SQL (Structured Query Language)
- 관계형 데이터베이스와 상호작용하는 언어.
- 주요 명령어 분류:
- DDL (Data Definition Language): 데이터베이스 및 테이블 구조 정의. (예:
CREATE,ALTER,DROP) - DML (Data Manipulation Language): 데이터를 조작. (예:
SELECT,INSERT,UPDATE,DELETE) - DCL (Data Control Language): 권한 및 보안 관리. (예:
GRANT,REVOKE)
- DDL (Data Definition Language): 데이터베이스 및 테이블 구조 정의. (예:
장점 (Pros)
- OLTP에 적합:
- 트랜잭션 처리에 강점 (예: 은행 거래).
- 일관성(Consistency), 원자성(Atomicity), 동시성(Concurrency)을 보장.
- 데이터 구조화 및 관계 관리에 강함.
- 강력한 데이터 무결성 및 보안.
단점 (Cons)
- Blob 데이터에 비효율적:
- 대규모 비정형 데이터(이미지, 동영상 등)를 저장하기에는 부적합.
- 그래프 데이터를 표현하기 어려움:
- 복잡한 네트워크 및 그래프 구조를 다루는 데 비효율적.
Clustered Index vs Non-Clustered Index
| 구분 | Clustered Index (클러스터형 인덱스) | Non-Clustered Index (비클러스터형 인덱스) |
|---|---|---|
| 데이터 저장 방식 | 데이터가 디스크 상에서 인덱스의 순서대로 정렬되어 저장. | 인덱스와 실제 데이터가 별도로 저장됨. |
| 특징 | - 데이터의 물리적 순서를 변경하여 테이블을 정렬. | - 데이터의 물리적 순서와 무관하게 인덱스를 유지. |
| - 테이블당 하나만 생성 가능. | - 테이블당 여러 개 생성 가능. | |
| - 주로 Primary Key에 적용. | - 주로 Secondary Key에 적용. | |
| 장점 | - 범위 검색 및 순차 조회에 뛰어난 성능. | - 다양한 쿼리 조건에서 성능 향상. |
| - 데이터 정렬된 상태로 저장되어 빠른 접근 가능. | - 테이블 데이터에 영향을 주지 않고 유연한 인덱싱 제공. | |
| 단점 | - 데이터 삽입, 삭제, 업데이트 시 성능 저하 가능성. | - 클러스터형 인덱스보다 검색 시 다소 느릴 수 있음. |
| - 데이터 크기가 커질수록 관리가 복잡해질 수 있음. | - 추가 스토리지와 처리 시간이 필요. | |
| 사용 사례 | - 주로 기본 키나 자주 검색되는 컬럼. | - 자주 사용되는 검색 조건, 정렬, 필터링 컬럼. |
View (뷰)
-
정의: 데이터베이스에서 가상 테이블로, 쿼리 결과를 동적으로 보여줌.
-
특징:
- 실제 데이터를 저장하지 않음.
- 복잡한 쿼리를 단순화하고 재사용 가능.
- 민감한 데이터를 숨겨 보안 강화.
-
장점:
- 쿼리 단순화, 데이터 보안 제공.
- 기본 데이터 변경 없이 결과만 표시.
- 유지보수와 재사용성 향상.
-
단점:
- 성능 저하 가능성 (실시간 쿼리 실행).
- 데이터 업데이트에 제약.
-
사용 사례:
- 복잡한 쿼리 단순화.
- 민감 정보 보호.
- 집계 데이터 제공.
Azure SQL Database
- Fully Managed (PaaS): 관리형 서비스로 유지보수 및 설정 부담 감소.
- Predictable Performance & Pricing: 성능과 비용이 예측 가능.
- Elastic Pool: 여러 데이터베이스가 공유 리소스를 사용, 예측 불가능한 워크로드 처리에 유리.
- 99.99% SLA: 높은 가용성 보장.
- Geo-Replication: 데이터 복제를 통한 재해 복구 지원.
- Scale Without Downtime: 중단 없이 확장 가능.
- Advanced Security: Azure Advanced Threat Protection과 같은 보안 기능 제공.
배포 옵션
-
Single Database:
- 각 데이터베이스가 독립된 컴퓨팅/메모리/저장소를 사용.
- 멀티 테넌트 환경에서 동작하며, 데이터베이스 단위로 리소스가 격리됨.
- 비용적으로 가장 저렴한 옵션.
- 각각의 데이터베이스가 다른 데이터베이스와 독립적으로 동작.
-
Elastic Pool:
- 고정된 리소스를 여러 데이터베이스가 공유.
- 워크로드가 변동적인 환경(예: 특정 시간대에만 높은 부하 발생)에 적합.
- 개별 데이터베이스보다 비용 효율적일 수 있음.
- 데이터베이스 수요에 따라 자동으로 리소스 분배.
-
Managed Instance:
- 온프레미스 SQL Server에서 쉽게 마이그레이션 가능.
- 각 인스턴스가 보장된 리소스를 사용.
- 인스턴스 수준에서 여러 데이터베이스를 관리.
- 단일 인스턴스 클러스터에 데이터베이스들이 위치함.
- 데이터베이스 간 쿼리 및 트랜잭션을 기본적으로 지원.
- 높은 수준의 SQL Server 기능 호환성 제공 (단, 파일 스트림 및 PolyBase는 미지원).
| 특성 | Azure SQL Database | Azure SQL Managed Instance |
|---|---|---|
| 관리 유형 | 완전 관리형 (PaaS) | 완전 관리형 (PaaS) |
| SQL Server 호환성 | 제한적 (최신 기능 중심) | 높은 호환성 (온프레미스와 유사) |
| SQL Server 기능 지원 | 일부 제한 (SQL Agent 등 미지원) | 대부분 지원 (SQL Agent, CLR 등 포함) |
| 네트워크 구성 | 퍼블릭 엔드포인트, VNet 옵션적 | VNet 필수 (격리된 환경) |
| 사용 사례 | SaaS, 단순 애플리케이션 데이터베이스 | 복잡한 애플리케이션 마이그레이션 |
| 스케일링 | 단일 DB 또는 Elastic Pool | 클러스터, vCore 기반 스케일링 |
| 가격 | 상대적으로 저렴 | 더 비싸지만 기능이 풍부함 |
Azure SQL Database vs Azure SQL Data Warehouse
-
Azure SQL Database
- 용도: OLTP (Online Transaction Processing)
- 특징:
- 주로 트랜잭션 중심 (삽입, 업데이트, 삭제 등 실시간 작업).
- 수직 확장 (Vertical Scale): 단일 서버의 성능을 향상.
- 적합한 사용 사례:
- 은행 거래, 주문 관리 시스템, 실시간 데이터 처리.
-
Azure SQL Data Warehouse (Synapse Analytics)
- 용도: OLAP (Online Analytical Processing)
- 특징:
- 대규모 데이터 분석과 보고서 생성에 최적화.
- 수평 확장 (Horizontal Scale): 여러 노드를 활용해 대량의 데이터를 분산 처리.
- 적합한 사용 사례:
- 데이터 분석, 트렌드 보고서, 비즈니스 인텔리전스.
주요 차이점
| 구분 | Azure SQL Database | Azure SQL Data Warehouse |
|---|---|---|
| 목적 | 트랜잭션 처리 (OLTP) | 데이터 분석 및 보고서 생성 (OLAP) |
| 확장 방식 | 수직 확장 (Vertical Scaling) | 수평 확장 (Horizontal Scaling) |
| 작업 유형 | 짧고 빈번한 트랜잭션 | 복잡한 쿼리와 대규모 데이터 분석 |
| 데이터 구조 | 정규화된 구조 | 비정규화된 구조 (데이터 중복 허용) |
| 사용 사례 | 실시간 트랜잭션 (은행, 주문 관리) | 데이터 웨어하우스, BI 보고서 |
- Azure SQL Database: OLTP에 적합, 실시간 데이터 처리 및 높은 일관성을 제공.
- Azure SQL Data Warehouse: OLAP에 적합, 대규모 데이터 분석과 비즈니스 인텔리전스에 활용.
인터넷에서 데이터베이스 쿼리를 실행하기 위한 필수 조건
-
데이터베이스에 사용자 계정 존재:
- 쿼리를 실행하려면 데이터베이스에 적절한 사용자 계정이 존재해야 합니다.
- 해당 계정이 올바른 자격 증명(아이디 및 비밀번호)을 가지고 있어야 합니다.
-
테이블에 대한 SELECT 권한:
- 사용자가 쿼리할 테이블에 대해
SELECT권한이 부여되어야 합니다.- 예시 SQL 명령:
GRANT SELECT ON [TableName] TO [UserName];
- 예시 SQL 명령:
- 사용자가 쿼리할 테이블에 대해
-
IP 주소 허용:
- 데이터베이스 서버 또는 방화벽에서 쿼리를 실행하려는 클라이언트의 IP 주소를 허용해야 합니다.
- Azure SQL Database의 경우:
- Azure 포털 또는 CLI를 사용하여 IP 주소를 서버 방화벽 규칙에 추가.
- 동적 IP를 사용하는 경우 0.0.0.0을 허용할 수 있지만, 이는 프로덕션 환경에서는 권장되지 않습니다.
- Azure SQL Database의 경우:
- 데이터베이스 서버 또는 방화벽에서 쿼리를 실행하려는 클라이언트의 IP 주소를 허용해야 합니다.
추가 고려 사항
- 데이터베이스 연결:
- 올바른 호스트 이름, 포트, 사용자 이름, 비밀번호가 포함된 연결 문자열을 사용해야 합니다.
- 네트워크 보안:
- 클라이언트와 데이터베이스 간 통신을 보호하기 위해 SSL/TLS를 사용하세요.
- 모니터링 및 로깅:
- 데이터베이스 접근 및 쿼리 실행 내역을 기록하여 보안 준수 및 비인가 접근 감지를 수행하세요.
NoSQL Database Types
-
Key-Value Store
- 설명:
- 데이터를 키(Key)와 값(Value) 쌍으로 저장.
- 간단한 데이터 모델로 빠른 조회에 적합.
- 특징:
- 키를 사용하여 데이터를 효율적으로 조회.
- 값은 JSON, 문자열 등 다양한 형태 가능.
- 예시: Redis, DynamoDB.
- 설명:
-
Document Store
- 설명:
- 데이터를 문서 지향(Document-Oriented) 형식으로 저장.
- 값은 반정형(Semi structured) 데이터(예: JSON, YAML)로 구성됨.
- 특징:
- 문서 내부에서 키-값 쌍으로 데이터 관리.
- 복잡한 데이터 구조도 유연하게 저장 가능.
- 예시: MongoDB, Couchbase.
- 설명:
-
Column Store
- 설명:
- 열(Column) 중심의 데이터 모델로 데이터를 저장.
- 각 Column은 자체적으로 관리된다.
- 각 행(Row)은 다른 열 구성을 가질 수 있음.
- 열(Column) 중심의 데이터 모델로 데이터를 저장.
- 설명:
| ID | Name | Age | Country |
|---|---|---|---|
| 1 | Alice | 25 | USA |
| 2 | Bob | Canada | |
| 3 | Charlie | 35 |
- 특징:
- 대량의 데이터를 효율적으로 분석 및 조회.
- OLAP
- 열 단위로 저장하므로 읽기 성능이 높음.
- 대량의 데이터를 효율적으로 분석 및 조회.
- 예시: Apache Cassandra, HBase.
-
Graph Store
- 설명:
- 데이터 간의 관계를 중점으로 저장 및 조회.
- 노드(Node)와 간선(Edge)으로 관계를 표현.
- 특징:
- 복잡한 데이터 관계를 빠르게 조회 가능.
- 예: 소셜 네트워크, 추천 시스템.
- 예시: Neo4j, Amazon Neptune, Gramlin
- 설명:
-
Mixed (Hybrid)
- 설명:
- NoSQL 데이터베이스는 여러 데이터 모델을 혼합하여 사용 가능.
- 한 데이터베이스에서 키-값, 문서, 그래프 등의 구조를 모두 활용.
- 예시: CosmosDB, ArangoDB.
- 설명:
JSON File
- 특징:
- 가독성이 높고 경량화된 데이터 형식.
- 데이터를 키-값 쌍으로 표현하며, 유연한 구조 지원.
- 사용 예시:
- REST API 응답 형식, Document Store 데이터 표현.
Azure에서 NoSQL 데이터 처리 방법
Azure는 NoSQL 데이터베이스와 비정형 데이터를 처리하기 위해 다양한 솔루션을 제공합니다. 이는 IaaS에서 완전 관리형 서비스까지 범위를 아우릅니다.
1. IaaS VM
- 가상 머신(VMs)을 사용하여 NoSQL 데이터베이스(예: MongoDB, Cassandra, Redis)를 직접 호스팅하고 관리.
- 특징:
- 데이터베이스 구성 및 확장에 대한 완전한 제어.
- 데이터베이스 소프트웨어, 백업, 확장을 직접 관리해야 함.
2. Azure Storage
Azure Storage는 비정형 및 반정형 데이터를 위한 확장 가능한 스토리지 옵션을 제공합니다.
-
Blob Storage:
- 대규모 비정형 데이터(예: 이미지, 동영상, 백업)를 저장.
- 객체 스토리지에 적합.
-
Table Storage:
- 키-값 쌍으로 구성된 구조적 NoSQL 데이터를 저장.
- 가볍고 간단한 NoSQL 솔루션에 적합.
-
File Storage:
- SMB 프로토콜을 사용하는 완전 관리형 공유 파일 스토리지.
- 공유 파일 접근이 필요한 애플리케이션에 적합.
-
Queue Storage:
- 비동기식 통신을 위한 메시지 큐 제공.
- 애플리케이션 구성 요소 간 결합도를 낮추는 데 유용.
3. Cosmos DB
- Azure의 완전 관리형 NoSQL 데이터베이스 서비스로, 다양한 NoSQL 모델을 지원:
- 키-값(Key-Value): 키를 사용한 효율적인 데이터 조회.
- 문서(Document): JSON과 같은 반정형 데이터 저장.
- 컬럼 패밀리(Column-Family): 분석 워크로드에 최적화.
- 그래프(Graph): 관계 기반 데이터 모델 지원.
- 주요 특징:
- 글로벌 분산 및 멀티 리전 복제.
- 99% 타일 지연 시간 SLA 보장.
- 자동 확장 및 유연한 처리량 제공.
요약
| 서비스 | 목적 | 사용 사례 |
|---|---|---|
| IaaS VM | NoSQL 데이터베이스 직접 호스팅 및 관리. | 데이터베이스 관리에 대한 완전한 제어가 필요한 경우. |
| Azure Blob | 비정형 데이터 저장. | 이미지, 동영상, 백업과 같은 대규모 파일 저장. |
| Azure Table | 구조화된 NoSQL 데이터를 위한 키-값 스토어. | 가볍고 낮은 지연 시간이 요구되는 애플리케이션. |
| Azure File | 관리형 공유 파일 스토리지. | 공유 파일 접근이 필요한 애플리케이션. |
| Azure Queue | 메시지 큐를 통한 비동기 통신. | 구성 요소 간 비동기 데이터 전달. |
| Cosmos DB | 글로벌 스케일의 완전 관리형 NoSQL 데이터베이스. | 멀티 모델 NoSQL(키-값, 문서, 그래프 등). |
Azure Storage Redundancy (Azure 스토리지 중복성)
Azure는 데이터를 안전하고 고가용성으로 유지하기 위해 다양한 중복 옵션을 제공합니다.
기본 개념
- 리전(Region): Azure의 물리적 데이터 센터 위치.
- 가용성 영역(Availability Zone): 하나의 리전에 있는 다수의 독립적인 데이터 센터 그룹.
- 데이터 센터(Data Center): 물리적 서버가 위치한 개별 장소.
스토리지 중복성 옵션
LRS, GRS, RA-GRS
| 옵션 | 복제 방식 | 특징 | 사용 사례 |
|---|---|---|---|
| Locally Redundant Storage (LRS) | 동일 데이터 센터 내에서 3개의 동기화 복사본 저장. | - 비용 효율적. - 단일 데이터 센터 장애 발생 시 데이터 손실 가능. | 단일 리전 내에서 비용 효율적 데이터 저장. |
| Geo-Redundant Storage (GRS) | LRS 기반으로, 보조 리전에 비동기 복사 수행. | - 데이터가 2개의 리전에 걸쳐 복제. - 보조 리전은 기본적으로 읽기 불가. | 지역 단위 장애 복구가 중요한 데이터. |
| Read-Access Geo-Redundant Storage (RA-GRS) | GRS 기반으로, 보조 리전에서 데이터를 읽기 전용으로 접근 가능. | - 데이터를 총 6개의 복사본으로 저장. - 재해 복구 중에도 읽기 작업 가능. | 재해 복구와 동시에 읽기 작업이 필요한 환경. |
ZRS, GZRS, RA-GZRS
| 옵션 | 복제 방식 | 특징 | 사용 사례 |
|---|---|---|---|
| Zone-Redundant Storage (ZRS) | 하나의 리전에 있는 3개의 가용성 영역에 동기화 복사본 저장. | - 데이터 센터 장애 발생 시에도 데이터 접근 가능. - 지역 단위 장애 대비 불가. | 높은 가용성을 요구하는 워크로드. |
| Geo Zone-Redundant Storage (GZRS) | ZRS 기반으로, 보조 리전에 비동기 복사 수행. | - ZRS의 높은 가용성과 지역 단위 재해 복구 기능 제공. - 데이터가 2개의 리전에 걸쳐 복제. | 최고 수준의 복원성과 가용성이 필요한 경우. |
| Read-Access Geo Zone-Redundant Storage (RA-GZRS) | GZRS 기반으로, 보조 리전에서 데이터를 읽기 전용으로 접근 가능. | - 데이터를 총 6개의 복사본으로 저장. - 재해 복구 중에도 읽기 작업 가능. | 재해 복구와 읽기 작업이 동시에 필요한 환경. |
요약
- LRS → GRS → RA-GRS: 단일 데이터 센터에서 시작해 지역 단위 재해 복구 및 읽기 작업 지원.
- ZRS → GZRS → RA-GZRS: 가용성 영역을 기반으로 확장, 지역 단위 재해 복구 및 읽기 작업 지원.
- 단, 쓰기 가능한 여러 지역(Multi-write regions)은 지원되지 않음.
Azure Blob Storage
Azure Blob Storage는 대규모 비정형 데이터를 저장할 수 있는 객체 스토리지입니다. 다양한 파일 형식을 지원하며, 특정 용도에 따라 블랍 유형이 나뉩니다.
Blob 유형
-
Block Blobs
- 용도: 파일 데이터를 읽기 위해 사용.
- 특징:
- 데이터를 처음부터 끝까지 순차적으로 읽는 작업에 적합.
- 주로 이미지, 동영상, 문서 파일 저장에 사용.
-
Page Blobs
- 용도: 랜덤 읽기/쓰기가 필요한 데이터를 저장.
- EX. VHD
- 특징:
- Azure Virtual Machines의 디스크 데이터 저장에 최적화.
- 데이터의 특정 페이지를 읽거나 수정 가능.
- 용도: 랜덤 읽기/쓰기가 필요한 데이터를 저장.
-
Append Blobs
- 용도: 추가 작업(Append)에 최적화.
- 특징:
- 데이터를 끝에만 추가 가능 (수정 및 삭제는 지원되지 않음).
- 로그 데이터 저장과 같은 순차적 기록 작업에 적합.
요약
| Blob 유형 | 용도 | 특징 | 사용 사례 |
|---|---|---|---|
| Block Blobs | 파일 저장 및 순차적 읽기 작업. | 데이터를 처음부터 끝까지 읽는 작업에 적합. | 이미지, 동영상, 문서 파일. |
| Page Blobs | 랜덤 읽기/쓰기. | 특정 페이지 데이터를 수정 가능. | Azure VM 디스크 데이터. |
| Append Blobs | 끝에 데이터를 추가. | 수정/삭제 불가, 추가 작업만 가능. | 로그 데이터 저장. |
Azure Storage Access Tier
Azure Storage는 데이터 액세스 빈도에 따라 HOT, COOL, ARCHIVE의 3가지 액세스 계층을 제공합니다. 각 계층은 비용, 성능, 데이터 보존 기간에 따라 최적화됩니다.
Access Tier 비교
| Tier | 설명 | 특징 | 적합한 사용 사례 |
|---|---|---|---|
| HOT | 자주 액세스하는 데이터 | - 낮은 지연 시간. - 높은 액세스 비용. - 저장 비용이 상대적으로 높음. | - 자주 사용되는 애플리케이션 데이터. - 실시간 분석 데이터. |
| COOL | 가끔 액세스하는 데이터 | - 높은 지연 시간. - 저장 비용이 낮음. - 데이터를 최소 30일 저장해야 함. | - 백업 데이터. - 주기적으로 사용하는 데이터. |
| ARCHIVE | 거의 액세스하지 않는 데이터 | - 매우 높은 지연 시간 (수 시간). - 저장 비용이 매우 낮음. - 데이터 복원이 필요. | - 법적 보존 데이터. - 장기 보관 아카이브. |
요소별 비교
| 요소 | HOT | COOL | ARCHIVE |
|---|---|---|---|
| 액세스 빈도 | 빈번하게 액세스 | 드물게 액세스 | 거의 액세스하지 않음 |
| 지연 시간 (Latency) | 낮음 | 중간 | 매우 높음 (수 시간) |
| 저장 비용 | 높음 | 낮음 | 매우 낮음 |
| 액세스 비용 | 낮음 | 중간 | 높음 |
| 최소 저장 기간 | 없음 | 30일 이상 | 180일 이상 |
Azure Table Storage
Azure Table Storage는 단순하고 확장 가능한 NoSQL 키-값 데이터베이스로, 비정형 데이터를 효율적으로 저장하고 검색하기 위한 방법
특징
-
NoSQL Key-Value Storage:
- 데이터는 키(Key)와 값(Value)로 구성된 단순한 형태.
- 각 행(Row)에 고유한 키(PartitionKey + RowKey)와 값이 저장됨.
-
관계 없음:
- 테이블 간의 관계, 절차, 외래 키(Foreign Key), 보조 인덱스(Secondary Index) 없음.
- 데이터는 보통 비정규화(denormalized)된 형태로 저장.
-
파티셔닝 지원:
- 데이터는 여러 파티션(Partition)으로 나눌 수 있어 대규모 데이터 처리 가능.
- 각 파티션은 고유한 PartitionKey로 식별됨.
- 각 파티션 내에서 Rowkey는 고유한 값을 가짐
-
대량 데이터 지원:
- 대규모 데이터를 저장하고 관리할 수 있는 확장성.
-
반정형 데이터:
- 스키마가 고정되지 않고, 동적으로 열(Column)을 추가 가능.
-
빠른 데이터 처리:
- 데이터의 삽입 및 검색이 빠름.
- 복잡한 관계형 작업 없이 단순한 데이터 액세스 작업에 최적화.
-
단순한 확장성:
- 구조가 단순하여 수평적 확장이 용이.
-
Cosmos DB와의 관계:
- Cosmos DB는 Azure Table Storage의 발전된 버전.
- Table Storage는 간단한 키-값 스토어, Cosmos DB는 더 많은 기능(예: 보조 인덱스, 다중 API 지원)을 제공.
장점
- 간단한 데이터 모델.
- 빠른 읽기 및 쓰기 성능.
- 데이터 스키마가 유연하며 반정형 데이터를 처리 가능.
- 대규모 데이터 저장과 확장성.
제한 사항
- 테이블 간 관계를 정의할 수 없음.
- 복잡한 쿼리나 조인이 불가능.
- 보조 인덱스(Secondary Index) 미지원.
Azure File Storage
Azure File Storage는 클라우드에서 완전 관리형 파일 공유를 제공하며, 온프레미스와 클라우드 환경 모두에서 접근할 수 있는 서비스입니다.
특징
-
클라우드 기반 파일 공유:
- Azure에서 파일 공유를 생성하고 VM 또는 온프레미스 서버에서 연결 가능.
- 다양한 플랫폼에서 파일 공유 지원.
-
마운트 가능:
- SMB(서버 메시지 블록) 또는 NFS(Network File System) 프로토콜을 사용하여 파일 공유를 마운트 가능.
- 네트워크 드라이브처럼 사용 가능.
-
전송 중 암호화:
- 클라우드와 클라이언트 간 데이터 전송은 항상 암호화되어 보안 유지.
-
접근성:
- 인터넷을 통해 파일 공유에 어디서나 연결 가능.
장점 (Pros)
-
Shared Access (공유 접근):
- 여러 VM과 서버에서 동시에 파일 공유에 접근 가능.
- 파일 공유를 통해 협업 및 데이터 통합.
-
Fully Managed (완전 관리형):
- 스토리지 관리, 유지보수, 백업 등 인프라 관리를 Azure가 처리.
- 사용자는 데이터 관리와 사용에만 집중.
-
Resiliency (복원력):
- 데이터가 고가용성과 복원력을 제공하도록 설계됨.
- Azure의 복제 기능(LRS, ZRS, GRS 등)을 통해 데이터 손실 방지.
단점 (Cons)
-
성능 한계:
- 초고속 처리 및 대규모 작업에는 제한이 있을 수 있음.
- 고성능 IOPS를 요구하는 워크로드에 적합하지 않을 수 있음.
-
비용:
- 장기적으로 대규모 데이터를 저장하면 비용이 증가할 수 있음.
- 특히 고빈도 접근 시 비용 부담.
-
지원 제한:
- 일부 특수 파일 시스템 기능은 지원되지 않을 수 있음.
- 특정 환경이나 요구사항에 적합하지 않을 가능성.
-
지연 시간:
- 온프레미스에서 사용 시 클라우드 네트워크와의 연결로 인해 지연 시간이 발생할 수 있음.
Cosmos DB
Azure Cosmos DB는 글로벌 분산 데이터베이스로, 완전 관리형 데이터베이스 서비스(Database-as-a-Service)를 제공합니다. 다양한 데이터 모델과 API를 지원하며, 고성능과 유연성을 제공합니다.
- 여러 JSON 파일을 모으는데 사용하기 쉽다.
주요 특징
-
글로벌 분산(Global Distribution):
- 전 세계 여러 리전에 데이터를 복제하여 높은 가용성과 낮은 지연 시간 제공.
-
완전 관리형(Fully Managed):
- 서버 관리, 스키마 및 인덱스 관리를 자동화.
-
서버리스(Serverless):
- 필요에 따라 리소스를 확장하거나 축소 가능.
-
멀티모델 및 멀티언어(Multi-Model/Multi-Language):
- JSON, 테이블, 그래프, 열 기반(Columnar) 등 다양한 데이터 모델과 API를 지원.
-
높은 가용성(High Availability):
- 99.999% SLA로 항상 사용 가능.
-
무제한 확장성(Unlimited Scale):
- 스토리지 및 처리량(Throughput)을 무제한 확장 가능.
-
일관성 선택(Consistency Choice):
- 5가지 일관성 레벨 제공: Strong, Bounded Staleness, Session, Consistent Prefix, Eventual.
지원 모델 및 API
-
Cosmos NoSQL API / Table
- Key-Value 스토어: 간단한 키-값 데이터 모델.
- Table Storage와 호환되며, 고객은 Cosmos DB로 마이그레이션 가능.
- 특징:
- 행(Row)의 값은 숫자나 문자열 같은 간단한 데이터만 저장 가능.
- 객체 저장은 불가능.
-
Cassandra API
- Wide-Column 모델:
- 행마다 열의 이름과 형식이 다를 수 있음.
- 고도로 유연한 데이터 구조.
- 적합한 사용 사례:
- 대량의 읽기/쓰기 워크로드 처리.
- Wide-Column 모델:
-
Gremlin API
- 그래프 모델:
- 노드와 간선으로 데이터 관계를 표현.
- SNS, IoT 등 현실 세계의 관계형 데이터를 저장하고 분석.
- 적합한 사용 사례:
- 소셜 네트워크 분석, 추천 시스템.
- 그래프 모델:
-
MongoDB API / Cosmos DB SQL API
- 문서(Document) 모델:
- MongoDB: BSON(Binary JSON) 기반.
- Cosmos DB SQL API: JSON 기반.
- 적합한 사용 사례:
- 반정형 데이터 저장, 유연한 문서형 데이터베이스 요구.
- 문서(Document) 모델:
요약
| 특징 | 설명 |
|---|---|
| 글로벌 분산 | 전 세계 여러 리전에 데이터 복제. |
| 완전 관리형 | 스키마 및 인덱스 자동 관리, 서버 관리 불필요. |
| 멀티모델 지원 | JSON, 테이블, 그래프, 열 기반(Columnar) 모델 지원. |
| 일관성 선택 | 5가지 일관성 수준 제공 (Strong ~ Eventual). |
| 무제한 확장성 | 스토리지와 처리량(Throughput)을 무제한으로 확장 가능. |
| 주요 API | NoSQL, Cassandra, Gremlin, MongoDB, SQL Core API. |
메타데이터
- 데이터를 설명하는 데이터
- 주로 blob으로 저장
데이터 웨어하우스와 Azure Data Lake: 데이터 관리의 핵심 요소
데이터 웨어하우스 (Data Warehouse)
데이터 웨어하우스는 다양한 데이터 소스에서 데이터를 가져와 정리(Cleaning), 변환(Transforming), 검증(Validating), 집계(Aggregating) 작업을 거친 후 SQL 형식으로 저장하고 이를 활용하는 중앙 저장소입니다.
대규모 데이터 처리를 가능하게 하며, 비즈니스 인텔리전스(BI)와 분석을 위한 기반 시스템으로 사용됩니다.
주요 역할
- 데이터를 통합하여 저장하고 관리
- SQL 쿼리를 통한 고성능 분석 지원
- 비즈니스 의사결정을 위한 보고 및 데이터 활용 가능
- 다른 클라우드 프로바이더와 호환성
데이터웨어하우스 스타 스키마
- 스타 스키마: 데이터웨어하우스 설계 방식 중 하나로, 중앙의 팩트 테이블과 주변의 디멘션 테이블이 별 모양으로 연결된 구조.
- 장점: 이해와 설계가 간단하고, 쿼리 성능이 뛰어남.
- 단점: 데이터 중복 가능성 증가.
팩트 테이블 (Fact Table)
- 역할: 비즈니스 프로세스에서 측정된 수치 데이터를 저장.
- 특징:
- 숫자 데이터 (측정값) 포함.
- 디멘션 테이블의 외래 키를 통해 데이터를 연결.
- 크기가 큼 (대량의 데이터).
디멘션 테이블 (Dimension Table)
- 역할: 팩트 테이블에 대한 컨텍스트(설명)를 제공.
- 특징:
- 텍스트 데이터 (속성값) 포함.
- 외래 키 없이 기본 키로만 구성.
- 크기가 작음 (상대적으로 적은 데이터).
데이터 웨어하우스 내부에서 이루어지는 주요 작업
- 로딩 (Loading): 다양한 소스에서 데이터를 가져와 적재.
- 분석 (Analyzing): 쿼리를 실행해 데이터로부터 유용한 인사이트 도출.
- 보고서 작성 (Reporting): 데이터를 기반으로 보고서를 생성.
- 관리 (Managing): 데이터를 유지보수하고 최적화.
- 내보내기 (Exporting): 외부 분석을 위해 데이터를 추출.
Azure Data Lake란?
Azure Data Lake는 Azure 클라우드에서 제공하는 대규모 데이터 저장소로, 데이터 관리의 유연성과 확장성을 제공합니다.
주요 특징
- 데이터 유형: 정형, 비정형, 반정형 데이터를 모두 지원.
- 대규모 저장소: 데이터를 원시 상태로 저장하여 분석 준비 가능.
- 비용 효율성: 데이터를 미리 정형화하지 않아도 되어 저장 비용 절감.
- 분산 처리 지원: Hadoop, Spark 등으로 대규모 데이터를 처리.
데이터 웨어하우스와 Azure Data Lake의 차이점
| 항목 | 데이터 웨어하우스 | Azure Data Lake |
|---|---|---|
| 데이터 유형 | 정형 데이터만 처리 | 정형, 비정형, 반정형 데이터 모두 지원 |
| 목적 | 비즈니스 분석 및 보고 | 데이터 저장, 처리, 데이터 사이언스용 분석 환경 제공 |
| 데이터 처리 | ETL(Extract, Transform, Load) | ELT(Extract, Load, Transform) |
| 확장성 | 용량이 제한적일 수 있음 | 대규모 데이터를 위한 무제한 확장성 제공 |
| 비용 구조 | 사용되는 용량 및 성능에 따라 비용 발생 | 저장 용량 기준으로 저렴하며, 처리 시 추가 비용 발생 |
데이터 웨어하우스와 Azure Data Lake의 협력 관계
Azure Data Lake와 데이터 웨어하우스는 데이터 파이프라인 내에서 상호 보완적으로 동작하며, 유연성과 고성능 분석을 결합합니다.
데이터 처리 과정
Azure Data Lake와 데이터 웨어하우스는 데이터 파이프라인에서 협력하여 데이터를 효과적으로 관리합니다. 아래는 이 협력 과정의 주요 단계입니다:
-
Ingestion (데이터 수집)
- Azure Data Lake를 사용해 다양한 소스(ERP, CRM, IoT, 로그 데이터)에서 데이터를 원시 상태로 수집하고 저장.
- ETL(Extract, Transform, Load) 또는 실시간 스트리밍 방식을 활용.
-
Explore (데이터 탐색)
- Azure Data Lake에 저장된 데이터를 탐색하여 패턴을 파악하고 품질을 점검.
- Spark, Hadoop 등의 분산 처리 엔진을 사용해 대규모 데이터 탐색.
-
Prep/Train (데이터 전처리 및 모델 학습)
- 탐색 후, 정제된 데이터를 데이터 웨어하우스로 전송하여 전처리와 모델 학습을 수행.
- 데이터 구조화 및 분석 준비.
-
Model/Serve (모델 서비스화)
- 데이터 웨어하우스에 저장된 데이터를 활용해 분석 보고서를 작성하거나, 머신러닝 모델을 배포하여 실시간 예측과 비즈니스 분석에 활용.
결론
데이터 웨어하우스와 Azure Data Lake는 데이터 저장, 처리, 분석에서 상호 보완적입니다:
- Azure Data Lake는 유연한 데이터 저장 및 대규모 처리에 강점을 가지며, 다양한 데이터 유형을 지원합니다.
- 데이터 웨어하우스는 고성능 쿼리와 정형 데이터를 활용한 분석 및 비즈니스 인텔리전스를 제공합니다.
Datalake Gen2 : 블롭 스토리지를 같이 사용한다.
Data Warehouse와 Azure Data Lake: 통합 플랫폼 Azure Synapse Analytics
Azure Synapse Analytics: 데이터 웨어하우스와 Data Lake의 통합
Azure Synapse Analytics는 데이터 웨어하우스와 Azure Data Lake를 통합하여 두 시스템 간의 경계를 허물고, 데이터를 더 유연하게 분석할 수 있는 플랫폼입니다. 이를 통해 조직은 정형 및 비정형 데이터를 단일 환경에서 관리하고 분석할 수 있습니다.
주요 특징
-
통합된 분석 환경
- 데이터를 이동시키지 않고 Azure Data Lake와 데이터 웨어하우스의 데이터를 동시에 분석할 수 있는 단일 환경 제공.
- 데이터 소스 간의 경계를 제거해 데이터 처리 효율성 극대화.
- Apache Spark를 사용
- 더욱 빠른 처리 속도
-
하이브리드 쿼리 지원
- SQL을 사용하여 정형화된 데이터뿐만 아니라 비정형 데이터까지 쿼리 가능.
- 단일 쿼리로 통합된 분석 결과를 생성하여 포괄적인 데이터 통찰력 제공.
-
실시간 분석 지원
- 실시간으로 수집되는 데이터(예: IoT 센서 데이터, 애플리케이션 로그)를 즉시 분석 가능.
- 빠른 데이터 처리로 조직의 신속한 의사 결정을 지원.
Azure Synapse Analytics의 장점
- 데이터 이동 최소화: 데이터 레이크와 데이터 웨어하우스 간 데이터 이동 없이 직접 쿼리.
- 효율성 향상: 데이터 웨어하우스의 정형 데이터와 데이터 레이크의 비정형 데이터를 한 번에 처리.
- 유연한 데이터 분석: 대규모 데이터를 실시간으로 처리하면서도 분석 정확도를 유지.
Azure Databricks: PREP/TRAIN 단계의 핵심 도구
Azure Databricks란?
Azure Databricks는 Apache Spark 기반의 빅데이터 분석 플랫폼으로, Microsoft Azure에서 제공하는 관리형 서비스입니다.
데이터 엔지니어, 데이터 과학자, 데이터 분석가들이 대규모 데이터를 빠르고 쉽게 처리하고 분석할 수 있는 환경을 제공합니다.
특히 PREP/TRAIN 단계에서 데이터 전처리와 머신러닝 모델 학습을 지원하는 강력한 도구로 활용됩니다.
- 단순 머신러닝 플랫폼이 아닌 애저 클라우드에 최적화 된 데이터 분석 시스템에 가깝습니다.
- 데이터의 처리/전처리 와 머신러닝에 관여한다.
- 다른 클라우드 제공자와 호환된다.
주요 기능
-
Apache Spark 기반
- 고성능 분산 처리 엔진 Apache Spark를 활용하여 대규모 데이터를 병렬로 처리.
- 클러스터를 자동으로 관리하고 최적화하여 복잡한 설정 없이 사용 가능.
-
통합 분석 환경
- Python, R, Scala, SQL을 지원하며, 다양한 분석 작업과 머신러닝 워크플로우를 쉽게 통합.
- 실시간 데이터 스트리밍 및 배치 작업을 모두 지원.
-
Azure 통합
- Azure Data Lake, Azure SQL Data Warehouse, Azure Blob Storage 등 Azure 서비스와 긴밀하게 통합.
- 데이터 파이프라인의 다양한 단계에서 데이터를 쉽게 처리하고 분석 가능.
-
협업 도구
- Notebook 기반의 인터페이스로 팀 간 협업이 용이.
- 데이터 시각화 및 분석 결과를 실시간으로 공유.
주요 활용 사례
-
데이터 처리 및 전처리
- 대규모 데이터의 정리, 클렌징, 변환 작업.
- 데이터 파이프라인에서 PREP 단계를 효율적으로 수행.
-
머신러닝
- 모델 학습 및 배포 워크플로우를 통합적으로 관리.
- Azure Databricks에서 머신러닝 모델을 직접 학습 및 평가 가능.
-
실시간 분석
- 스트리밍 데이터를 실시간으로 처리 및 분석하여 즉각적인 인사이트 제공.
- IoT 데이터, 애플리케이션 로그 등의 실시간 처리에 활용.
Azure Databricks의 장점
- 성능 최적화: Apache Spark 기반의 분산 처리로 대규모 데이터를 빠르게 분석.
- Azure 서비스와의 통합: 데이터 저장소 및 데이터 웨어하우스와 긴밀히 연결.
- 팀 협업 강화: Notebook 기반 환경으로 실시간 협업과 결과 공유 가능.
- 유연한 언어 지원: Python, R, Scala, SQL 등 다양한 언어로 분석 및 모델 학습 가능.
결론
Azure Databricks는 데이터 엔지니어링, 머신러닝, 빅데이터 분석의 핵심 도구로,
특히 PREP/TRAIN 단계에서 데이터 전처리와 모델 학습의 효율성을 극대화합니다.
Azure 통합 기능과 협업 도구를 통해 조직은 데이터를 효과적으로 관리하고 분석하여 더 나은 인사이트를 얻을 수 있습니다.
Azure HDInsight: 클라우드 기반 Hadoop 컴포넌트
Azure HDInsight란?
Azure HDInsight는 Microsoft Azure에서 제공하는 클라우드 기반 Hadoop 배포판으로, 대규모 데이터 처리를 위한 배치 처리와 분석 기능을 지원합니다.
Hadoop 생태계의 주요 구성 요소(Spark, Hive, HBase 등)를 통합하여 클라우드 환경에서 대규모 데이터를 효율적으로 처리할 수 있도록 설계되었습니다.
주요 기능
-
클라우드 기반 Hadoop 컴포넌트
- Hadoop 생태계 구성 요소(Spark, Hive, HBase 등)를 클라우드에서 제공.
- 온프레미스 시스템의 복잡성을 제거하고 확장성을 제공.
-
배치 처리 (Batch Processing)
- 대규모 데이터를 병렬로 처리하여 높은 성능 제공.
- 데이터 저장소에서 데이터를 가져와 배치 작업을 실행하고 분석에 필요한 결과를 생성.
-
분산 데이터 처리
- 분산 환경에서 데이터를 처리하여 대규모 데이터를 효율적으로 관리.
- 데이터 처리 속도와 확장성을 극대화.
-
통합 분석 및 보고
- SQL Data Warehouse, Spark, Hive와 같은 분석 도구와 통합.
- 분석 결과를 기반으로 보고서를 생성하여 의사결정 지원.
데이터 처리 흐름
-
Data Source (데이터 소스)
- 데이터의 원천: IoT, 로그 데이터, 데이터베이스 등 다양한 소스에서 데이터를 가져옴.
-
Data Storage (데이터 저장)
- 데이터를 Azure Blob Storage 또는 Data Lake Storage에 저장하여 처리 준비.
- 데이터 원본을 안전하게 저장하고 배치 처리의 입력값으로 사용.
-
Batch Processing (배치 처리)
- 병렬 처리를 통해 대규모 데이터를 효율적으로 처리.
- Spark, MapReduce와 같은 Hadoop 기반 도구를 사용.
-
Analytical Data Store (분석 데이터 저장소)
- 처리된 데이터를 SQL Data Warehouse, Spark, Hive와 같은 분석 스토리지에 저장.
- 고급 분석 및 보고에 필요한 데이터를 준비.
-
Analytics / Reporting (분석 및 보고)
- 저장된 데이터를 활용해 분석 및 보고서를 생성.
- 조직의 의사결정을 지원하는 인사이트 제공.
주요 활용 사례
- 로그 데이터 분석: 대규모 로그 데이터를 처리하고 분석하여 시스템 성능 최적화.
- IoT 데이터 처리: 센서 데이터를 수집, 저장, 분석하여 실시간 및 배치 인사이트 제공.
- 비즈니스 인텔리전스(BI): 배치 처리 결과를 SQL Data Warehouse로 통합하여 BI 도구와 연계.
Azure HDInsight의 장점
- 확장성: 클라우드 기반 환경에서 필요에 따라 용량을 확장 및 축소 가능.
- 비용 효율성: 온프레미스 Hadoop 시스템의 복잡성과 유지보수 비용 제거.
- 유연성: Spark, Hive, MapReduce 등 다양한 분석 도구 지원.
- 통합 분석 환경: Azure 서비스(SQL Data Warehouse, Data Lake)와 긴밀하게 연동.
Azure Stream Analytics: 실시간 데이터 분석 서비스
Azure Stream Analytics란?
Azure Stream Analytics는 Microsoft Azure에서 제공하는 실시간 데이터 분석 서비스로, 스트림 데이터(실시간 데이터)를 처리하고 분석하는 데 최적화된 플랫폼입니다.
IoT 장치, 애플리케이션 로그, 센서 데이터 등 실시간 데이터 스트림을 분석하여 빠른 의사결정을 지원합니다.
데이터 소스
Azure Stream Analytics는 다양한 데이터 소스와 통합하여 실시간 데이터를 처리할 수 있습니다:
1. Event Hub
- 대규모 이벤트 데이터를 실시간으로 수집.
- Azure Blob Storage
- Azure Blob Storage에서 저장된 데이터를 처리.
- IoT Hub
- IoT 장치에서 생성된 데이터를 수집하고 실시간으로 분석.
주요 기능
-
실시간 분석
- 데이터가 생성되는 즉시 스트림 데이터를 처리하여 분석 결과를 도출.
- 실시간 대시보드 업데이트 및 알림 시스템에 활용.
-
SQL 기반 스트림 처리
- SQL과 유사한 쿼리 언어를 사용해 데이터 필터링, 집계, 변환 작업을 쉽게 수행.
- 데이터 스트림에 복잡한 논리를 적용하여 비즈니스 규칙에 맞는 분석 가능.
-
통합 환경
- Azure Synapse Analytics, Power BI, Azure Blob Storage 등 다양한 Azure 서비스와 통합.
- 분석 결과를 저장하거나 시각화 도구로 연결 가능.
-
스케일 아웃
- 클라우드 기반 확장성을 통해 대규모 데이터 스트림도 손쉽게 처리 가능.
활용 사례
- IoT 데이터 분석
- IoT 장치에서 생성된 데이터를 실시간으로 처리하여 성능 모니터링 및 이상 탐지.
- 실시간 로그 분석
- 애플리케이션 로그를 분석하여 실시간 인사이트와 경고 생성.
- 실시간 대시보드 업데이트
- Power BI와 통합해 실시간 데이터 시각화를 지원.
- 사용자 행동 분석
- 웹 애플리케이션과 모바일 앱에서 사용자의 행동 데이터를 분석하여 즉각적인 피드백 제공.
Azure Stream Analytics의 장점
- 빠른 의사결정 지원: 데이터 생성 시점에 분석 결과를 제공하여 실시간 대응 가능.
- 사용 용이성: SQL 기반 쿼리 언어로 스트림 데이터를 간편히 처리.
- 확장성: 클라우드 확장성을 통해 데이터 볼륨 증가에도 안정적인 성능 유지.
- 비용 효율성: 사용한 만큼만 비용을 지불하는 Pay-as-you-go 모델.
결론
Azure Stream Analytics는 스트림 데이터를 실시간으로 처리하고 분석하여 빠른 의사결정과 비즈니스 대응을 가능하게 합니다.
IoT, 로그 분석, 사용자 행동 분석 등 다양한 실시간 데이터 활용 사례에 적합하며, Azure의 강력한 통합 생태계를 통해 분석 결과를 저장, 시각화, 또는 다른 애플리케이션에 전달할 수 있습니다.
Azure Data Factory: 코드 없이 데이터 파이프라인 구축
Azure Data Factory란?
Azure Data Factory는 Microsoft Azure에서 제공하는 클라우드 기반 데이터 통합 서비스로, 데이터를 복사, 변환, 통합하는 ETL(Extract, Transform, Load) 작업을 코드 없이 수행할 수 있도록 지원합니다.
사용하기 쉬운 인터페이스를 통해 데이터 파이프라인을 생성하고 관리하며, 데이터 소스 간 데이터 이동을 자동화할 수 있습니다.
주요 기능
-
데이터 복사 (Copy Data)
- 다양한 데이터 소스에서 데이터를 클라우드로 복사 및 동기화.
- 정말 수많은 소스로부터 데이터를 가져올수 있다.
- pipeline을 통해 데이터를 전송한다
- 단 전송 전에 Linked service를 생성해야 한다.
- Azure Blob Storage, Data Lake, SQL Database 등과 통합하여 데이터 이동 지원.
- 다양한 데이터 소스에서 데이터를 클라우드로 복사 및 동기화.
-
데이터 변환 (Transform Data)
- 데이터를 변환 및 처리하여 분석에 적합한 형태로 정제.
- Azure Synapse Analytics, Databricks와 같은 서비스와 연계 가능.
-
코드 없는 데이터 파이프라인 생성
- 코드 작성 없이 시각적 인터페이스를 통해 데이터 파이프라인을 설계.
- 드래그 앤 드롭 방식으로 간편하게 워크플로우를 생성.
-
간소화된 ETL 프로세스
- 복잡한 ETL 작업을 단순화하여 누구나 쉽게 데이터 파이프라인을 구현 가능.
- Easy UI: 사용자 친화적인 인터페이스 제공.
활용 사례
- 데이터 이동 자동화
- 데이터 소스 간 복잡한 데이터 이동 프로세스를 자동화하여 효율성 향상.
- 데이터 통합
- 온프레미스 및 클라우드 데이터 소스를 통합하여 중앙화된 데이터 환경 구축.
- 데이터 분석 준비
- 분석 및 머신러닝에 적합한 데이터 변환 및 전처리 수행.
- 일정 기반 데이터 처리
- 예약 작업을 통해 데이터 복사 및 변환 작업을 주기적으로 실행.
Azure Data Factory의 장점
- 코드 없이 간편한 데이터 파이프라인 생성: 개발자뿐만 아니라 비전문가도 쉽게 데이터 파이프라인을 설계 가능.
- 유연한 통합: 90개 이상의 데이터 소스 지원, 온프레미스 및 클라우드 환경에서 모두 사용 가능.
- 확장성: 대규모 데이터 처리도 안정적으로 수행하며, 클라우드 확장성을 제공.
- 비용 효율성: 사용한 만큼만 지불하는 Pay-as-you-go 모델로 비용 절감.
Power BI: 데이터 시각화 및 보고 도구
1. Power BI의 주요 구성 요소
Power BI는 데이터를 시각적으로 표현하고 분석하여 비즈니스 인텔리전스(BI)를 지원하는 도구입니다.
구성 요소
- Visualization (시각화): 데이터를 차트, 그래프, 지도 등으로 표현.
- Dataset (데이터셋): 저장된 데이터에 대한 데이터의 구조를 표현함
- Dashboard (대시보드): 여러 시각화를 통합하여 데이터를 요약적으로 제공.
2. Power BI의 주요 기능
-
데이터 연결 및 모델링
- 다양한 데이터 소스(클라우드, 데이터베이스, 파일)와 연결.
- 데이터를 정리하고 분석에 적합한 형태로 변환.
-
시각화 및 보고서 작성
- 차트와 그래프를 활용해 데이터를 시각적으로 표현.
- 데이터를 요약하여 보고서를 작성.
-
실시간 대시보드
- 실시간 데이터를 표시하여 비즈니스 성과를 직관적으로 모니터링.
3. Power BI의 장점과 결론
주요 장점
- 사용자 친화적 인터페이스: 코드 없이도 데이터 분석과 시각화 가능.
- 강력한 통합: Microsoft 365 및 다양한 데이터 소스와 연결.
- 실시간 분석: 데이터를 실시간으로 모니터링하고 대시보드에 반영.
결론
Power BI는 데이터를 시각화하고 분석하는 강력한 도구로, 조직이 데이터 기반 의사결정을 가속화하도록 지원합니다. 직관적인 UI와 다양한 시각화 옵션으로 비즈니스 인텔리전스를 효율적으로 제공합니다.
오답노트
데이터 저장 및 처리
데이터베이스 유형 및 특징
-
Cosmos DB
- 무제한 데이터베이스 생성 가능.
- IP 주소 기반 접속 제한 및 Authorization Token 사용.
- 지원 API: Cassandra, MongoDB, Gremlin, NoSQL, Table API.
- 1RU/s는 1KB 문서를 읽는 데 필요한 리소스.
- 컨테이너 최소 설정은 400 RU/s.
- 설정한 RU 보다 많은 요청이 들어오면 재시도하라고 알려준다.
- Azure Table Storage 대비 짧은 지연 시간(한자리 ms).
-
SQL Database
- SQL 쿼리를 통해 데이터 저장 및 조회 가능.
- Dynamic Data Masking으로 민감 정보 숨김.
- Azure AD를 통한 SSO 지원.
- Manual Sharding: 데이터베이스를 수동으로 분할하여 스케일 관리 가능.
- MS365 구독은 필요 없다.
-
Azure Table Storage
- Key-Value 스토리지 타입.
- 5PB 용량 제한.
- Cosmos DB 대비 비용 효율적.
-
CORE SQL
- BSON 을 쓰는 MongoDB와 다르게 JSON에 최적화 되어 있다.
-
Blob Storage
- Premium Tier: 빠른 접근 및 낮은 지연 시간 제공.
- 데이터 보호:
- Soft Delete: 삭제된 데이터를 복구 가능.
- Blob 버전 관리: 모든 변경 사항 기록.
-
Azure File Share
- Standard는 HDD 사용, Premium은 SSD 사용.
데이터 처리 및 분석
-
ELT / ETL
- ELT: 데이터를 먼저 데이터 웨어하우스에 로드한 후 처리.
- ETL: 데이터를 로드하기 전에 변환.
-
Azure Data Factory
- 외부 데이터 가져오기 및 장소 간 데이터 이동에 유용.
- Control Flow: If Condition, Filtering 등 포함.
- Pipeline: 작업 그룹화로 효율적 처리.
-
Azure Databricks
- Apache Spark 기반 협업 플랫폼.
-
Azure Synapse Analytics
- SQL Engine 기반으로 데이터 분석에 적합.
-
Azure HDInsight
- Apache Spark 환경에서 대규모 데이터 처리.
데이터 보안
데이터 암호화
-
Azure Storage Account
- Secure Transfer Required: 양방향 암호화 구현.
-
Transparent Data Encryption (TDE)
- 저장 데이터(Data-at-rest)를 자동 암호화.
- SQL 데이터베이스에서 기본 활성화.
-
Always Encrypted
- 데이터가 종단간 암호화 되는것을 보장한다.
-
Azure Data Encryption
- 저장 중인 데이터 암호화.
네트워크 보안
-
Firewall 관리
- Server-level Firewall: 모든 데이터베이스에 대한 접근 제어.
- Database-level Firewall: 특정 데이터베이스에 대한 접근 제어.
- 동시 적용 시 Database-level Firewall이 우선.
-
Zero Trust Model
- 모든 요청을 신뢰하지 않고 이미 해킹당한 것으로 가정.
-
Just In Time (JIT) Access
- 필요한 순간 최소 시간 동안 권한 부여.
-
Site to Site VPN
- 안전한 데이터 전송 보호.]
-
Azure AD 관리자 계정
- 데이터베이스에 항상 연결할수 있다
비용 관리 및 최적화
-
Redis Cache
- 리전, 티어, 사용 시간에 따라 비용 결정.
-
비용 구조
- Per Day Operational Expenditure (PDEX): 매일 지출 비용.
- Upfront Expenditure: 초기 비용.
- PaaS DB: Upfront 비용 없음.
대시보드 및 시각화
-
Power BI
- 데이터 대시보드 구현.
-
데이터 시각화 도구
- Chart: 다양한 차트 유형.
- TreeMap: 데이터 계층 구조 시각화.
- Matrix: 표 형식 데이터 정리.
- Paginated Report: 대량 데이터 보고에 효과적.
기타 특징 및 관리
-
Azure Data Lake Gen2
- 비정형 데이터 저장에 적합.
- HDFS 파일 시스템 사용.
- Lifecycle Management Policy로 Cool 또는 Archive 계층 이동 가능.
-
마이그레이션
- IaaS 기반 VM 사용 시 코드와 환경 유지 가능.
-
Powershell 및 CLI
- Non-Relational DB에서 스크립트 작성에 사용.
Azure Data studio
- 인텔리센스, 스니펫, CI, 터미널을 지원하는 SQL 서버 쿼리 툴
데이터 시각화
- 시간 경과에 따른 추세 및 패턴 표시
- 데이터의 중요성 전달
Database administrator
- 인덱스 성능 문제 해결
- 데이터베이스 권한 정리
- 데이터베이스 백업
Database Engineer
- 데이터 모니터링
Archive tier
- 데이터를 수정할수 있긴 하다.
Window VM위 SQL SERVER
- 정말 모든 기능을 지원한다
POSTGRESQL
- 오픈소스 하이브리드 RDB
MariaDB
- 오픈소스 시계열 DB
Azure data explorer
- 텍스트 로그, 웹사이트, Iot기기들로부터 쿼리를 통해 큰 데이터를 가져와 분석한다.
Power BI Desktop
- Analytical model을 정의하는데 사용한다.
UPDATE/MERGE
- DML에서 테이블의 데이터를 변경하는것
데이터 정규화
- 업데이트 최적화 및 용량 줄어듦
Azure Delta Lake
- 트랜잭션 일관성 유지
Scatterplot
- 두 숫자 값들의 관계를 시각화
Aggregate JSON
- JSON 모으는건 무조건! COSMOS DB!!
Batch Processing
- RDB/NoSQL 에 데이터를 바로 보낼수 없다.
CRM System (Customer Relationship Management)
CRM 시스템은 고객 데이터를 관리하고 판매, 마케팅, 고객 지원을 효율화해 고객 관계를 강화하는 소프트웨어입니다.
- Data Extraction 에 사용
Paas DB를 실질적으로 사용자가 일시정지할 방법은 없다.
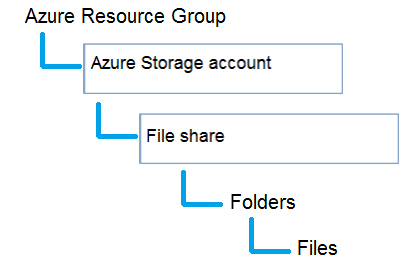
Azure Table storage 만들기
- az storage account create
View 에 Column 추가하기
- ALTER
Organization Chart에 좋은것
- Graph Database
Data Lake GEN2 는 Stream Processing 이후 결과를 파일로 저장 가능
